
2024–2025 годы стали переломными для индустрии машинного обучения. Нейросети окончательно вышли за пределы исследовательских лабораторий и стали частью повседневных продуктов: от генерации текста и изображений до обработки документов, речи и видео. Для разработчиков это означало одно — нейросети стали таким же инструментом, как базы данных или очереди сообщений, и всё чаще заказчики ожидают их наличия в своих проектах.
В этот момент многие команды оказались на развилке. С одной стороны — облачные API: OpenAI (ChatGPT), Anthropic (Claude), DeepSeek и десятки похожих сервисов. Они позволяют подключить мощную модель буквально за несколько минут и сразу получить результат, который ещё пару лет назад казался недостижимым. С другой стороны — локальные модели, которые можно развернуть на собственных серверах и полностью контролировать процесс обработки данных.
Серверы с видеокартами NVIDIA — от доступных моделей начального уровня до профессиональных Tesla, в дата-центрах в России и Европе.
При длительной аренде — скидка до 35 %.
У обоих подходов есть свои сильные и слабые стороны.
Облачные нейросети
Плюсы:
-
быстрая интеграция в любой проект;
-
минимум инфраструктурных забот;
-
стабильно высокое качество моделей.
Минусы:
-
данные компании отправляются на сторонние серверы (что критично для корпоративного сектора, финтеха и госструктур);
-
высокая стоимость при масштабировании — многие проекты с активным использованием API столкнулись с тем, что счета за inference растут быстрее бизнеса.
Локальные нейросети
Плюсы:
-
данные остаются внутри собственного контура;
-
предсказуемая экономика — вы платите только за железо и электричество;
-
полный контроль над моделями и пайплайнами.
Минусы:
-
необходимость инфраструктуры;
-
порог входа выше, чем у облачных решений.
Из названия статьи уже понятно, что дальше мы будем говорить именно о локальных нейросетях. Причём не в теории, а на практике — с реальным кодом и реальным сервером.
Основных возражений против локального подхода обычно два: «это дорого» и «это сложно поднимать». В рамках этой статьи я постараюсь оба тезиса аккуратно разобрать.
Во-первых, инфраструктура. Сегодня я покажу, как развернуть полноценный мультимодальный ML-сервис из четырёх нейросетей на видеокарте с 16 ГБ видеопамяти. Аренда такого сервера обойдётся примерно в 12 000 рублей в месяц, что уже сравнимо с затратами на облачные API при умеренной нагрузке.
Во-вторых, сложность. Если вы Python-разработчик и уже сталкивались с ML-инструментами, то знаете: запуск даже моделей уровня GPT-4-класса сегодня часто сводится к одной-двум командам благодаря таким инструментам, как vLLM или Ollama.
Метод, который мы будем использовать в этой статье, чуть сложнее «одной кнопки», но зато даёт больше гибкости и контроля. Следуя шаг за шагом, вы сможете запускать практически любые современные модели на относительно доступном железе и собирать из них рабочие продакшн-сервисы.
Что собираем в итоге
Теперь — к сути статьи. На большом практическом примере я хочу показать, что при работе с локальными нейросетями возможна полноценная кастомизация и сборка сложных ML-пайплайнов без вмешательства во внутреннее устройство моделей. Нам не понадобится дообучение, fine-tuning или «копание в мозге» нейронок — достаточно правильно собрать их в единый сервис.
Параллельно я хочу продемонстрировать ещё одну важную мысль: 16 ГБ видеопамяти сегодня — это не «ни о чём», а вполне рабочий минимум, на котором можно запустить полноценное мультимодальное приложение без обращения к облачным API.
В рамках статьи мы шаг за шагом сделаем следующее:
-
Купим доменное имя и позже привяжем его к сервису.
-
Выполним базовую настройку сервера под ML‑задачи.
-
Напишем FastAPI‑приложение, которое будет выступать оболочкой над локальными нейросетями, загруженными через PyTorch и Hugging Face Transformers.
-
Запустим сервис в режиме постоянной работы с помощью
systemd. -
Опубликуем приложение наружу и настроим доступ по доменному имени.
Инфраструктура
GPU-сервер мы будем арендовать у провайдера Hostkey. Причина выбора простая: на момент написания статьи у них можно найти один из самых доступных вариантов с GPU такого уровня.
Используемая конфигурация:
-
VPS
-
8 vCPU
-
32 ГБ RAM
-
240 ГБ SSD
-
GPU: RTX A4000 (16 ГБ VRAM)
Стоимость — около 12 000 рублей в месяц (актуальная цена, которая была на конец 2025 года), что делает такой сетап разумной альтернативой облачным ML-API при постоянной нагрузке.
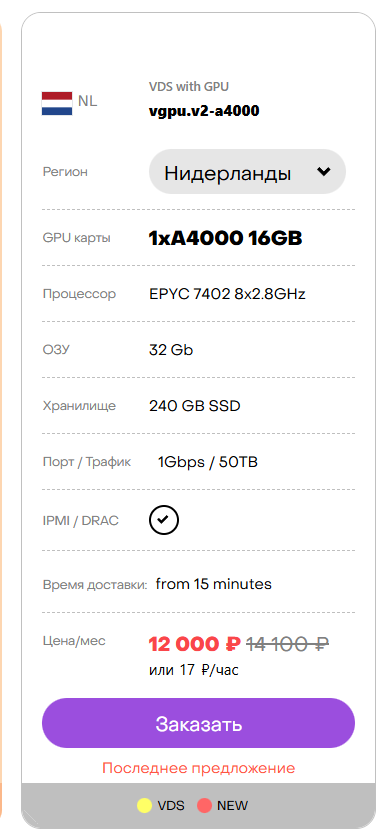
Конфигурация на которой будет развернут проект.
Какие нейросети будем поднимать
В качестве примера мы соберём мультимодальный пайплайн из четырёх моделей, каждая из которых решает свою конкретную задачу:
-
DeepSeek OCR — извлечение текста из изображений и PDF (компьютерное зрение);
-
Whisper Large v3 (RU) — распознавание русской речи из аудио с преобразованием в текст;
-
Qwen2.5-3B — LLM‑модель‑«говорун», которую будем использовать:
-
как чат‑модель;
-
как инструмент нормализации и постобработки текста, полученного от OCR и ASR;
-
-
MMS‑TTS (RU) — озвучивание русского текста.
В результате получится следующий логический пайплайн:
OCR → ASR → LLM → TTS
Такой подход позволяет принимать на вход изображения, PDF или аудио, приводить данные к аккуратному текстовому виду, при необходимости обрабатывать их через LLM и возвращать результат в виде озвученного ответа.
Основной технический стек
Вся реализация будет выполнена на Python. Глубоких знаний машинного обучения не потребуется, но базовое понимание Python и серверной разработки будет полезно.
Ключевые библиотеки:
-
FastAPI — HTTP‑оболочка сервиса;
-
torch — базовый фреймворк для работы с моделями;
-
transformers — загрузка и управление нейросетями из экосистемы Hugging Face.
Этот стек позволяет держать код компактным, управлять памятью и dtype моделей, а также без лишних зависимостей собрать продакшн-готовый ML-сервис.
В следующем разделе мы переходим от теории к практике и начнём с самого основания — настройки инфраструктуры и сервера под GPU.
Подготовка инфраструктуры
Прежде чем переходить к коду и нейросетям, нам нужно подготовить базовую инфраструктуру: арендовать сервер с GPU, купить доменное имя и настроить окружение для разработки.
Аренда VPS с GPU
Для примера будем использовать провайдера Hostkey, но общая логика подойдёт для любого хостинга с GPU.
Порядок действий следующий:
-
Регистрируемся в Hostkey (если аккаунта ещё нет).
-
Заходим в личный кабинет.
-
Переходим в раздел «Новый сервер».
-
Выбираем «Серверы с GPU».
-
Подбираем сервер с минимум 16 ГБ видеопамяти.
В качестве операционной системы рекомендую Ubuntu 24.04 — на ней выполнялись все тесты проекта. -
Арендуем сервер. У Hostkey доступна почасовая оплата, что удобно для тестов и экспериментов.
После оплаты на почту придёт письмо с данными для доступа:
-
IP-адрес сервера;
-
имя пользователя;
-
пароль.
Сразу копируем IP-адрес сервера. Он нам будет нужен на следующем этапе.
Покупка доменного имени
Домен можно купить у любого регистратора — принципиальной разницы нет. Важно лишь одно: после покупки зайти в DNS-настройки и добавить A-запись, указывающую на IP-адрес вашего сервера.
Это понадобится позже, когда мы будем публиковать FastAPI-приложение наружу.
Показываю пример покупки через сервер reg.ru (регистратор доменных имен может быть любым, принципиальной разницы нет).
-
Регистрируемся на сайте регистратора
-
Заходим в меню покупки доменных имен. Первое, что нас интересует - это проверка того, что доменное имя свободно. Проверка доступности домена: https://www.reg.ru/buy/domains/

-
Если имя свободно - можно переходить к покупке. Убираем все доп услуги. Нам нужен только домен!
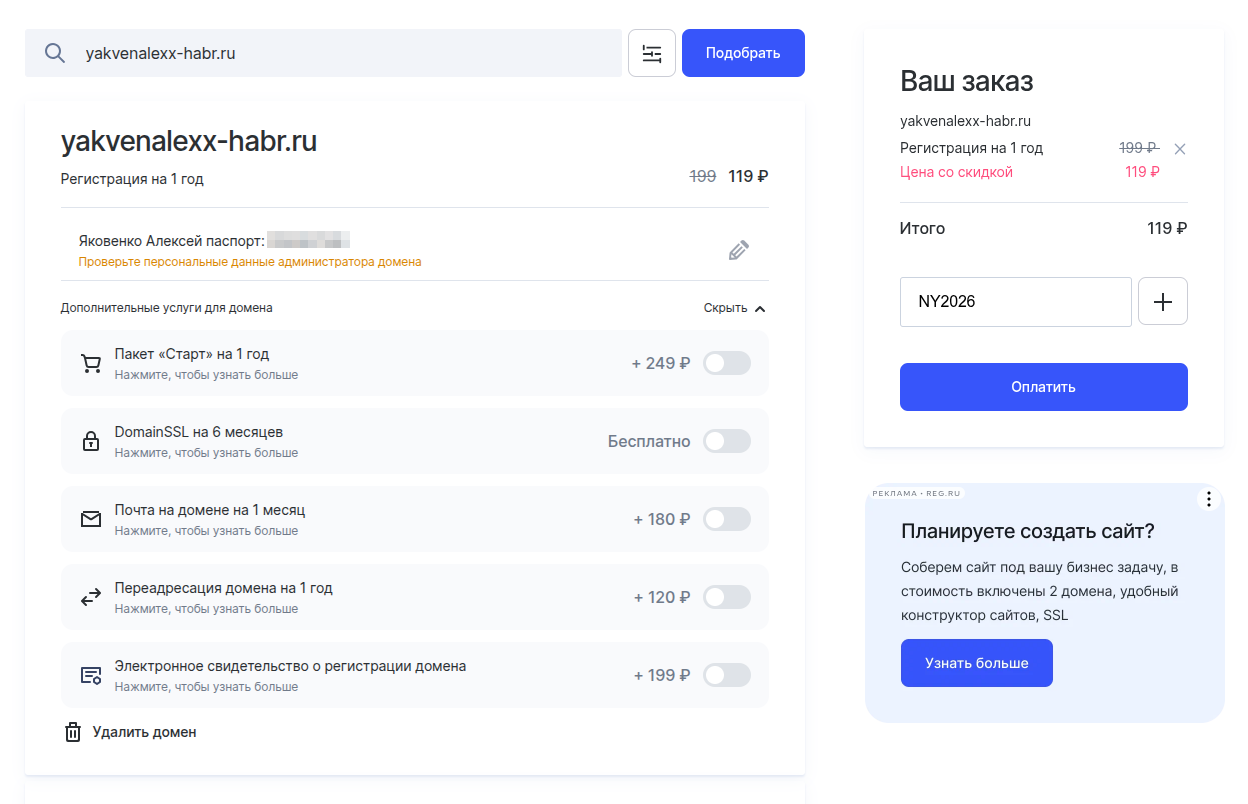
На момент написания статьи работал промокод NY2026, который позволял в REG.RU купить домен за 1 рубль на год. Проверьте, может ещё работает.
-
Далее убедитесь, что в настройках домена указаны DNS-серверы
ns1.reg.ruиns2.reg.ru. Эти серверы REG.RU позволяют гибко привязать свой собственный IP-адрес сервера, без привязки к стороннему хостингу.
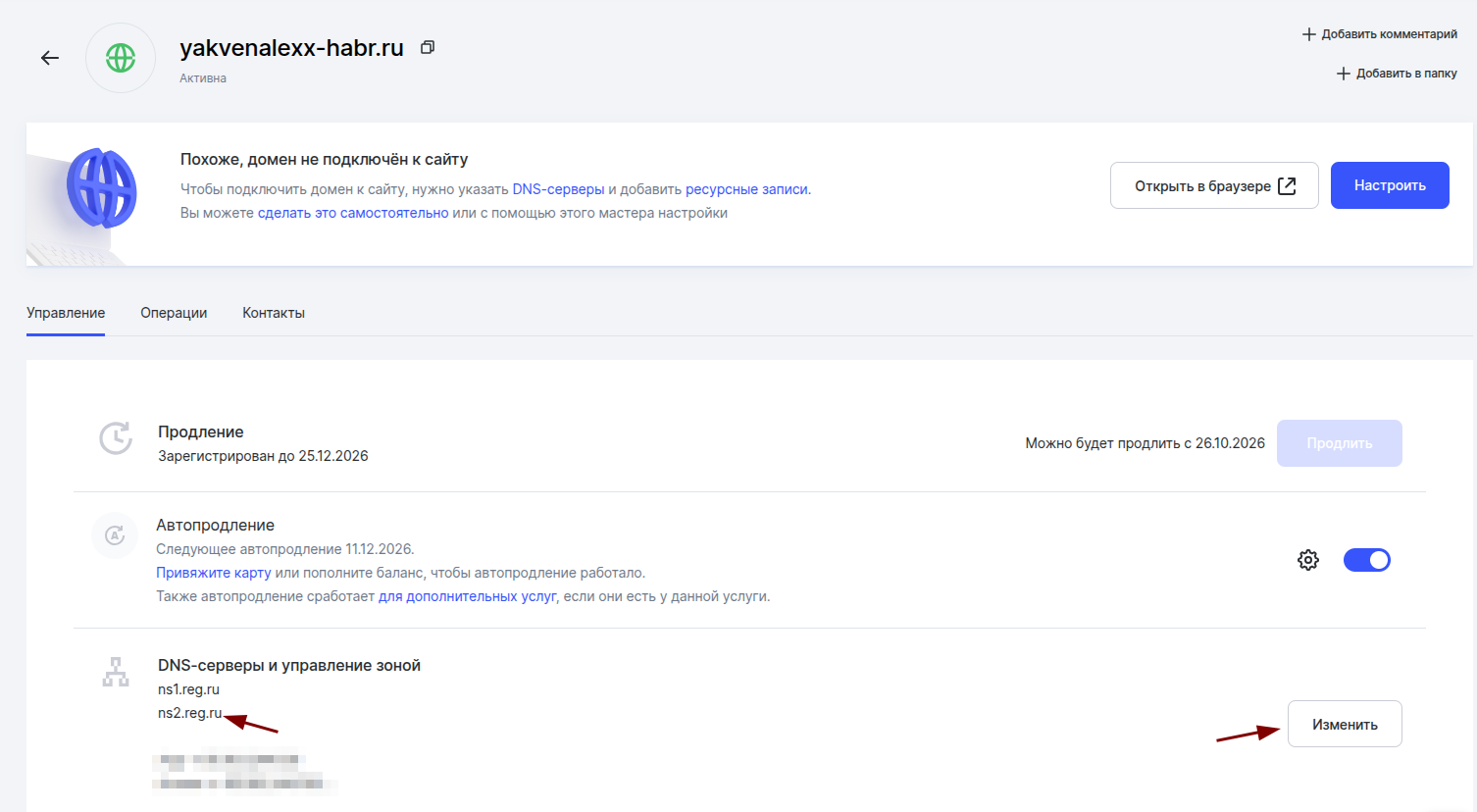
Для редактирования кликаем на "изменить"
-
Далее добавляем А записи. Сделал отдельную A-запись для доступа к домену через www.
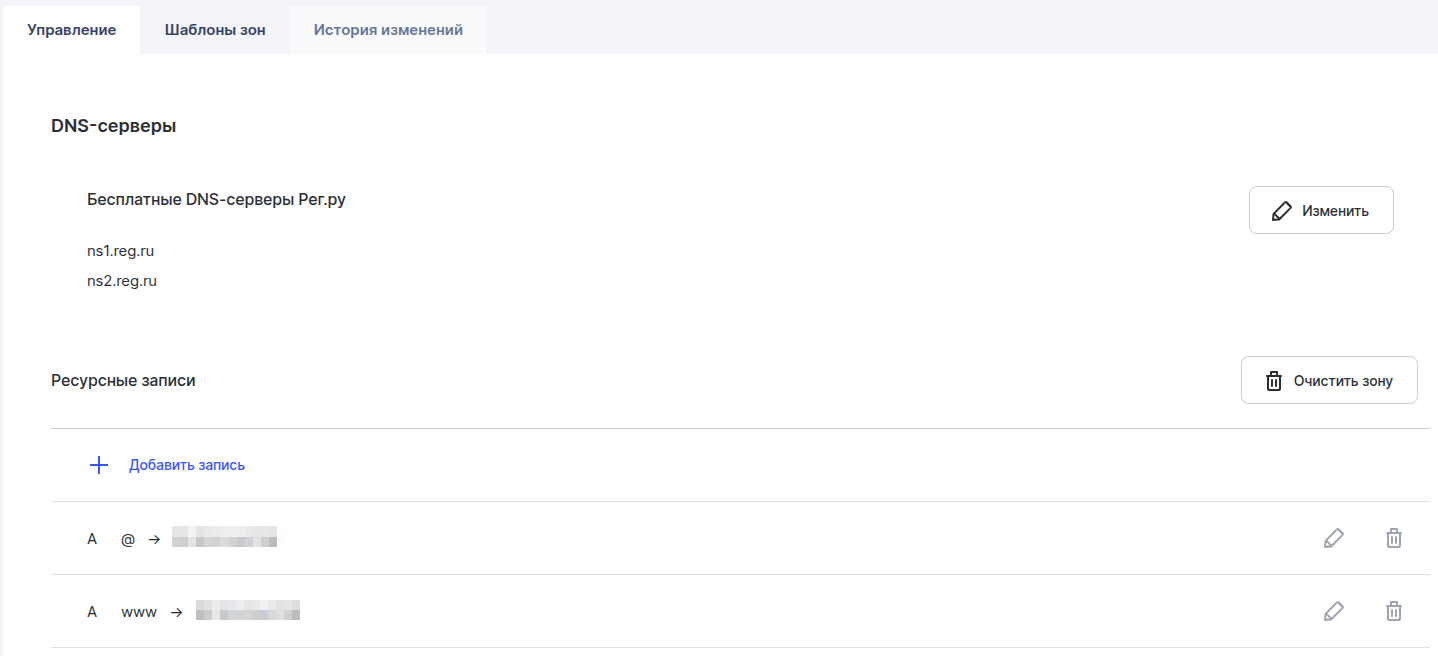
После создания А-записей ждем 15-30 минут и можно настраивать Nginx на сервере (займемся этим немного позже)
Первичная настройка сервера
Отложим пока купленный домен и перейдём к подготовке сервера для разработки. На этом этапе подключимся к серверу по SSH, обновим пакеты, установим необходимый софт, драйверы и полностью подготовим систему к запуску FastAPI-проекта с четырьмя локальными нейросетями под капотом.
Подключаемся к серверу по SSH:
ssh root@IP_ADDRESSВводим пароль из письма.
Обновляем систему и ставим базовые зависимости:
sudo apt update && sudo apt install -y \
nginx \
certbot \
python3 \
python3-pip \
python3-venv \
python3-certbot-nginxУстановка NVIDIA-драйверов
Устанавливаем рекомендованные драйверы:
sudo ubuntu-drivers autoinstallПосле установки обязательно перезагружаем сервер:
sudo rebootПосле перезагрузки снова подключаемся по SSH и проверяем, что GPU корректно определяется системой:
nvidia-smi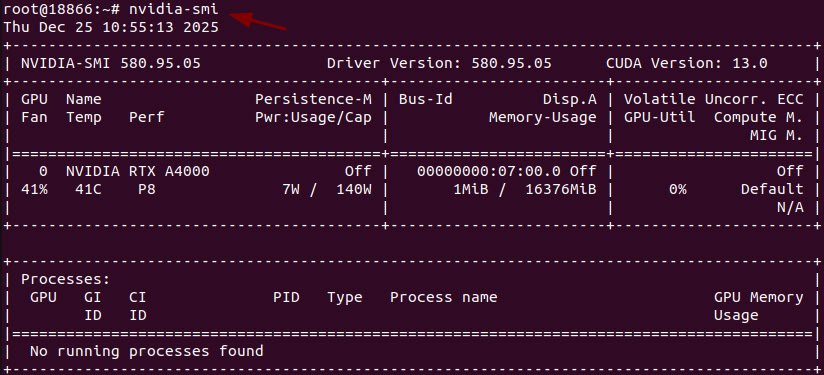
Если видеокарта отображается — можно двигаться дальше.
Подготовка проекта и виртуального окружения
Создадим директорию под будущий проект, например в /home:
cd /home
mkdir project_name
cd project_name
Создаём виртуальное окружение и активируем его для теста:
python3 -m venv .venv
source .venv/bin/activate
Если окружение активировалось корректно — база для разработки готова.
Удобный SSH-доступ без пароля
Прежде чем мы нырнём в код, настроим удобный вход на VPS без постоянного ввода пароля. Это сильно упростит жизнь на следующих этапах — особенно когда поделюсь лайфхаком написания кода прямо на сервере, если локального железа нет под рукой.
Linux / macOS
# Настройки (замените на свои)
ALIAS_NAME=myserver
HOST=1.222.33.44
PORT=22
USER=username
# Создаём папку для ключей и генерируем ключ
mkdir -p "$HOME/.ssh/project_keys/$ALIAS_NAME" && \
ssh-keygen -t ed25519 -f "$HOME/.ssh/project_keys/$ALIAS_NAME/id_ed25519"
# Копируем публичный ключ на сервер
ssh-copy-id -i "$HOME/.ssh/project_keys/$ALIAS_NAME/id_ed25519.pub" -p "$PORT" "$USER@$HOST"
# Добавляем алиас в ~/.ssh/config
KEY_PATH="$HOME/.ssh/project_keys/$ALIAS_NAME/id_ed25519"
cat >> "$HOME/.ssh/config" <<EOF
Host $ALIAS_NAME
HostName $HOST
Port $PORT
User $USER
IdentityFile $KEY_PATH
RemoteCommand sudo -i
RequestTTY yes
EOF
chmod 600 "$HOME/.ssh/config"Windows (PowerShell)
$ALIAS_NAME = "myserver"
$HOST = "1.222.33.44"
$PORT = "22"
$USER = "username"
# Создаём папку и генерируем ключ
New-Item -ItemType Directory -Force -Path "$env:USERPROFILE\.ssh\project_keys\$ALIAS_NAME" | Out-Null
ssh-keygen -t ed25519 -f "$env:USERPROFILE\.ssh\project_keys\$ALIAS_NAME\id_ed25519"
# Копируем ключ вручную
type "$env:USERPROFILE\.ssh\project_keys\$ALIAS_NAME\id_ed25519.pub" |
ssh -p $PORT "$USER@$HOST" "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
# Добавляем алиас в config
$KEY_PATH = "$env:USERPROFILE\.ssh\project_keys\$ALIAS_NAME\id_ed25519"
@"
Host $ALIAS_NAME
HostName $HOST
Port $PORT
User $USER
IdentityFile $KEY_PATH
RemoteCommand sudo -i
RequestTTY yes
"@ | Add-Content "$env:USERPROFILE\.ssh\config"Готово! Теперь подключайтесь одной командой:
ssh myserverИнфраструктура готова. Дальше — подключение VS Code к серверу, открытие папки проекта и самое вкусное — разработка FastAPI-оболочки с четырьмя локальными нейросетями.
Как вести разработку без мощного локального железа
Даже если в статье мы используем GPU с 16 ГБ видеопамяти, на практике далеко не у каждого разработчика есть такое железо под рукой. А что говорить о более тяжёлых конфигурациях?
Вести разработку напрямую на сервере через SSH — неудобно. Но есть простой и очень эффективный лайфхак.
VS Code + Remote SSH
Решение — расширение Remote SSH для VS Code. Оно позволяет работать с кодом на удалённом сервере так, будто проект находится локально.
Как это работает
-
VS Code устанавливает на сервер небольшой server‑агент.
-
Все операции (терминал, git, запуск скриптов, линтеры) выполняются на VPS.
-
В локальном VS Code вы просто редактируете файлы и управляете проектом.
Что нужно сделать
-
Установить расширение Remote — SSH (
ms-vscode-remote.remote-ssh). -
Убедиться, что SSH‑доступ к серверу без пароля работает:
ssh myserver -
В VS Code нажать
F1→Remote-SSH: Connect to Host...→ выбрать подготовленный ранее сервер (myserver).
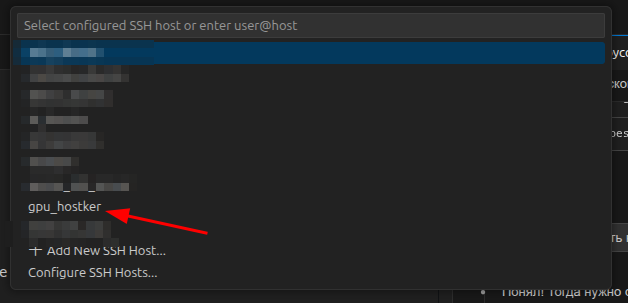
После подключения выбрать папку проекта на сервере в которой уже установлено виртуальное окружение — она откроется как обычный workspace.
Переходим в папку
Дисклеймер перед разработкой
Сразу небольшой дисклеймер. В проекте получилось достаточно много кода. Как это обычно бывает: начинаешь с «пары эндпоинтов», а дальше архитектура постепенно обрастает вспомогательными модулями, обработкой ошибок, управлением памятью и прочими необходимыми вещами.
В рамках статьи я не буду разбирать каждую строчку кода. Вместо этого мы сосредоточимся на ключевых и нетривиальных моментах:
-
архитектуре приложения;
-
загрузке и инициализации моделей;
-
управлении GPU-памятью;
-
интеграции PyTorch + Transformers с FastAPI.
Полный исходный код проекта выложен в открытом доступе GitHub: https://github.com/Yakvenalex/FastAPIAIModelsProject
Для удобства изучения дальнейшей информации - советую сразу клонировать проект себе и открыть его в IDE в котором вы привыкли работать:
git clone https://github.com/Yakvenalex/FastAPIAIModelsProjectЕсли по ходу чтения появятся вопросы или захочется обсудить реализацию с другими разработчиками, приглашаю в мой Telegram-канал «Лёгкий путь в Python». Там я публикую дополнительные материалы, исходники учебных проектов и разбираю практические кейсы. На момент написания статьи сообщество насчитывает более 5000 участников.
Приступаем к разработке
Предполагаю, что к этому моменту у вас:
-
уже арендован VPS с GPU;
-
установлен NVIDIA-драйвер;
-
настроен удобный доступ по SSH;
-
VS Code подключён к серверу через Remote SSH.
Теперь можно переходить к разработке самого сервиса.
Общая архитектура проекта
На высоком уровне архитектура выглядит следующим образом:
-
FastAPI выступает в роли HTTP‑оболочки;
-
каждая нейросеть инкапсулирована в отдельный модуль;
-
модели загружаются через PyTorch + Transformers;
-
отдельный менеджер управляет GPU‑памятью и жизненным циклом моделей.
Базовые файлы в корне проекта
В корне проекта создаём два важных файла:
.env
Файл с переменными окружения (пути к кешам, настройки памяти, параметры запуска). Мы будем использовать его для конфигурации сервиса без хардкода значений.
requirements.txt
Список зависимостей проекта:
# FastAPI и веб-сервер
fastapi==0.115.5
uvicorn[standard]==0.34.0
python-multipart==0.0.18
# PyTorch и Transformers
torch==2.5.1
torchvision==0.20.1
transformers==4.47.1
accelerate==1.2.1
bitsandbytes==0.45.0
# Работа с изображениями и PDF
Pillow==11.0.0
pdf2image==1.17.0
pypdf==5.1.0
# Работа с аудио
librosa==0.10.2.post1
soundfile==0.12.1
scipy==1.14.1
# Дополнительные утилиты
python-dotenv==1.0.1
pydantic==2.10.3
pydantic-settings==2.6.1
addict==2.4.0
einops==0.8.1
easydict==1.13
protobuf==5.29.2
sentencepiece==0.2.0Большинство этих библиотек используются напрямую или косвенно самими моделями. Особенно это касается:
-
accelerateиbitsandbytes— для управления памятью и квантизацией; -
sentencepieceиprotobuf— для корректной загрузки токенизаторов; -
библиотек для работы с аудио и изображениями, которые требуются OCR и ASR моделям.
Кеши моделей
В корне проекта автоматически будут созданы две директории:
-
models_cache— кеш загруженных моделей; -
offload_cache— временное хранилище для offload‑операций.
Мы вернёмся к ним позже, когда будем говорить об оптимизации использования GPU-памяти.
Структура папки app
Основная логика приложения лежит в папке app:
app/
├── models/
├── routers/
├── utils.py
├── memory_manager.py
├── config.py
└── main.pyКратко по назначению:
-
models/
Файлы, отвечающие за загрузку и конфигурацию конкретных нейросетей. -
routers/
FastAPI‑роутеры.
Один файл — один логический раздел API (OCR, ASR, LLM, TTS). -
utils.py
Вспомогательные функции, используемые в разных частях приложения. -
memory_manager.py
Менеджер памяти — ключевой компонент всей архитектуры.
Он отвечает за:-
загрузку и выгрузку моделей;
-
контроль использования GPU;
-
предотвращение OOM‑ошибок.
Этому модулю мы посвятим отдельный раздел статьи.
-
-
config.py
Централизованные конфигурации приложения. -
main.py
Точка входа. Здесь происходит сборка FastAPI‑приложения, подключение роутеров и инициализация сервисов.
Структура проекта может отличаться — это не догма. Важно лишь понять общий принцип связки FastAPI → PyTorch → Transformers и подход к организации кода.
На этом подготовительная часть завершена. Дальше мы начнём разбирать работу ключевых модулей приложения, начиная с архитектуры FastAPI и инициализации моделей.
Далее — как именно мы загружаем и держим несколько нейросетей в GPU-памяти, не убивая сервер.
Архитектура сервиса: как FastAPI управляет нейросетями
Прежде чем говорить об управлении памятью, важно понять как вообще устроен сервис и какую роль в нём играет FastAPI. Без этого дальнейшие оптимизации будут выглядеть как набор разрозненных костылей.
Общая концепция
В основе проекта лежит FastAPI — асинхронный веб-фреймворк, который в данном случае выступает не ML-инструментом, а оркестратором.
FastAPI:
-
принимает HTTP-запросы от клиентов;
-
маршрутизирует их к нужной нейросети;
-
управляет жизненным циклом моделей;
-
возвращает структурированный JSON-ответ.
Сами нейросети изолированы от веб-слоя и работают как независимые вычислительные компоненты.
Клиент (HTTP / JSON)
│
▼
┌─────────────────────────────┐
│ FastAPI │
│ ┌───────────────────────┐ │
│ │ Routers (/ocr /asr…) │ │
│ └──────────┬────────────┘ │
│ ▼ │
│ Model Managers │
│ (lazy load + caching) │
└──────────┬───────────┬─────┘
│ │
┌────▼───┐ ┌────▼────┐
│ GPU │ │ CPU RAM │
│ 16 GB │ │ 32 GB │
└────┬───┘ └────┬────┘
│ │
┌────▼─────────────────┐
│ AI Models │
│ DeepSeek / Whisper │
│ MMS / Qwen │
└──────────────────────┘Модульная архитектура и разделение ответственности
Проект организован по принципам Clean Architecture — каждый слой отвечает только за свою зону ответственности.
app/
├── main.py # Точка входа FastAPI
├── config.py # Конфигурация
├── routers/ # HTTP API слой
│ ├── ocr.py
│ ├── asr.py
│ ├── tts.py
│ └── chat.py
├── models/ # Обертки над AI-моделями
│ ├── base.py
│ ├── deepseek_ocr.py
│ ├── whisper_asr.py
│ ├── mms_tts.py
│ └── qwen_chat.py
└── utils.py # Утилиты и вспомогательная логикаТакое разделение позволяет:
-
менять модели без переписывания API;
-
тестировать слои независимо;
-
масштабировать проект без архитектурного рефакторинга.
Слой 1: Routers — HTTP API Gateway
Роутеры — это тонкий HTTP-слой, который не знает, как работает модель, а знает только что нужно сделать.
Задачи роутеров:
-
валидация входных данных;
-
получение модели через менеджер;
-
запуск инференса;
-
формирование ответа.
Пример OCR-эндпоинта:
@router.post("/extract-text")
async def extract_text(
file: UploadFile = File(...),
normalize: bool = False
):
# Валидация
if file.content_type not in allowed_types:
raise HTTPException(400, "Неверный тип файла")
model = get_ocr_model()
# Инференс в отдельном потоке
text = await asyncio.to_thread(model.predict, file_data)
# Опциональная нормализация через LLM
if normalize:
text = await normalize_with_llm(text)
return {"text": text, "status": "success"}Ключевые особенности:
-
async def— FastAPI не блокирует event loop; -
тяжёлые операции выполняются через
asyncio.to_thread; -
всегда возвращается предсказуемый JSON.
Слой 2: Model Managers — умные прокси к AI
Model Manager — это прослойка между роутером и моделью, отвечающая за её жизненный цикл.
Используется паттерн Singleton — каждая модель существует в одном экземпляре.
ocr_model: DeepSeekOCR = None
def get_ocr_model() -> DeepSeekOCR:
global ocr_model
if ocr_model is None:
ocr_model = DeepSeekOCR(...)
return ocr_modelПочему это важно:
-
загрузка модели занимает 5–20 секунд;
-
потребляет 5–10 GB памяти;
-
создавать новый экземпляр на каждый запрос — катастрофа.
Жизненный цикл модели
-
Первый запрос к эндпоинту.
-
Менеджер создаёт объект модели.
-
Проверяет: загружена ли она в память.
-
При необходимости — загружает с учётом лимитов.
-
Обновляет
last_used. -
Повторные запросы выполняются мгновенно.
-
После простоя модель автоматически выгружается.
Слой 3: Model Wrappers — единый интерфейс для всех моделей
Все модели наследуются от базового класса:
class BaseModel(ABC):
def is_loaded(self) -> bool: ...
def load(self): ...
def unload(self): ...
def predict(self, *args, **kwargs): ...Зачем это нужно:
-
унификация работы с Transformers, Whisper, TTS;
-
менеджер памяти работает с любой моделью;
-
добавление новой модели = новый класс + минимум кода.
Пример: DeepSeekOCR, WhisperASR, QwenChat — разные библиотеки, одинаковый интерфейс.
Полный поток данных: от запроса до ответа
На примере OCR:
-
Клиент отправляет
POST /ocr/extract-text. -
FastAPI маршрутизирует запрос.
-
Происходит валидация входных данных.
-
Получаем модель через
get_ocr_model(). -
При необходимости — ленивая загрузка.
-
Инференс в отдельном потоке.
-
Опциональная постобработка через LLM.
-
Формируется JSON‑ответ.
FastAPI при этом остаётся:
-
быстрым;
-
неблокирующим;
-
предсказуемым.
Почему именно такая архитектура
Коротко по причинам:
-
Singleton для моделей
— минимальный overhead и переиспользование памяти. -
Чёткое разделение Router / Model
— API не зависит от конкретной реализации модели. -
Базовый класс
— единый контракт для менеджера памяти. -
Async‑friendly подход
— FastAPI остаётся отзывчивым даже при тяжёлых инференсах.
Итог
Мы получили архитектуру, которая:
-
легко расширяется;
-
стабильно работает под нагрузкой;
-
готова к продакшену;
-
и, самое главное, позволяет управлять памятью осознанно.
В следующем разделе мы разберём как именно эта архитектура позволяет запускать 4 нейросети на 16 GB VRAM и почему без неё сервис будет падать.
Управление памятью: как запустить 4 AI-модели на 16 GB VRAM
Этот раздел — ключевой во всей статье. Я намеренно выбрал сложную конфигурацию: четыре достаточно тяжёлые нейросети и всего 16 GB видеопамяти. Это не демонстрация «в вакууме», а попытка показать реальную ситуацию, в которой оказываются большинство продакшн-проектов.
Если ничего не делать с памятью, такой сервис будет регулярно падать с CUDA out of memory, независимо от того, насколько аккуратно написан код.
Почему это критично
Модели в проекте действительно прожорливые:
-
Qwen 2.5-3B (LLM) — компактная чат‑модель, но всё равно ~4–5 GB VRAM;
-
DeepSeek OCR — визуальная модель, на пиках ~6–7 GB;
-
Whisper Large‑v3 — крупная ASR‑модель, ~5–6 GB;
-
MMS‑TTS — относительно лёгкая, но тоже ~2–3 GB.
Если попытаться держать их все одновременно в памяти, получится: 17–21 GB VRAM при наличии всего 16 GB
Без продуманной стратегии управления памятью приложение будет нестабильным. Поэтому дальше — не «оптимизации ради оптимизаций», а необходимые инженерные решения.
Стратегия управления памятью
В проекте используется многоуровневый подход, который можно свести к четырём ключевым идеям.
1. Очистка CUDA-контекста после каждого инференса
Проблема
После обработки запроса модель не освобождает всю память автоматически. В видеопамяти остаются:
-
промежуточные активации;
-
KV-cache;
-
временные тензоры.
Пример для OCR:
-
загрузка модели: ~6 GB VRAM;
-
после одного инференса: ~7 GB;
-
после нескольких запросов подряд: 8–9 GB.
Память накапливается как снежный ком.
Решение
Принудительно очищать CUDA-кеш после каждого инференса:
def predict(self, image_data: bytes) -> str:
result = self.model.generate(...)
# КРИТИЧНО: очистка контекста
if torch.cuda.is_available():
torch.cuda.empty_cache()
gc.collect()
return resultЭта простая операция:
-
экономит 1–3 GB VRAM;
-
предотвращает накопление «мусора»;
-
резко снижает вероятность OOM при серии запросов.
2. Гибридное распределение GPU / CPU памяти
Проблема
Даже с очисткой контекста бывают пики, когда GPU-памяти физически не хватает — особенно при параллельных запросах.
Решение
Использовать device_map="auto" + жёсткие лимиты памяти и CPU offload.
Пример конфигурации:
ocr_max_gpu_memory_gb = 10.0
whisper_max_gpu_memory_gb = 10.0
tts_max_gpu_memory_gb = 8.0
chat_max_gpu_memory_gb = 12.0
cpu_offload_memory_gb = 25.0При загрузке модели:
max_memory = {
0: f"{gpu_mem}GB",
"cpu": f"{cpu_mem}GB"
}
model = AutoModel.from_pretrained(
model_name,
device_map="auto",
max_memory=max_memory
)Как это работает:
-
модель сначала пытается уместиться в GPU;
-
если не влезает — часть слоёв уходит в RAM;
-
GPU никогда не превышает заданный лимит.
Цена — небольшая потеря скорости. Выгода — полное отсутствие OOM-крэшей.
3. Lazy Loading + Auto-Unload (ленивая загрузка и выгрузка)
Ключевой вопрос
Зачем держать в памяти все модели сразу, если в конкретный момент используется только одна?
Lazy Loading
Модели не загружаются при старте приложения.
@router.post("/extract-text")
async def extract_text(file: UploadFile):
model = get_ocr_model()
if not model.is_loaded():
logger.info("Загрузка OCR модели по требованию...")
await asyncio.to_thread(model.load)
return await asyncio.to_thread(model.predict, file)Экономия:
-
при старте сервиса: ~0 GB VRAM;
-
память используется только при реальных запросах.
Auto-Unload
Если модель не используется некоторое время — она выгружается автоматически.
class BaseModel:
def __init__(self):
self.last_used: Optional[datetime] = None
def update_last_used(self):
self.last_used = datetime.now()
def get_idle_time_minutes(self) -> float:
if self.last_used is None:
return 0.0
delta = datetime.now() - self.last_used
return delta.total_seconds() / 60.0
def should_auto_unload(self, timeout_minutes: int) -> bool:
return self.get_idle_time_minutes() > timeout_minutesФоновый менеджер:
class MemoryManager:
async def _monitor_loop(self):
while self._running:
await asyncio.sleep(60)
for name, model in self.all_models:
if model.should_auto_unload(timeout_minutes=5):
logger.info(f"Выгрузка {name}")
model.unload()
torch.cuda.empty_cache()Жизненный цикл модели:
-
запрос → загрузка → быстрые ответы;
-
5 минут простоя → выгрузка → 0 GB VRAM;
-
новый запрос → повторная загрузка.
4. Защита от OOM: приоритетная выгрузка моделей
Проблема
Пользователь может почти одновременно вызвать OCR, ASR и Chat. Все модели начнут загружаться и переполнят GPU.
Решение
Перед загрузкой новой модели:
-
проверяем свободную память;
-
выгружаем самые «долго простаивающие» модели.
def auto_unload_old_models_if_needed(required_gb: float = 2.0):
free_gb = get_free_gpu_memory()
if free_gb >= required_gb:
return
loaded_models.sort(key=lambda x: x[2], reverse=True)
for name, model, idle_time in loaded_models:
if not model.is_loaded():
continue
model.unload()
torch.cuda.empty_cache()
if get_free_gpu_memory() >= required_gb:
returnИспользование в эндпоинтах:
if not model.is_loaded():
await asyncio.to_thread(auto_unload_old_models_if_needed, required_gb=2.5)
await asyncio.to_thread(model.load)Итог: стабильная работа на 16 GB VRAM
Благодаря этой стратегии мы получаем:
-
Zero OOM crashes
-
в памяти только активные модели (обычно 1–2)
-
пиковое потребление: 10–12 GB вместо 21 GB
-
4–6 GB запаса под пики
-
полностью автоматическое управление памятью
Типичное потребление VRAM
-
старт приложения: ~500 MB;
-
первый OCR‑запрос: ~6–7 GB;
-
OCR + Chat: ~10–11 GB;
-
5 минут простоя: ~500 MB.
Именно это и позволяет стабильно запускать мультимодальные AI-сервисы на доступном железе, без серверов с 48+ GB VRAM.
Модуль app/models: унифицированные обёртки над AI-моделями
Перед тем как переходить к управлению памятью, нужно разобраться с ещё одним фундаментальным элементом проекта — модулем app/models. Именно здесь скрыта большая часть «магии», позволяющей управлять разными нейросетями одинаково.
Философия модуля: один интерфейс для разных библиотек
Главная боль при работе с несколькими AI-моделями — разрозненный API. Каждая библиотека живёт своей жизнью:
-
Transformers (Hugging Face) —
AutoModel.from_pretrained(),model.generate(); -
Whisper —
model.transcribe(), своя логика работы с аудио; -
TTS —
synthesizer.tts(), фонемы, sample rate; -
PyTorch напрямую —
forward(), ручное управлениеdevice.
Без абстракции код быстро превращается в набор if / elif:
# Плохо: каждая модель — отдельный мир
if model_type == "ocr":
result = ocr_model.generate(...)
elif model_type == "asr":
result = whisper_model.transcribe(...)
elif model_type == "tts":
result = tts_model.tts_to_file(...)Такой код:
-
сложно поддерживать;
-
невозможно масштабировать;
-
почти нереально оптимизировать по памяти.
Решение: единый интерфейс для всех моделей
В проекте используется простой, но очень мощный принцип:
load(), predict(), unload()
# Хорошо: все модели работают одинаково
for model in [ocr_model, asr_model, tts_model, chat_model]:
if not model.is_loaded():
model.load()
result = model.predict(data)
if model.get_idle_time_minutes() > 5:
model.unload()Что внутри модели — Transformers, Whisper, TTS или чистый PyTorch — остальному коду не важно.
Структура модуля app/models
app/models/
├── base.py # Базовый абстрактный класс
├── deepseek_ocr.py # OCR модель
├── whisper_asr.py # ASR модель
├── mms_tts.py # TTS модель
└── qwen_chat.py # Chat / LLM модельКаждый файл — это самодостаточная обёртка, которая:
-
знает, как загрузить модель;
-
умеет выполнять inference;
-
корректно управляет памятью;
-
безопасно выгружается из GPU / CPU.
BaseModel: контракт для всех моделей
В основе лежит абстрактный класс BaseModel. Он задаёт единый контракт, которому обязаны следовать все модели.
class BaseModel(ABC):
def is_loaded(self) -> bool: ...
def load(self): ...
def unload(self): ...
def predict(self, *args, **kwargs): ...Что здесь важно:
-
@abstractmethod
Python не позволит создать модель без реализацииload(),unload()иpredict(). -
Общее состояние
self.model,self.last_usedхранятся в базовом классе и работают одинаково для всех. -
Мониторинг использования
Методыget_idle_time_minutes()иshould_auto_unload()используются менеджером памяти без знания конкретной модели.
Это делает весь остальной код типобезопасным и предсказуемым.
Централизованная конфигурация моделей
Все параметры вынесены в единый конфиг app/config.py на базе pydantic-settings.
class Settings(BaseSettings):
device: str = "cuda"
cache_dir: str = "./models_cache"
# OCR
deepseek_ocr_model: str = "deepseek-ai/DeepSeek-OCR"
ocr_max_gpu_memory_gb: float = 10.0
# ASR
whisper_model: str = "antony66/whisper-large-v3-russian"
whisper_max_gpu_memory_gb: float = 10.0
# TTS
mms_tts_model: str = "facebook/mms-tts-rus"
tts_max_gpu_memory_gb: float = 8.0
# Chat
gemma_chat_model: str = "Qwen/Qwen2.5-3B-Instruct"
chat_max_gpu_memory_gb: float = 12.0Преимущества такого подхода:
-
все настройки в одном месте;
-
легко переопределять через
.env; -
типизация и валидация;
-
singleton — конфиг создаётся один раз.
Пример реализации: DeepSeek OCR
Рассмотрим, как абстракция выглядит на практике.
DeepSeekOCR наследуется от BaseModel и реализует только специфичную логику:
-
загрузку через
Transformers; -
обработку изображений и PDF;
-
OCR-инференс;
-
очистку памяти.
class DeepSeekOCR(BaseModel):
def load(self):
settings = get_settings()
max_memory = {
0: f"{settings.ocr_max_gpu_memory_gb}GB",
"cpu": f"{settings.cpu_offload_memory_gb}GB"
}
self.model = AutoModel.from_pretrained(
self.model_name,
device_map="auto",
max_memory=max_memory,
torch_dtype=torch.bfloat16,
cache_dir=self.cache_dir
) А метод predict() инкапсулирует всю сложность:
-
PDF → изображения;
-
resize больших картинок;
-
batch processing;
-
очистку CUDA-контекста.
Для роутеров и менеджера памяти это просто:
text = ocr_model.predict(image_bytes)Почему это лучше, чем «просто импорт модели»
Без обёртки
model = AutoModel.from_pretrained(...)
# Как проверить состояние?
# Как выгрузить?
# Где конфигурация?
# Как считать idle time?С обёрткой
if not model.is_loaded():
model.load()
text = model.predict(data)
if model.get_idle_time_minutes() > 5:
model.unload()Все проблемы решены один раз и навсегда.
Итог: элегантность через абстракцию
Модуль app/models решает три ключевые задачи:
-
унификация — все модели имеют одинаковый API;
-
инкапсуляция — сложность библиотек спрятана внутри;
-
централизация — конфигурация и состояние под контролем.
Это позволяет:
-
легко добавлять новые модели;
-
прозрачно управлять памятью;
-
держать FastAPI-код чистым и читаемым.
Теперь переходим к нашей обертке напрямую, а именно, разберемся с роутерами.
Модуль app/routers: HTTP API Gateway
Если модуль app/models отвечает за бизнес-логику работы с нейросетями, то app/routers — это точка входа во всю систему. Именно здесь FastAPI превращается в полноценный HTTP-шлюз между внешним миром и AI-моделями.
Роутеры:
-
принимают HTTP‑запросы;
-
валидируют входные данные;
-
вызывают нужную модель;
-
возвращают результат в структурированном JSON.
Клиент
(HTTP / JSON)
│
▼
┌─────────────────────────┐
│ app/routers/ocr.py │
│ │
│ 1. Валидация входа │
│ 2. Получение модели │
│ 3. model.predict() │
│ 4. JSON ответ │
└──────────┬──────────────┘
│
▼
┌─────────────────────────┐
│ app/models/deepseek_ocr │
│ (OCR бизнес-логика) │
└─────────────────────────┘Принцип разделения ответственности
Здесь важно зафиксировать ключевую идею:
-
Роутер не знает, как работает модель — он просто вызывает
predict(); -
Модель не знает про HTTP, JSON и FastAPI — она занимается только inference.
Благодаря этому API и ML-часть развиваются независимо.
Структура модуля: один роутер = один раздел API
app/routers/
├── ocr.py # /ocr/* — OCR
├── asr.py # /asr/* — Speech-to-Text
├── tts.py # /tts/* — Text-to-Speech
└── chat.py # /chat/* — LLMКаждый роутер:
-
имеет собственный URL-префикс;
-
отдельный Swagger-раздел;
-
singleton-экземпляр модели;
-
одинаковый набор endpoint’ов.
Регистрация в main.py выглядит максимально прозрачно:
app.include_router(ocr.router)
app.include_router(asr.router)
app.include_router(tts.router)
app.include_router(chat.router)В Swagger UI это превращается в аккуратную, читаемую структуру:
📁 OCR
├ POST /ocr/extract-text
├ GET /ocr/model-info
└ POST /ocr/reload-model
ASR
TTS
ChatАнатомия роутера: на примере OCR
Рассмотрим типичный роутер по шагам.
1. Конфигурация роутера
router = APIRouter(
prefix="/ocr",
tags=["OCR (Optical Character Recognition)"]
)Это:
-
задаёт URL-префикс;
-
группирует endpoint’ы в Swagger.
2. Singleton-экземпляр модели
ocr_model: DeepSeekOCR = None
def get_ocr_model() -> DeepSeekOCR:
global ocr_model
if ocr_model is None:
ocr_model = DeepSeekOCR(...)
return ocr_modelПочему это критично:
-
загрузка модели = 5–10 секунд;
-
потребление = 5–7 GB VRAM;
-
создавать модель на каждый запрос — гарантированный OOM.
Singleton решает это один раз и навсегда.
3. Основной endpoint
@router.post("/extract-text")
async def extract_text(file: UploadFile, normalize: bool = False):
model = get_ocr_model()
if not model.is_loaded():
await asyncio.to_thread(auto_unload_old_models_if_needed, required_gb=2.5)
await asyncio.to_thread(model.load)
model.update_last_used()
text = await asyncio.to_thread(model.predict, contents)
return {"text": text, "status": "success"}Что здесь происходит:
-
Валидация входных данных;
-
Получение модели;
-
Ленивая загрузка при необходимости;
-
Inference в отдельном потоке;
-
Формирование JSON-ответа.
Ключевые паттерны, используемые в роутерах
1. Singleton Pattern
Один экземпляр модели на всё приложение:
-
экономия памяти;
-
мгновенные повторные запросы;
-
сохранение состояния между вызовами.
2. Единая структура endpoint’ов
Каждый роутер следует одному шаблону:
-
основной endpoint — функциональность;
-
/model-info— статус и метаданные; -
/reload-model— принудительная перезагрузка.
Это даёт:
-
предсказуемый API;
-
простые клиенты;
-
единый мониторинг.
3. Ленивая загрузка (is_loaded())
Модель не загружается при старте сервиса:
class BaseModel(ABC):
def is_loaded(self) -> bool: ...
def load(self): ...
def unload(self): ...
def predict(self, *args, **kwargs): ...4. Асинхронность без блокировки event loop
ML-inference — синхронная и тяжёлая операция. Если выполнять её напрямую, FastAPI «замирает».
Решение — asyncio.to_thread():
await asyncio.to_thread(model.load)
await asyncio.to_thread(model.predict, data)Результат:
-
event loop остаётся свободным;
-
сервис принимает новые запросы;
-
throughput вырастает в несколько раз.
5. Единая обработка ошибок
Все роутеры:
-
логируют полный traceback;
-
возвращают клиенту понятный JSON.
Клиент видит:
{ "detail": "Ошибка при обработке файла" }А сервер — полноценный лог для отладки.
Преимущества модульной структуры роутеров
-
Изолированность
Можно отключить OCR, не затрагивая ASR или TTS. -
Масштабируемость
Новая модель = новый файл +include_router(). -
Читаемая документация
Swagger становится интуитивным. -
Переиспользование кода
Общая логика вынесена вapp/utils.py.
Итог: роутеры как фасад для AI-логики
Модуль app/routers реализует паттерн Facade:
-
скрывает сложность ML;
-
предоставляет простой HTTP-интерфейс;
-
остаётся лёгким и читаемым.
В связке с app/models это даёт:
-
чистую архитектуру;
-
стабильную работу;
-
основу для продакшн-сервиса.
В следующем разделе мы переходим к самому важному — управлению памятью и тому, как эта архитектура позволяет удерживать 4 нейросети в рамках 16 GB VRAM без падений.
Файл сборки приложения: app/main.py
Если app/models — это бизнес-логика работы с нейросетями, а app/routers — HTTP-интерфейс, то app/main.py — это точка входа и оркестратор всего приложения.
Именно здесь:
-
создаётся экземпляр FastAPI;
-
подключаются все роутеры;
-
настраиваются middleware (CORS);
-
инициализируются фоновые задачи;
-
регистрируются lifecycle-события (startup / shutdown).
uvicorn app.main:app
│
▼
┌─────────────────────────────┐
│ app/main.py │
│ │
│ 1. FastAPI instance │
│ 2. Middleware │
│ 3. Routers │
│ 4. MemoryManager │
│ 5. Lifecycle hooks │
└─────────────────────────────┘Общая структура main.py
Файл можно логически разделить на несколько блоков:
-
настройка логирования;
-
lifecycle management (startup / shutdown);
-
создание FastAPI-приложения;
-
middleware (CORS);
-
подключение роутеров;
-
служебные endpoints;
-
entry point для запуска.
Такой порядок делает файл прозрачным и легко читаемым, даже при довольно насыщенной логике.
Lifecycle management: управление жизненным циклом приложения
Один из ключевых моментов — использование lifespan через@asynccontextmanager.
@asynccontextmanager
async def lifespan(app: FastAPI):
# STARTUP
...
yield
# SHUTDOWN
...Что происходит при запуске
При старте приложения:
-
логируется текущая конфигурация;
-
инициализируется и запускается
MemoryManager; -
подготавливаются фоновые задачи.
Что происходит при завершении
При остановке (Ctrl+C, SIGTERM):
-
корректно останавливается
MemoryManager; -
все загруженные модели принудительно выгружаются из памяти;
-
освобождаются GPU и CPU ресурсы.
STARTUP
├─ логирование конфигурации
├─ запуск MemoryManager
└─ готовность принимать запросы
SHUTDOWN
├─ остановка MemoryManager
├─ выгрузка всех моделей
└─ graceful shutdownПочему это важно:
-
гарантированный cleanup ресурсов;
-
отсутствие утечек GPU-памяти;
-
корректное завершение в production-среде.
Глобальный MemoryManager
MemoryManager — это фоновый оркестратор, который следит за тем, какие модели используются, и автоматически выгружает простаивающие.
Он запускается один раз при старте приложения:
if settings.auto_unload:
memory_manager = MemoryManager()
await memory_manager.start()И корректно останавливается при shutdown.
Важный момент: main.py не знает, как именно работает менеджер памяти. Он лишь:
-
запускает его;
-
останавливает;
-
доверяет ему контроль над моделями.
Это ещё один пример чистого разделения ответственности.
Создание FastAPI-приложения
app = FastAPI(
title="FastAPI AI Models",
description="...",
version="1.0.0",
lifespan=lifespan,
docs_url="/docs",
redoc_url="/redoc"
)Что это даёт из коробки:
-
Swagger UI (
/docs); -
ReDoc (
/redoc); -
OpenAPI-схему (
/openapi.json); -
lifecycle hooks без костылей.
FastAPI здесь выступает не просто как HTTP-сервер, а как платформа для AI-сервиса.
Middleware: CORS
Для возможности работы с фронтендом или внешними клиентами подключается CORS:
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # для dev
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)В production это легко ограничивается конкретными доменами — всё централизовано в одном месте.
Подключение роутеров
app.include_router(ocr.router)
app.include_router(asr.router)
app.include_router(tts.router)
app.include_router(chat.router)Это даёт важные преимущества:
-
модульность — любой роутер можно отключить одной строкой;
-
масштабируемость — новый AI‑модуль = новый роутер;
-
прозрачность — весь API виден сразу.
Служебные endpoints
/
Корневой endpoint — быстрая проверка, что сервис жив:
{
"message": "FastAPI AI Models API",
"docs": "/docs",
"models": {
"ocr": "/ocr/model-info",
"asr": "/asr/model-info"
}
}/health
Health check для мониторинга, load balancer и Kubernetes:
-
статус приложения;
-
наличие GPU;
-
текущее потребление памяти.
Используется для:
-
liveness / readiness probes;
-
автоматического мониторинга.
/models/status
Самый полезный диагностический endpoint:
-
какие модели загружены;
-
сколько времени простаивают;
-
текущее состояние GPU-памяти.
Идеален для:
-
отладки OOM-проблем;
-
понимания нагрузки;
-
capacity planning.
Entry point для запуска
if __name__ == "__main__":
uvicorn.run(
"app.main:app",
host="0.0.0.0",
port=8000,
reload=False
)Позволяет:
-
запускать приложение напрямую (
python -m app.main); -
использовать
uvicornилиgunicornв production.
Порядок инициализации приложения
При запуске происходит следующий поток:
-
uvicorn app.main:app -
импорт модулей и конфигурации
-
создание FastAPI instance
-
подключение middleware
-
регистрация роутеров
-
lifespan STARTUP -
приложение готово принимать запросы
-
lifespan SHUTDOWNпри остановке
Итог: main.py как дирижёр оркестра
app/main.py — это дирижёр, который:
-
создаёт сцену (FastAPI);
-
подключает инструменты (роутеры);
-
управляет ресурсами (MemoryManager);
-
следит за порядком (lifecycle);
-
корректно завершает работу.
При этом сам файл остаётся компактным и читаемым, а вся сложность вынесена в специализированные модули.
Запуск и тестирование приложения
На этом этапе у нас уже есть:
-
настроенный сервер с GPU;
-
собранное FastAPI-приложение;
-
архитектура, менеджер памяти и все модели.
Теперь запускаем сервис и проверяем, что всё действительно работает так, как задумано.
Подготовка окружения
Открываем терминал на сервере (через VS Code Remote SSH или обычный SSH) и переходим в директорию проекта.
Шаг 1. Активация виртуального окружения
cd /home/fastapi_ai
source .venv/bin/activateЕсли окружение активировано корректно, в начале строки появится:
(.venv) user@server:/home/fastapi_ai$Шаг 2. Установка зависимостей
При первом запуске устанавливаем зависимости:
pip install -r requirements.txtУстановка займёт 5–10 минут, так как PyTorch и CUDA-библиотеки достаточно тяжёлые.
Запуск приложения
Базовый запуск (development)
Открываем первый терминал и запускаем сервис:
uvicorn app.main:app --host 0.0.0.0 --port 8000 --log-level infoПараметры:
-
app.main:app— путь к FastAPI instance; -
--host 0.0.0.0— слушаем все интерфейсы; -
--port 8000— порт сервиса; -
--log-level info— читаемые логи.
Успешный запуск выглядит так:
Application startup complete.
Uvicorn running on http://0.0.0.0:8000
Запуск FastAPI AI Models...
Memory Manager запущен
Все роутеры подключеныПризнаки, что всё в порядке:
-
нет ошибок в логах;
-
Memory Managerуспешно стартовал; -
приложение слушает порт.
Тестирование через curl
Открываем второй терминал (первый оставляем с логами).
1. Проверка доступности
curl http://localhost:8000/Ответ:
{
"message": "FastAPI AI Models API",
"docs": "/docs",
"models": {
"ocr": "/ocr/model-info",
"asr": "/asr/model-info",
"tts": "/tts/model-info",
"chat": "/chat/model-info"
}
}2. Health Check
curl http://localhost:8000/health | jqПроверяем:
-
приложение живо;
-
GPU доступна;
-
память используется корректно.
3. Статус моделей
curl http://localhost:8000/models/status | jqПри первом запуске все модели будут выгружены — это нормально (lazy loading).
4. Тест OCR
curl -o test.jpg "https://via.placeholder.com/800x200/FFFFFF/000000?text=Hello+World+OCR"
curl -X POST "http://localhost:8000/ocr/extract-text" \
-F "file=@test.jpg" | jqПервый запрос:
-
загружает OCR модель;
-
занимает 6–7 GB VRAM;
-
может длиться 10–20 секунд.
5. OCR + нормализация через LLM
curl -X POST "http://localhost:8000/ocr/extract-text?normalize=true" \
-F "file=@test.jpg" | jqПри этом автоматически подгружается Chat-модель.
6. Тест Chat
curl -X POST "http://localhost:8000/chat/simple" \
-H "Content-Type: application/json" \
-d '{"message": "Привет! Как дела?"}' | jq7. Тест ASR и TTS
Аналогично проверяем:
-
/asr/transcribe— распознавание речи; -
/tts/synthesize— синтез аудио в WAV.
Проверка авто-выгрузки моделей
Ничего не делаем 5+ минут, затем:
curl http://localhost:8000/models/status | jqМодели будут автоматически выгружены, а GPU-память освобождена — это и есть ключевая цель всей архитектуры.
Публикация сервиса: systemd
Если на предыдущем этапе вы убедились, что приложение корректно запускается, модели загружаются и тестовые запросы отрабатывают без ошибок, можно переходить к завершающим шагам:
-
перевести FastAPI‑приложение в постоянный продакшен‑режим;
-
обеспечить автозапуск и автоматический рестарт при сбоях;
-
подготовить сервис к публикации наружу под доменным именем.
Начнём с systemd — это самый простой и надёжный способ управлять сервисом на сервере без лишних технологий.
Запуск FastAPI через systemd
Почему systemd
systemd решает сразу несколько задач:
-
автозапуск приложения при старте сервера;
-
автоматический перезапуск при падениях;
-
централизованные логи;
-
контроль состояния сервиса (
active / failed).
Для GPU-сервиса с нейросетями это дефолтный и рекомендуемый вариант.
Шаг 1. Останавливаем запущенное приложение
Если FastAPI сейчас запущено вручную через uvicorn — остановите его (Ctrl+C) и убедитесь, что порт 8000 свободен.
Шаг 2. Проверяем структуру проекта
Переходим в директорию проекта:
cd /home/fastapi_ai
pwd
ls -laУбедитесь, что:
-
есть файл
app/main.py; -
виртуальное окружение
.venvсоздано и содержитuvicorn.
Шаг 3. Создаём systemd unit-файл
Создаём сервис:
sudo nano /etc/systemd/system/fastapi-ai.serviceВставляем конфигурацию:
[Unit]
Description=FastAPI AI app with Uvicorn (GPU)
After=network.target
[Service]
Type=simple
User=root
Group=root
WorkingDirectory=/home/fastapi_ai
# Используем виртуальное окружение
Environment=PATH=/home/fastapi_ai/.venv/bin:/usr/local/bin:/usr/bin:/bin
# Явно указываем GPU
Environment=CUDA_VISIBLE_DEVICES=0
# Оптимизация аллокации CUDA памяти
Environment=PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
ExecStart=/home/fastapi_ai/.venv/bin/uvicorn app.main:app \
--host 0.0.0.0 \
--port 8000 \
--log-level info
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.targetВажно про workers
Для GPU-приложений рекомендуется --workers 1. Несколько воркеров означают несколько процессов, каждый из которых будет:
-
иметь собственные экземпляры моделей;
-
дублировать потребление VRAM;
-
быстро привести к OOM.
Поэтому в данном проекте:
-
1 worker = стабильность и контроль памяти.
Шаг 4. Перезагружаем systemd и запускаем сервис
sudo systemctl daemon-reload
sudo systemctl enable fastapi-ai
sudo systemctl start fastapi-aiШаг 5. Проверяем статус и логи
Проверяем состояние:
sudo systemctl status fastapi-aiОжидаемый результат:
● fastapi-ai.service - FastAPI AI app with Uvicorn
Loaded: loaded (/etc/systemd/system/fastapi-ai.service)
Active: active (running)Смотрим логи в реальном времени:
sudo journalctl -u fastapi-ai -fВы должны увидеть знакомые сообщения:
-
запуск FastAPI;
-
инициализация Memory Manager;
-
подключение роутеров.
Шаг 6. Проверяем работу сервиса
Теперь приложение работает в фоне. Проверяем:
curl http://localhost:8000/
curl http://127.0.0.1:8000/healthЕсли ответы приходят — сервис стабильно работает и готов к проксированию через Nginx.
Управление сервисом (шпаргалка)
sudo systemctl stop fastapi-ai # остановить
sudo systemctl start fastapi-ai # запустить
sudo systemctl restart fastapi-ai # перезапустить
sudo systemctl status fastapi-ai # статус
sudo journalctl -u fastapi-ai -f # логиЧто мы получили на этом этапе
К этому моменту у нас есть:
-
FastAPI‑приложение, работающее в продакшен‑режиме;
-
автозапуск при старте сервера;
-
автоматический рестарт при сбоях;
-
централизованные логи через systemd;
-
стабильная работа с GPU и памятью.
Следующий шаг — публикация сервиса наружу: настроим Nginx, привяжем домен и включим HTTPS, чтобы API стало доступно извне.
Публикация наружу: Nginx + домен + HTTPS
На этом этапе FastAPI-приложение уже стабильно работает через systemd и доступно на localhost:8000. Осталось сделать последний шаг — открыть сервис во внешний мир:
-
привязать доменное имя;
-
настроить Nginx как reverse-proxy;
-
включить HTTPS с помощью Let’s Encrypt.
Шаг 1. Установка Nginx и Certbot
На сервере устанавливаем всё необходимое:
sudo apt update
sudo apt install -y nginx certbot python3-certbot-nginxПроверяем, что Nginx запущен:
sudo systemctl status nginxЕсли сервис активен — можно двигаться дальше.
Шаг 2. Проверка DNS
Перед настройкой Nginx обязательно убедитесь, что домен уже указывает на IP сервера.
Проверить можно так:
ping your-domain.ruили:
dig your-domain.ru +shortЕсли возвращается IP вашего сервера — DNS настроен корректно.
Шаг 3. Базовый конфиг Nginx (без HTTPS)
Сначала создаём простейший HTTP-конфиг, чтобы убедиться, что проксирование работает.
Переходим в директорию конфигураций:
cd /etc/nginx/sites-availableСоздаём новый файл (название = домен):
sudo nano your-domain.ruМинимальный конфиг без HTTPS:
server {
listen 80;
server_name your-domain.ru www.your-domain.ru;
client_max_body_size 300M;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
}
}Активируем конфиг:
sudo ln -s /etc/nginx/sites-available/your-domain.ru /etc/nginx/sites-enabled/Проверяем конфигурацию:
sudo nginx -tПерезапускаем Nginx:
sudo systemctl reload nginxТеперь проверьте в браузере:
http://your-domain.ruЕсли FastAPI отвечает — значит проксирование работает корректно.
Шаг 4. Подключаем HTTPS через Certbot
Когда HTTP-доступ работает, можно включать HTTPS.
Запускаем Certbot:
sudo certbot --nginx -d your-domain.ru -d www.your-domain.ruCertbot:
-
автоматически выпустит SSL-сертификат;
-
изменит конфиг Nginx;
-
настроит редирект с HTTP → HTTPS.
После успешного выполнения сайт станет доступен по:
https://your-domain.ruФинальный боевой конфиг Nginx (пример)
После работы Certbot конфигурация будет выглядеть примерно так (пример из реального продакшена):
server {
server_name yakvenalexx-habr.ru www.yakvenalexx-habr.ru;
# Таймауты для долгих запросов (OCR, ASR, TTS)
client_body_timeout 1800s;
proxy_connect_timeout 1800s;
proxy_send_timeout 1800s;
proxy_read_timeout 1800s;
send_timeout 1800s;
client_max_body_size 300M;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Отключаем буферизацию (важно для streaming / long inference)
proxy_buffering off;
# WebSocket support (на будущее)
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
listen 443 ssl;
ssl_certificate /etc/letsencrypt/live/yakvenalexx-habr.ru/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/yakvenalexx-habr.ru/privkey.pem;
include /etc/letsencrypt/options-ssl-nginx.conf;
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem;
}
server {
listen 80;
server_name yakvenalexx-habr.ru www.yakvenalexx-habr.ru;
return 301 https://$host$request_uri;
}Почему именно такие настройки
-
Большие таймауты
Нейросети могут обрабатывать запросы десятки секунд (OCR, ASR, TTS). -
client_max_body_size 300M
Для PDF, аудио и длинных файлов. -
proxy_buffering off
Убирает задержки при длинных ответах и стриминге. -
WebSocket‑заголовки
Не обязательны сейчас, но полезны, если позже появится streaming‑чат.
Проверка
Проверяем сертификат:
sudo certbot certificatesПроверяем автообновление:
sudo certbot renew --dry-runПроверяем доступность:
curl https://your-domain.ru/healthЧто мы получили в итоге
На этом этапе:
-
FastAPI работает как systemd-сервис;
-
Nginx выступает reverse-proxy;
-
домен привязан;
-
HTTPS включён;
-
API доступно извне;
-
готово к использованию в продакшене.
Тестируем API в Swagger
Теперь убедимся, что всё работает как часы: откроем Swagger UI и протестируем каждый эндпоинт.
В моём случае Swagger доступен по адресу: https://yakvenalexx-habr.ru/docs
На момент прочтения статьи ссылка скорее всего неактивна — VPS использовался только для демонстрации в этой статье.
Приступаем к тестам!
-
Перейдите по ссылке — увидите интерактивную документацию со всеми эндпоинтами
-
Нажимайте "Try it out" для каждого метода
-
Заполняйте параметры и жмите Execute
-
Проверяйте ответы в правой панели — статус 200 и корректный JSON?
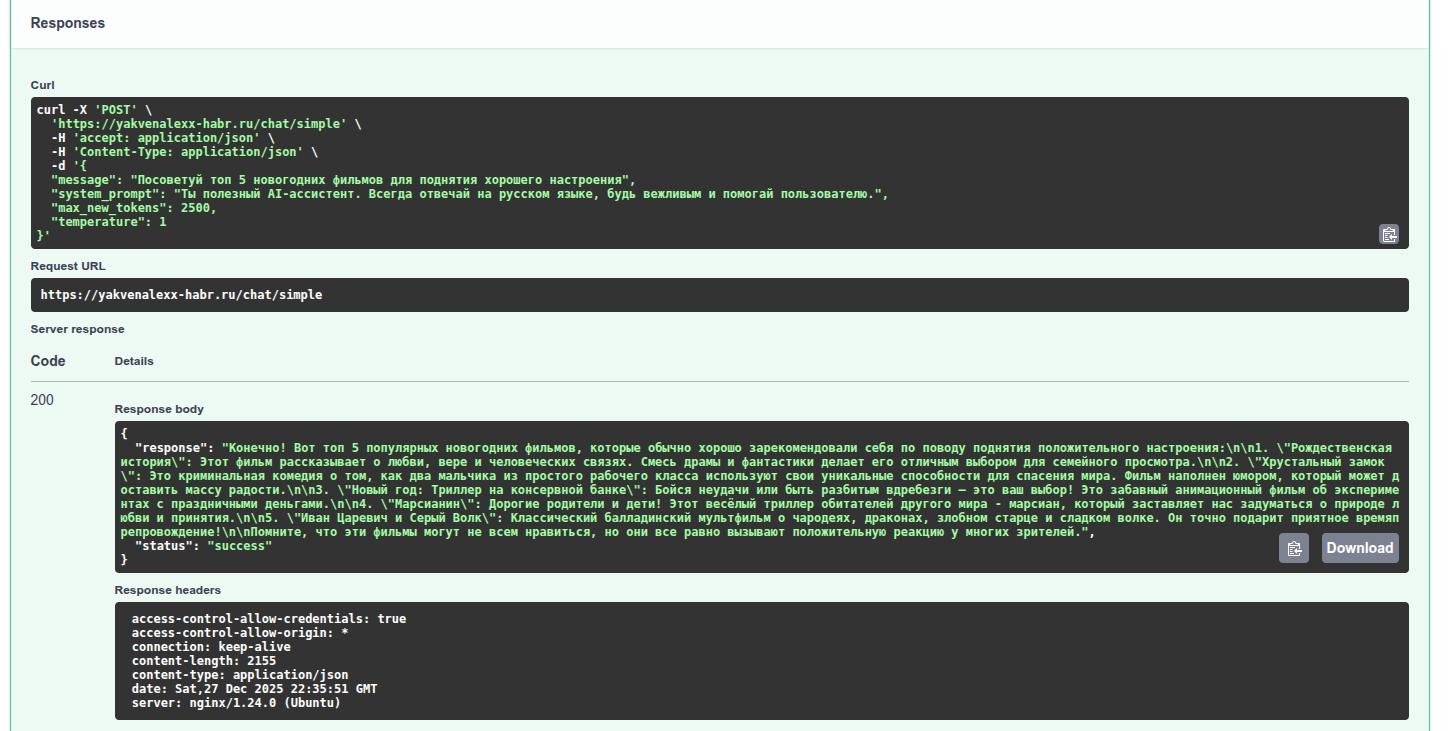
Тестируем Qwen модель (чат)

Фото для теста OCR
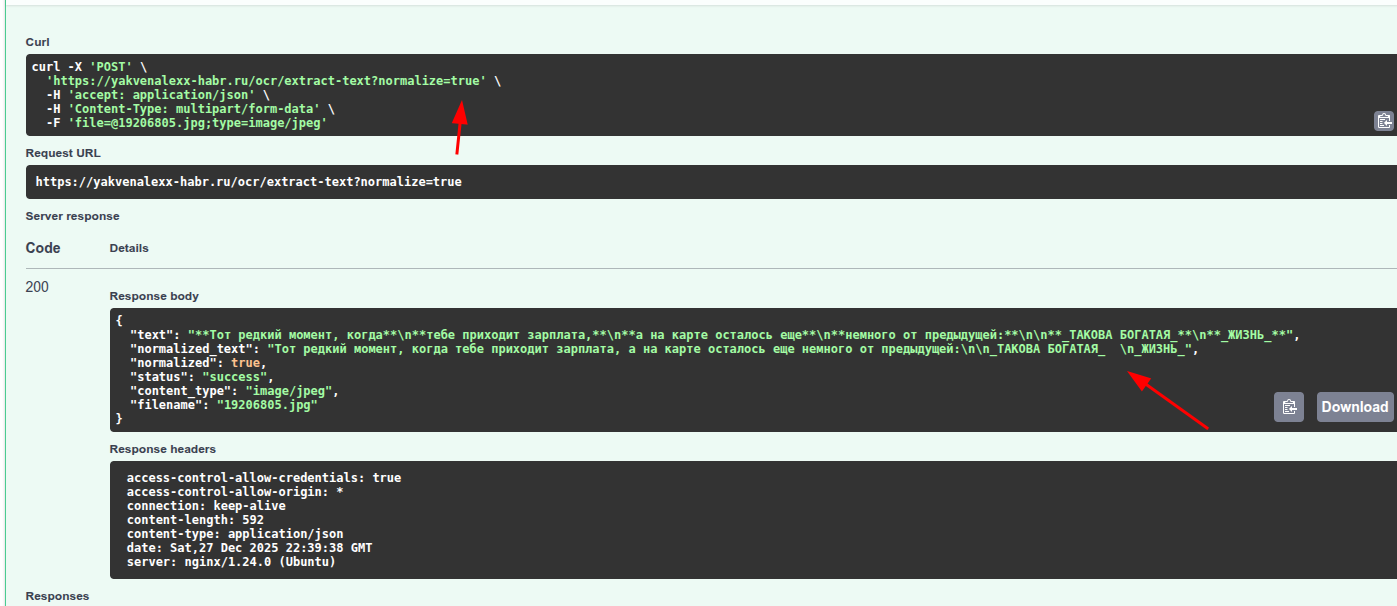
Результат теста с нормализацией через Qwen
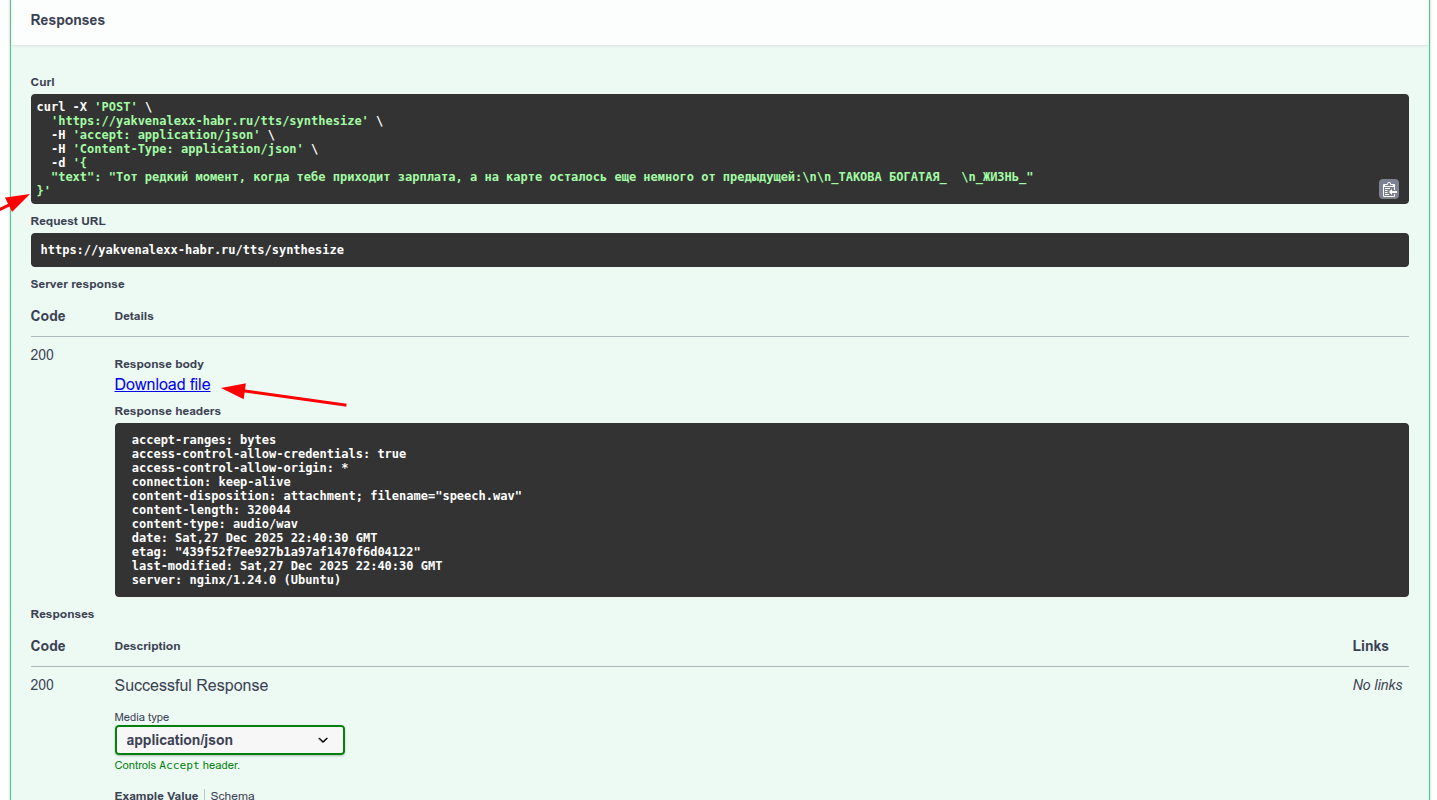
Теперь озвучим прочитанный через OCR текст
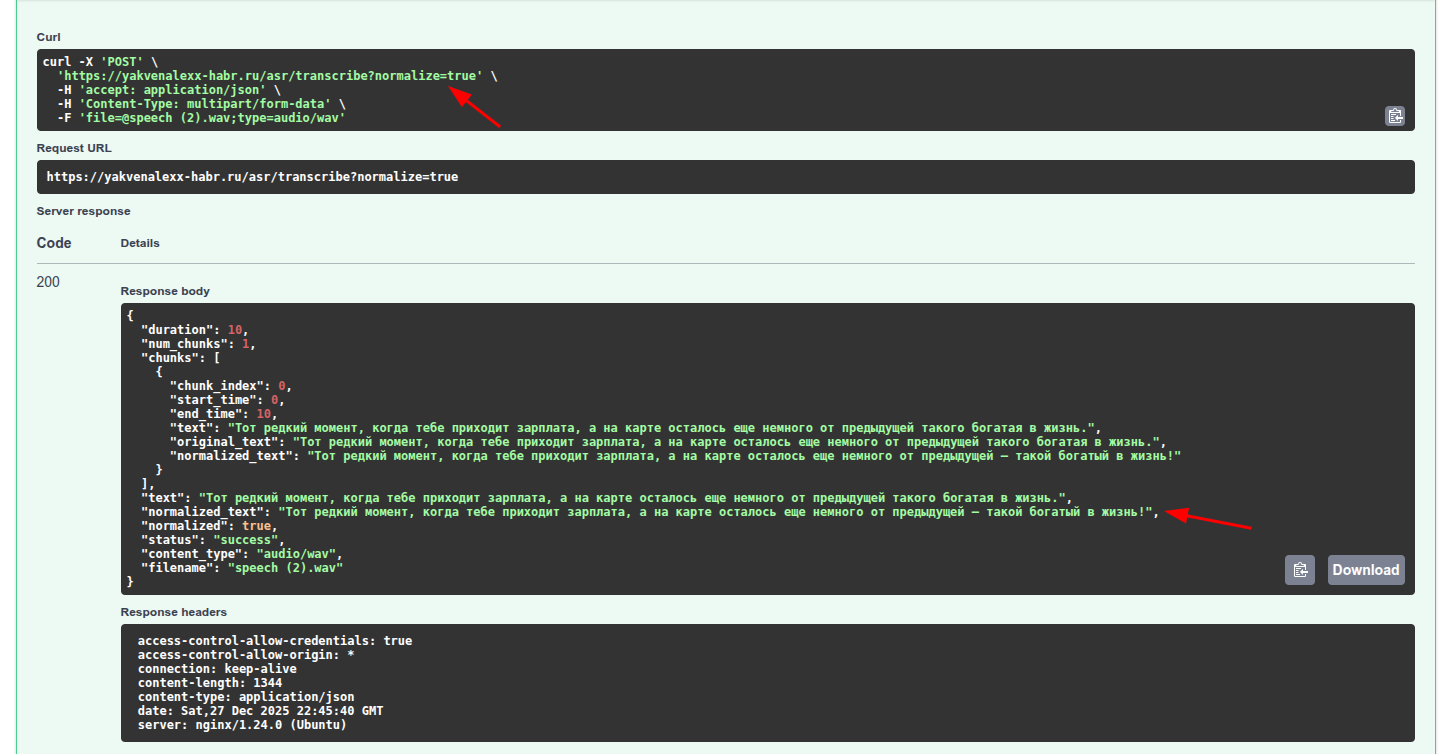
Распознаем полученное аудио через Whisper.
Если все тесты проходят — сервис готов к бою!
Выводы
В этой статье мы прошли полный путь — от идеи до рабочего продакшен-сервиса с локальными нейросетями.
В итоге у нас получилось:
-
полноценное мультимодальное AI‑приложение (OCR, ASR, LLM, TTS);
-
работа на одной GPU с 16 GB VRAM без облачных API;
-
осознанная архитектура на FastAPI + PyTorch + Transformers;
-
умное управление памятью, без
CUDA Out of Memory; -
стабильный продакшен‑запуск через systemd;
-
публикация наружу через Nginx + домен + HTTPS.
По сути, мы собрали локальный AI-сервис «под ключ», который:
-
не отправляет данные на сторонние сервера;
-
имеет предсказуемую стоимость;
-
легко масштабируется и расширяется;
-
подходит как для pet‑проектов, так и для бизнес‑задач.
Где такой сетап действительно полезен
Подобная архитектура хорошо подходит для:
-
корпоративных сервисов, где важна конфиденциальность данных;
-
внутренних инструментов (документооборот, распознавание речи, ассистенты);
-
стартапов, которым дорого масштабироваться на облачных API;
-
экспериментальных проектов, где важен полный контроль над моделями;
-
образовательных и R&D‑задач.
Главный вывод, который я хотел донести: локальные нейросети — это больше не «дорого и сложно». При грамотной архитектуре и управлении ресурсами они становятся вполне доступным и практичным инструментом.
Что можно улучшать дальше
Если развивать этот проект, логичные следующие шаги:
-
добавить streaming‑ответы для Chat и ASR;
-
прикрутить очередь задач (например, Redis + background workers);
-
добавить авторизацию и rate limiting;
-
вынести модели на отдельные GPU при росте нагрузки;
-
подключить метрики и мониторинг (Prometheus / Grafana).
Основа для всего этого уже заложена.
Серверы с видеокартами NVIDIA — от доступных моделей начального уровня до профессиональных Tesla, в дата-центрах в России и Европе.
При длительной аренде — скидка до 35 %.