
PolyLoss: не focal loss единым
Авторы этой статьи вспомнили, что не зря сидели на парах по матанализу (наконец-то он хоть где-то пригодился!), и что функцию, в том числе и функцию потерь в машинном обучении, можно разложить в ряд Тейлора, то есть представить в виде суммы полиномов разных степеней. Для адаптации под конкретную задачу/датасет было предложено сделать коэффициенты при многочленах обучаемыми параметрами, а чтобы этих параметров было не слишком много, оставить в разложении только младшие степени полиномов. Модификации часто используемых кросс-энтропии и focal loss в итоге дали неплохой прирост в задачах классификации, детекции и сегментации, при этом авторы уделили большое внимание коэффициенту при многочлене первой степени (пресказание-истинный лейбл)1: по мере обучения сети эта часть функции потерь играет все большую роль. Поскольку полиномы других степеней стремятся к нулю, в итоговой функции можно учитывать только этот коэффициент.

Исследование показывает, что красота в простоте, а умелое добавление даже одной строчки кода может привести к значительному улучшению результатов (+0.6% на imagenet сопоставимы с переходом от топовых сверточных моделей к моделям, использующим трансформеры).
Рассвет text-to-image: Imagen и Cogview2
Напомним, что DALL-E 2 активнее, чем первая версия, использует модель CLIP, которая позволяет спроецировать изображения и текст в единое пространство эмбеддингов (в нем можно сравнить похожесть картинки и ее описания). В DALL-E 2 через CLIP по тексту получается текстовый эмбеддинг и через prior-сеть перегоняется в картиночный clip-эмбеддинг. По нему диффузионная модель (представленная в 2021 году GLIDE, позволяющая генерировать изображения по заданному текстом ограничению/условию) получает изображение размером 64x64. Далее два диффузионных апсэмплера (две нейросети) доводят разрешение изображения до 1024x1024. Ничего сложного.
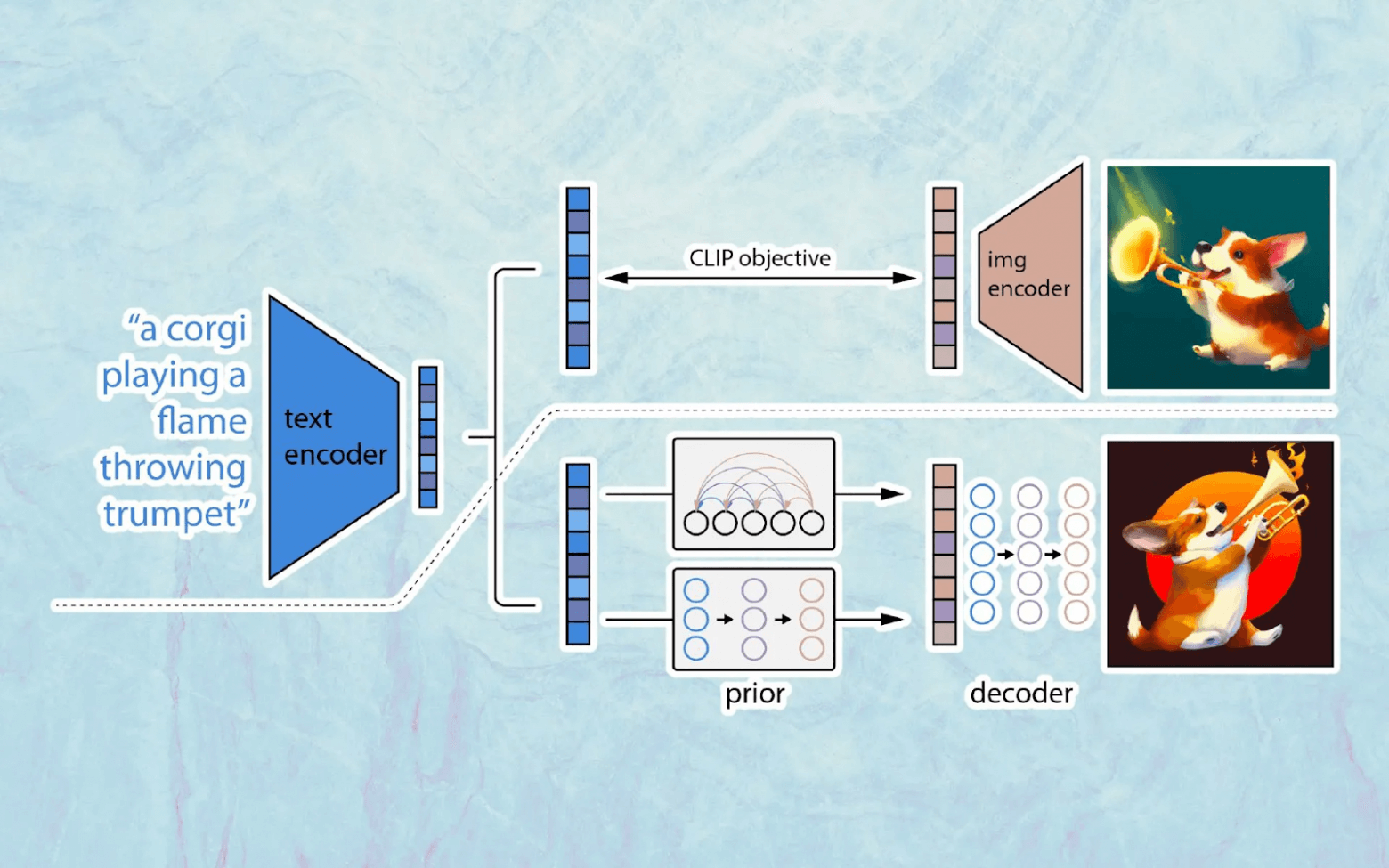
Imagen от Google в сравнении с DALL-E 2 логически выглядит проще: это всего лишь GLIDE, который по текстовому эмбеддингу генерирует семантически соответствующее входному тексту изображение (и опять же два апсэмплера после этого). Ключевое отличие от DALL-E 2 — использование для получения текстового эмбеддинга предобученной модели, обучающейся и работающей только с текстами. Авторы пробовали разные энкодеры, в том числе и CLIP, но лучшие результаты получились при использовании энкодера от T5-XXL (трансформерный энкодер-декодер, решающий задачи обработки текстов на естественном языке). Тренировалось это все на комбинации закрытых и открытых датасетов пар «текст-изображение» (итоговое количество составило 860 миллионов таких пар).
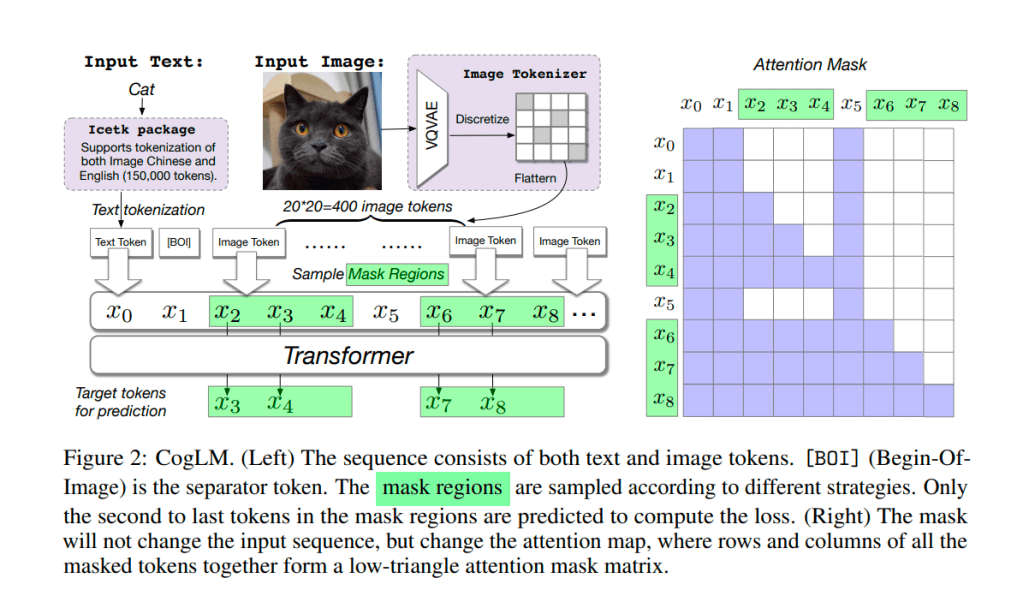
CogView2 использует другой способ объединения мультимодальных данных (текст+изображение) и их использования для предварительного обучения вспомогательной сети. Основой выступает модель CogLM, на вход которой поступает преобразованный к токенам текст, а также фиксированное количество токенов изображения, полученных из VQVAE — модели, способной преобразовывать изображение к набору слов из обучаемого словаря и восстанавливать изображение по этому набору слов-токенов.
Преобразованные к токенам текст и изображения подаются в трансформер, который учится решать разные задачи в зависимости от того, какую часть информации мы от него скрываем: если маскируем токены изображения, получаем text-to-image, а если частично маскируем токены изображений и токены текста, получаем одновременное решение задач inpainting (восстановления закрашенной части изображения) и image captioning (получения описания изображения). Далее идет стандартный для таких задач superresolution-блок, увеличивающий разрешение изображения.
Обучали это все разработчики на собственном датасете, составленном из уже известных (таких как Conceptual Captions) и содержащем пары «изображение-описание» и изображение из интернета (30 млн. обучающих пар).
Создатели imagen и авторы CogView2 пишут о результатах, сравнимых с DALL-E 2 или даже лучших по качеству и соответствию текстовым описаниям (при дообучении CogVIew2 и тестировании на COCO и даже вариант zero-shot без дообучения в случае с imagen). Нет ничего удивительного и в том, что, согласно попарному сравнению на собственном бенчмарке DrawBench (генерация картинок по сложным запросам), лучшим оказался именно imagen, к тому же эта модель использует куда более тяжелый чем CLIP текстовый энкодер. Ниже можно ознакомиться со сравнительными результатами генерации на сложных запросах (к сожалению, CogView2 не сравнивался в Drawbench, поэтому о возможностях этой модели остается только догадываться на основе доступных примеров).

Стремительное развитие подходов к созданию качественных изображений по каким угодно запросам кого-то еще пугает (раздаются призывы выпить за упокой художников), однако скорее всего это сильно подстегнет креативность и будет способствовать созданию еще более выдающихся продуктов и изобретений, в которых нейросети будут лишь инструментом маститого артиста-изобретателя.
CoCa — очередная SOTA на Imagenet или что-то большее?
В контексте связи изображений и текстовой информации можно выделить три основных класса моделей. В варианте single encoder изображение кодируется представлением, по которому мы можем получить соответствующий текстовый класс, решая задачу классификации. Подход позволяет решать относительно простые задачи понимания того, что представлено на фото/видео. В варианте dual encoder изображение и текст проецируются в единое латентное пространство, в котором можно оценить их семантическую близость.
Примером такого подхода является CLIP, обучающийся c использованием идеи contrastive learning со следующим ограничением: расстояние между заданной парой «изображение-текст» должно быть минимальным между всеми возможными такими парами в датасете. Метод расширяет возможности первого подхода, но все равно ограничен и не в состоянии обеспечить решение связанных с одновременным восприятием текстовой и зрительной информации задач. Наконец, подход encoder-decoder позволяет более гибко объединить мультимодальную информацию: так, в simvlm и flamingo трансформер принимает на вход одновременно токены текста и изображения и декодирует их в текст для решения задач image captioning и vqa.
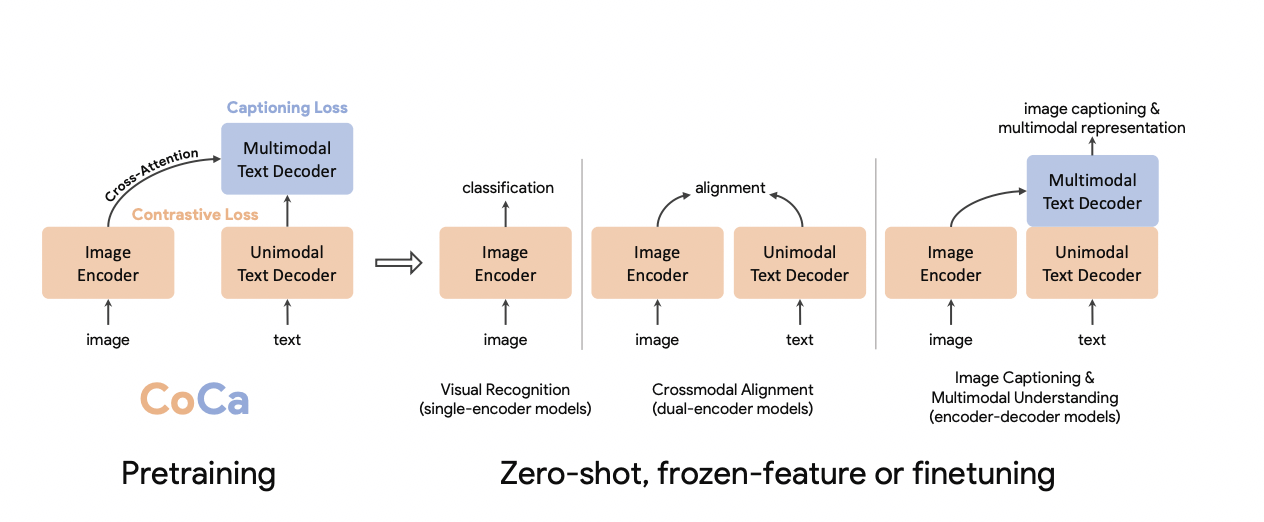
Авторы статьи объединили два последних подхода. Текстовый трансформер-декодер разделен на две части: первая обучается по принципу contrastive learning так, чтобы cls-токен (который отвечает за представление всего предложения, подаваемого на вход) на ее выходе максимально соответствовал изображению из пары в датасете, а вторая учится получать captioning/описание изображения, «подглядывая» при помощи механизма кросс-внимания в визуальный энкодер.
В результате после обучения на большом (и, в отличие от BLIP, достаточно шумном) датасете мы получаем три блока, комбинируя которые можно добиться отличных результатов в разных задачах: классификации (если возьмем энкодер изображения и дотренируем его на нужном датасете или же будем искать подходящий класс, перебирая все расстояния между cls и соответствующим энкодингом изображения), captioning (после дообучения энкодера и второй части декодера на датасете а-ля COCO), а также задач, связанных с нахождением по запросу самого релевантного изображения из базы (по аналогии с CLIP).
Таким образом, еще в 2018 – 2019 годах специально обучаемые на датасете Imagenet модели получали на этом же датасете точность порядка 86% (85 и 87 соответственно для ResNeXt 32x48d и EfficientNet), а сейчас мы имеем модель, которая в режиме zero-shot (то есть без обучения на этом датасете) дает 86,3%, что не может не впечатлять. Метод наглядно показывает, как устранить разрыв между разными подходами к предварительному обучению моделей, и может стать подспорьем к дальнейшим исследованиям в области мультимодальных данных.
***
Во второй части статьи читайте новости из области создания и детекции дипфейков, а также преобразования текста в речь.