
Автор: DevOps Team Leader компании Hostkey Никита Зубарев
Инфраструктура нашей компании поддерживается на высоком уровне SLA, что требует от нас измерения, наблюдения и отправки отчетов, фиксирующих метрики производительности систем, в том числе серверов, которые мы предоставляем в аренду.
У нас возникла необходимость внедрения централизованного механизма опроса IPMI/iDRAC/TP-IPMI для обнаружения перегрева, проблем с системой охлаждения и т. д. и повышения качества предоставляемого оборудования в целом. Проще говоря, мы планируем внедрить систему опроса датчиков с портов управления материнских плат, чтобы оперативно обнаруживать перегрев, неработающие или частично работающие вентиляторы и другие проблемы с охлаждением (например, проверять обороты кулеров или физическое наличие вентилятора в разъеме).
В одной из прошлых статей мы рассмотрели варианты установки федерации Prometheus, Alertmanager и Node Exporter, blackbox_exporter, с использованием Promethus решим и сегодняшнюю задачу.
Напомним, что Prometheus — это система мониторинга и оповещения с открытым исходным кодом, широко применяемая для сбора, хранения и визуализации метрик системы. Она предоставляет мощные возможности для мониторинга разнообразных систем и приложений, в том числе серверов Supermicro с IPMI (Intelligent Platform Management Interface).
Supermicro — один из крупнейших производителей серверов и систем хранения данных, широко используемых в различных отраслях, таких как облачные вычисления, центры обработки данных и хостинг.
Клиенты могут использовать для управления арендованным оборудованием сервисную панель управления — invapi.hostkey.com. В ней в разделе управления питанием есть кнопка Sensors, предназначенная для вызова утилиты ipmitool и получения данных датчиков. В связи с этим для сбора метрик с серверов по SNMP можно использовать exporter Prometheus, который будет получать данные через BMC.
Поскольку клиенты самостоятельно администрируют свои серверы и у компании Hostkey нет прямого доступа к ним, данные можно получить только через BMC (Baseboard Management Controller).
Для решения этой задачи мы можем использовать Node Exporter с дополнительным модулем для сбора метрик через IPMI из BMC. Это позволит Prometheus запрашивать и агрегировать данные датчиков (температура, напряжение и т. д.) непосредственно с контроллеров управления серверами.
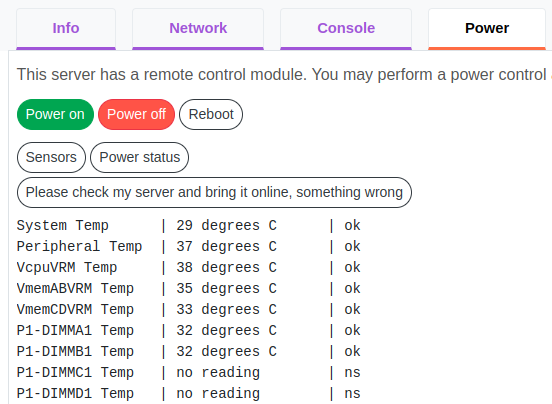
Основные API-методы управления питанием арендованных серверов описаны в нашей документации.
IPMItool — это утилита для управления и настройки устройств, поддерживающих стандарт IPMI. IPMI — открытый стандарт для мониторинга, регистрации, восстановления, инвентаризации и управления оборудованием, который реализован независимо от основного центрального процессора, BIOS и ОС.
Программа IPMItool предоставляет простой интерфейс командной строки для BMC. Она имеет возможность читать репозиторий данных датчиков (SDR) и печатать показания датчиков, отображать содержимое журнала системных событий (SEL), отображать системную информацию (FRU), управлять LAN и выполнить удаленное управление питанием сервера.
Таким образом, IPMItool позволяет управлять инфраструктурой на низком уровне в обход основной ОС сервера. Это критически важно для мониторинга и автоматизации.
ipmitool -I lanplus -H 10.77.0.1 -U ADMIN -P passwd sdr
3VSB | 3.30 Volts | ok
5VSB | 5.10 Volts | ok
VCPU | 0.97 Volts | ok
VSOC | 1.02 Volts | ok
VCCM | 1.21 Volts | ok
APU_VDDP | 0.92 Volts | ok
PM_VDD_CLDO | 1.20 Volts | ok
PM_VDDCR_S5 | 1.02 Volts | ok
PM_VDDCR | 1 Volts | ok
BAT | 3.20 Volts | ok
3V | 3.36 Volts | ok
5V | 5.04 Volts | ok
12V | 12.10 Volts | ok
MB Temp | 34 degrees C | ok
Card Side Temp | 30 degrees C | ok
X570 Temp | 46 degrees C | ok
DDR4_A1_Temp | 30 degrees C | ok
DDR4_A2_Temp | 28 degrees C | ok
DDR4_B1_Temp | 30 degrees C | ok
DDR4_B2_Temp | 30 degrees C | ok
Onboard LAN Temp | 32 degrees C | ok
TR1 | no reading | ns
FAN1 | no reading | ns
FAN2 | no reading | ns
FAN3 | 1400 RPM | ok
FAN4_1 | no reading | ns
FAN4_2 | no reading | ns
FAN5_1 | no reading | ns
FAN5_2 | no reading | ns
FAN6_1 | no reading | ns
FAN6_2 | no reading | ns
PSU1 AC lost | Not Readable | ns
PSU2 AC lost | Not Readable | ns
PSU1 VIN | no reading | ns
PSU2 VIN | no reading | ns
PSU1 IOUT | no reading | ns
PSU2 IOUT | no reading | ns
PSU1 PIN | no reading | ns
PSU2 PIN | no reading | ns
PSU1 POUT | no reading | ns
PSU2 POUT | no reading | ns
PSU1 Status | 0x00 | ok
PSU2 Status | 0x00 | ok
PSU1 Temp | no reading | ns
PSU2 Temp | no reading | ns
PSU1 Fan | no reading | ns
PSU2 Fan | no reading | ns
PSU1 Fan Status | Not Readable | ns
PSU2 Fan Status | Not Readable | ns
CPU_PROCHOT | 0x00 | ok
CPU_THERMTRIP | 0x00 | ok
ChassisIntr | 0x00 | ok
CPU Temp | 35 degrees C | ok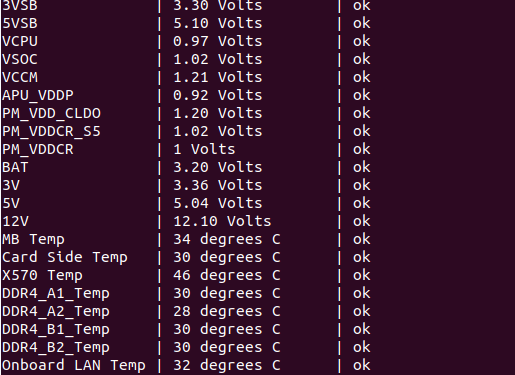
Доступны следующие сборщики, которые можно включить или отключить в конфигурации:
- sensor: собирает данные датчиков IPMI;
- fwum: собирает данные прошивки;
- fru: собирает данные BMC.
Мы взяли за основу готовый exporter и доработали его, так как внутреннюю разработку ведем на языке golang.
Он поддерживает как обычную /metrics — конечную точку, предоставляющую метрики с хоста, на котором работает экспортер, так и конечную /ipmi — точку, которая поддерживает IPMI через RMCP — один экспортер, работающий на одном хосте, может использоваться для мониторинга большого количества интерфейсов IPMI путем передачи target параметра.
Для сбора удаленных метрик через IPMI-конфигурация должна содержать учетные данные для доступа к серверам — имена пользователей и пароли. Иными словами, нужно указать логины и пароли (login/passd) для IPMI-интерфейса каждого сервера.
Управление доступами через LDAP мы рассмотрим в следующих статьях. А в данном примере используем простую авторизацию по логину и паролю для демонстрации сбора метрик. Вы можете дополнительно указать уровень привилегий для использования.
Приложение будем запускать в докере, вот его dockerfile:
FROM golang:1.16
ADD . / /build/
WORKDIR /build
RUN CGO_ENABLED=0 GOOS=linux go build -a -o ipmi_exporter .
FROM alpine:latest
RUN apk --no-cache add ipmitool
WORKDIR /root/
COPY --from=0 /build/ipmi_exporter ./
COPY ipmi_remote.yml ./
CMD ["./ipmi_exporter", "--config.file", "ipmi_remote.yml", "--web.listen-address=:9104"]Развертывание оформили на Ansible:

Конфигурации prometheus:
- job_name: ipmi
metrics_path: /ipmi
scrape_interval: 30m
scrape_timeout: 2m
static_configs:
file_sd_configs:
- files:
- 'targets_ipmi.json'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: host:9104Обратим внимание на files:
- 'targets_ipmi.json'
Prometheus динамически подгружает targets_ipmi.json, его мы дополнительной программой регулярно синхронизируем с нашей системой учета. Таким образом в конфигурацию попадают только актуальные серверы:
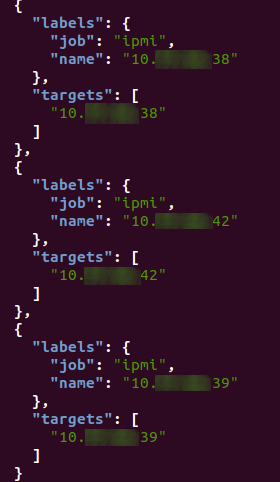
В таргетах появится IPMI и список хостов, каждый уже получает метрику в базу:
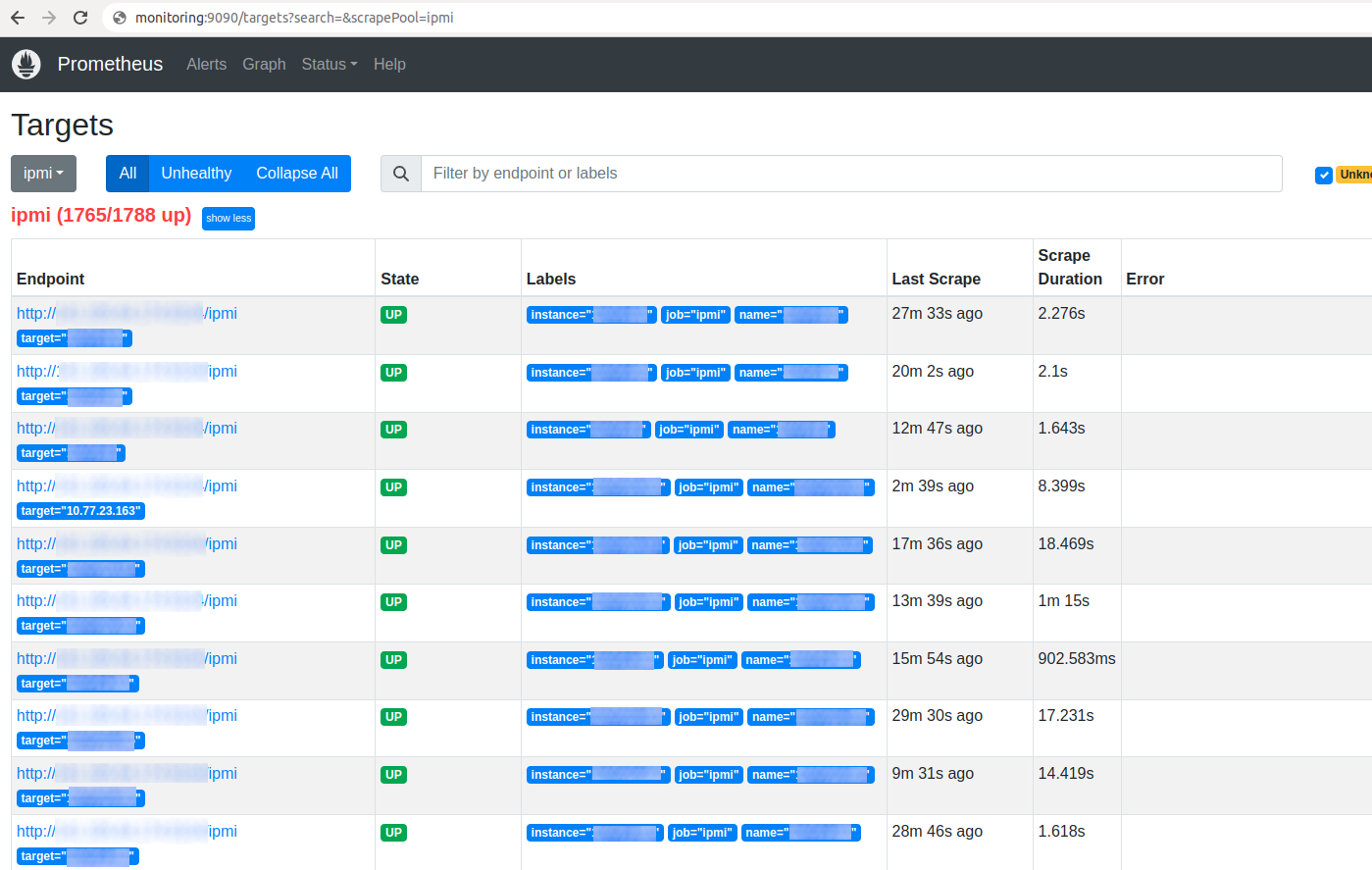
Метрика по хосту, ниже рассмотрим наиболее интересные параметры.
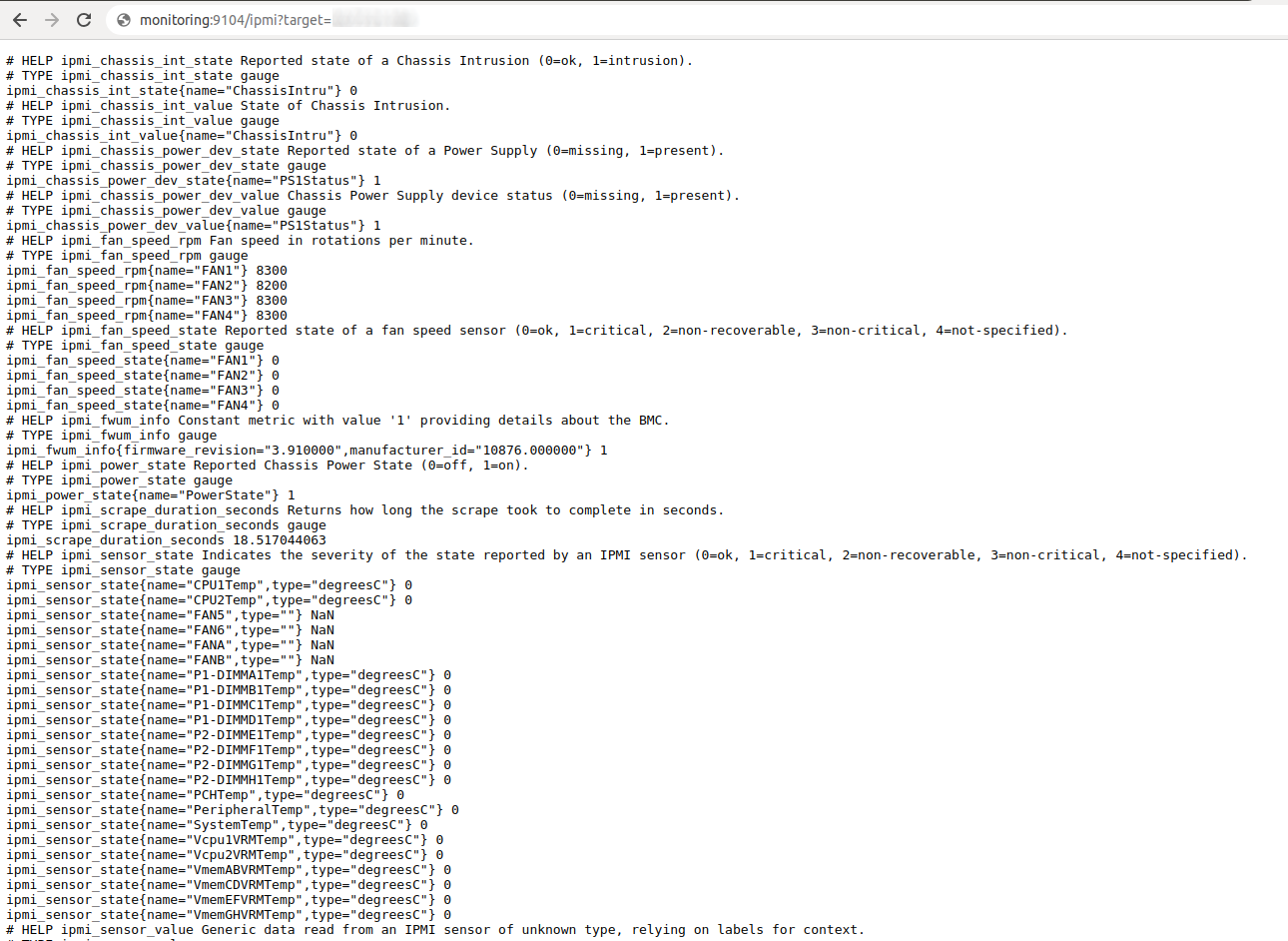
Наиболее интересные метрики:
# HELP ipmi_fan_speed_state Reported state of a fan speed sensor (0=ok, 1=critical, 2=non-recoverable, 3=non-critical, 4=not-specified).
# TYPE ipmi_fan_speed_state gauge
ipmi_fan_speed_state{name="FAN1"} 0
ipmi_fan_speed_state{name="FAN2"} 0
ipmi_fan_speed_state{name="FAN3"} 0
ipmi_fan_speed_state{name="FAN4"} 0
# HELP ipmi_power_state Reported Chassis Power State (0=off, 1=on).
# TYPE ipmi_power_state gauge
ipmi_power_state{name="PowerState"} 1
ipmi_sensor_value{name="CPU1Temp",type="degreesC"} 53
ipmi_sensor_value{name="CPU2Temp",type="degreesC"} 59
# TYPE ipmi_up gauge
ipmi_up{collector="fwum"} 1
ipmi_up{collector="sensor"} 1
# HELP ipmi_voltage_state Reported state of a voltage sensor (0=ok, 1=critical, 2=non-recoverable, 3=non-critical, 4=not-specified).
# TYPE ipmi_voltage_state gauge
ipmi_voltage_state{name="1.05VPCH"} 0
# TYPE ipmi_fwum_info gauge
ipmi_fwum_info{firmware_revision="3.910000",manufacturer_id="10876.000000"} 1Кроме мониторинга железа и оповещений о критических ситуациях система на базе Prometheus позволяет отслеживать актуальность прошивок и появление обновлений. Можно настроить дополнительные оповещения о выходе новых версий встроенного ПО для компонентов серверов Supermicro.
Это позволяет вести централизованный учет актуальности прошивок по всем серверам в инфраструктуре. На основании собранных в Prometheus данных удобно планировать работы по обновлению встроенного ПО, чтобы своевременно устанавливать последние версии прошивок с исправлениями уязвимостей и новыми возможностями.
Настроим уведомления для мониторинга, указав, какие события должны вызывать уведомления. Например, можно настроить уведомления о превышении температуры, напряжения или других параметров.
Осталось повесить алертинг на alermanager, для этого описываем правила и подключаем на prometheus:
ipmi_exporter.yml
groups:
- name: ipmi
rules:
- alert: InstanceDown
expr: up{job=<span class="m-green">"ipmi"</span>} == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ .instance }} down"
description: "{{ .instance }} of job {{ .job }} has been down for more than 5 minutes."
- alert: CPUTemp ipmi_sensor_value
expr: ipmi_sensor_value{name="CPUTemp",type="degreesC",job="ipmi"} > 60
for: 1m
labels:
severity: page
annotations:
summary: "High CPUTemp usage more 30 degreesC"
description: "High CPUTemp usage more 30 degreesC"
- alert: ipmi_power_state
expr: ipmi_power_state{job="ipmi"} == 0
for: 1m
labels:
severity: page
annotations:
summary: "Chassis Power State OFF"
- alert: ipmi_up
expr: ipmi_up{job="ipmi"} == 0
for: 1m
labels:
severity: page
annotations:
summary: "IPMI device not collect sensor"
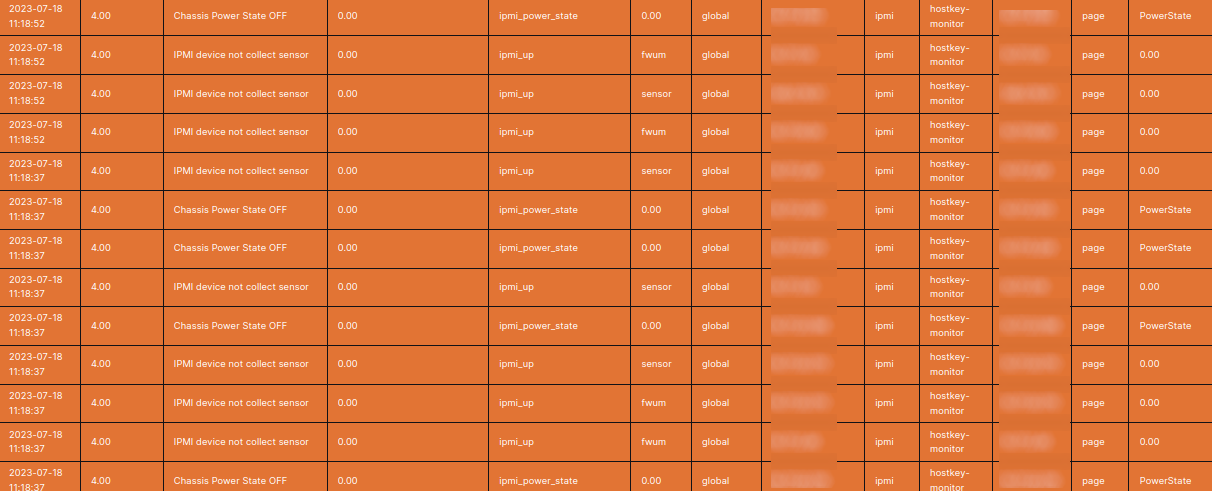
Заключение
В данной статье мы рассмотрели процесс настройки мониторинга и алертинга для серверов Supermicro на базе решения Prometheus. Благодаря использованию ipmitool_exporter удалось реализовать сбор метрик как с самих серверов Supermicro, так и через IPMI для отслеживания состояния железа.
Настройка правил и алертов в Prometheus позволяет получать оповещения о критических ситуациях, таких как перегрев компонентов или отказ вентиляторов. А визуализация метрик в Grafana дает наглядное представление о текущем состоянии и нагрузке на серверы.
Таким образом, использование Prometheus для мониторинга и алертинга Supermicro серверов дает ряд преимуществ: высокую доступность инфраструктуры, быстрое оповещение о проблемах, удобство визуализации данных. Это повышает надежность работы серверов Supermicro и позволяет своевременно реагировать на возникающие инциденты.