
OpenWebUI как хороший медиакомбайн для работы с нейросетями умеет и в генерацию изображений. Не своими силами, конечно, но позволяет даже неподготовленному пользователю написать промт и получить картинку, как если бы вы работали в ChatGPT или GigaChat. Сделать это можно через API OpenAI или используя интерфейсы доступа к моделям StableDiffusion или Flux типа stable-diffusion-webui (она же Automatic1111) или ComfyUI.
Добавление этой возможности не очень сложный процесс, но как обычно со своими нюансами. Ниже мы хотели бы пошагово пройти весь этот процесс и рассказать, как будет работать OpenWebUI после появления данной функции. А добавлять мы будем ComfyUI и модель StableDiffusion 3.5 Medium.
AI-платформа: предустановленные языковые LLM-модели на высокопроизводительных серверах с GPU-картами.
Арендуйте высокопроизводительный сервер с GPU картой с предустановленными лучшими LLM-моделями:
- DeepSeek-r1-14b
- Gemma-2-27b-it
- Llama-3.3-70B
- Phi-4-14b
🔶 Карты NVIDIA RTX4090 🔶 Почасовая оплата 🔶 Скидки до 30%
Ставим ComfyUI
ComfyUI у вас может быть поставлен на тот же сервер, где развернут OpenWebUI или на другой - вы в любом случае будете обращаться к нему через API по IP-адресу. В нашем случае ставим его на тот же сервер, где у нас «крутится» docker образ OpenWebUI под Ubuntu 22.04. Все делаем по официальной инструкции. Считаем, что у вас уже установлен Python 3 версии 3.10 или старше.
-
Клонируем git репозиторий (предварительно не забыв поставить сам git)
git clone https://github.com/comfyanonymous/ComfyUI.git -
Ставим PyTorch. Покажем на примере GPU от Nvidia, для AMD, Intel и Apple M1, M2 и старше смотрите информацию в Вики проекта.
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121 -
Переходим в директорию ComfyUI и устанавливаем остальные необходимые зависимости.
pip install -r requirements.txt
Далее нужно загрузить модель. Для этого нужно перейти в директорию ComfyUI/models/checkpoints и выполнить там команду:
wget https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8/resolve/main/sd3.5_medium_incl_clips_t5xxlfp8scaled.safetensorsЭто загрузит модель сразу со встроенными clip энкодерами и в fp8. Но никто не запрещает вам загрузить и настроить любую из поддерживаемых моделей по вашему желанию.
По идее все. Возвращаемся назад в директорию ComfyUI и проверяем его работоспособность.
python3 main.pyПосле этого можно открыть веб-интерфес по адресу http://localhost:8188.
Но… если вы устанавливаете ComfyUI на сервере, то по внешнему IP вы ничего не сможете открыть. Для этого нужно запускать ComfyUI с параметром --listen
python3 main.py --listen 248.255.56.23Тогда вы сможете зайти на http://248.255.56.23:8188 и также получить доступ.
Далее необходимо добавить workflow для модели SD3.5. Поиском оно находится на ура, но в OpenWebUI лучше работает немного другое, чем предлагаемое разработчиками ComfyUI. Поэтому качаем данный workflow по этой ссылке, а затем просто перетаскиваем данный json файл на открытый веб-интерфейс ComfyUI.
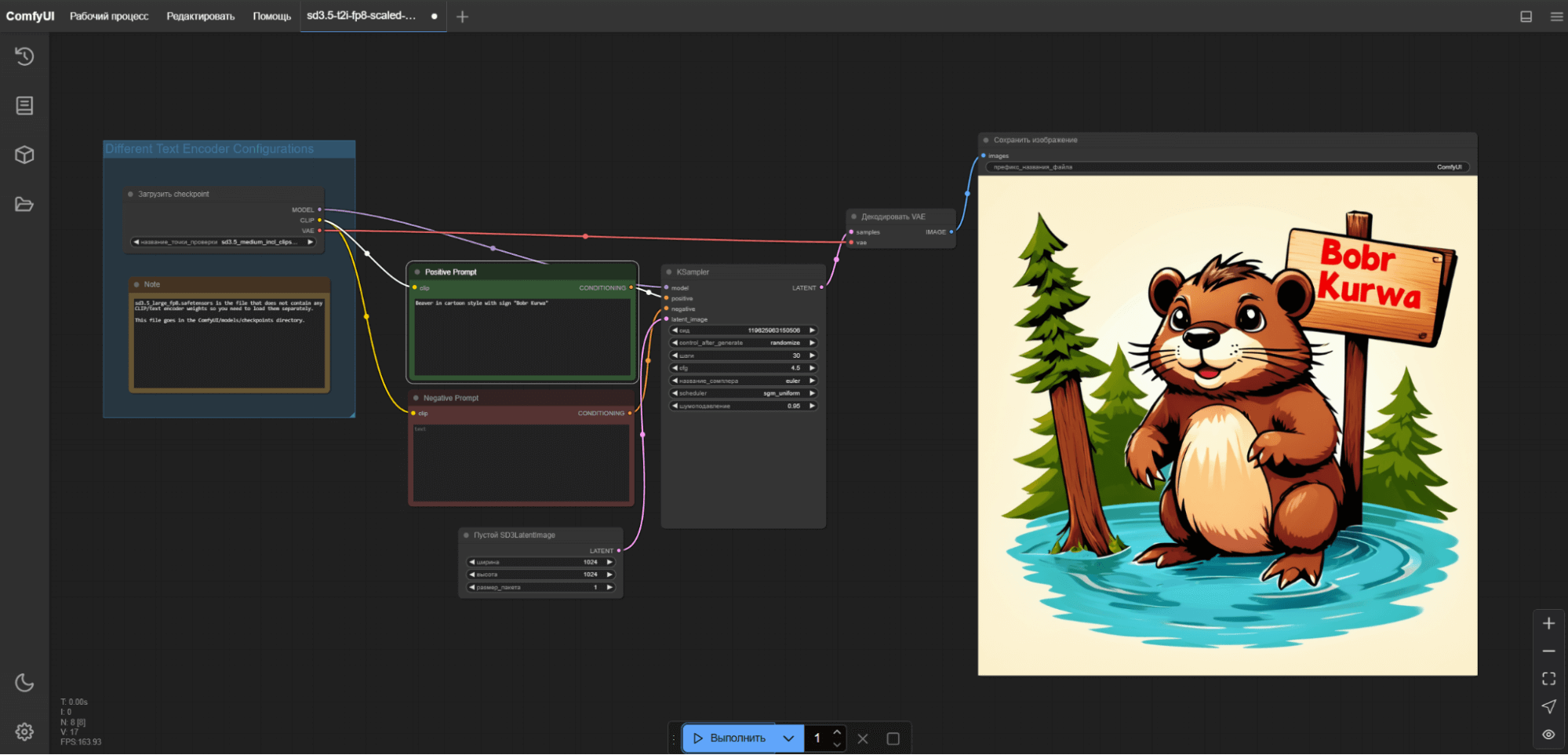
Проверяем генерацию, и если все работает, приступаем к добавлению ComfyUI в OpenWebUI.
Прикручиваем ComfyUI к OpenWebUI
Для начала необходимо сделать несколько подготовительных шагов. Первым делом экспортируем наш workflow как API, иначе мы получим в OpenWebUI только ошибки вместо картинок. Для этого:
-
Если у вас старое меню, то нажимаем в нем Save (API Format) и сохраняем новый json файл с workflow. Именно его вы будете экспортировать в OpenWebUI. Если же у вас новое меню, как у нас на рисунке, то выбираем пункт Рабочий процесс - Экспорт (API).
-
Далее необходимо запомнить ID нод с разными элементами (нас интересует сам промт, модель, размер изображения и нода с параметрами генерации). Для этого заходим в Настройки и там включаем в подменю LiteGraph настройку Режим значка ID ноды в Показать все.
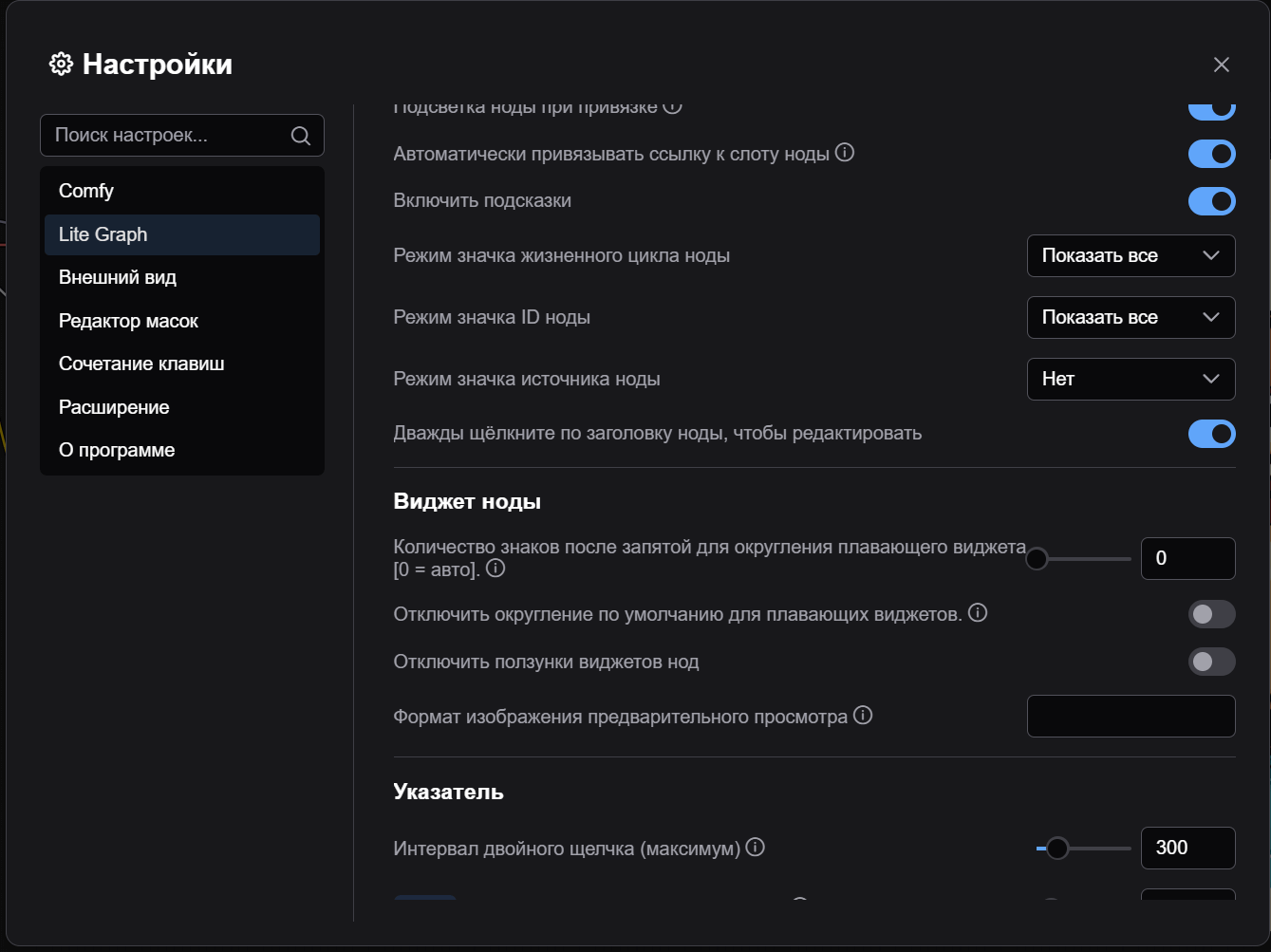
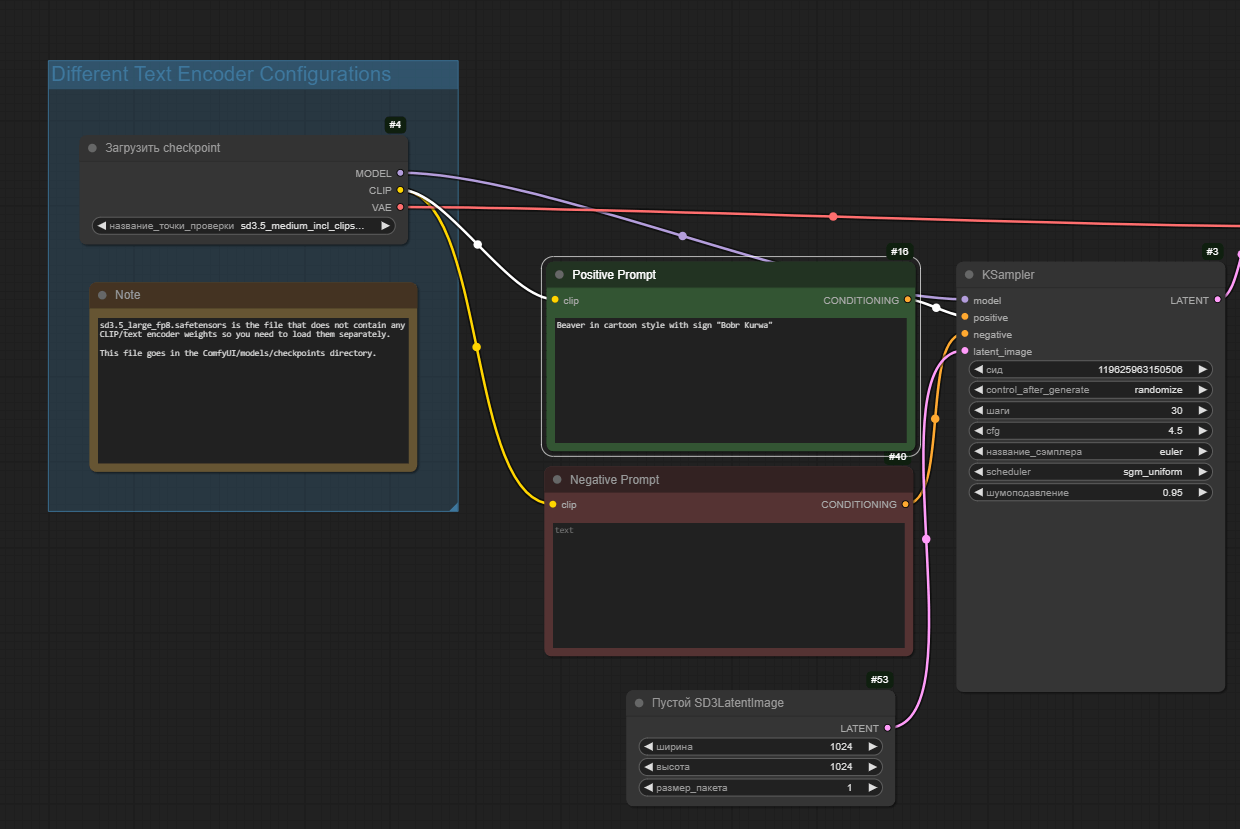
Теперь у нод будет отображаться их ID как #<ID>. Нам достаточно запомнить только ноду с Positive Promt, в нашем случае ее ID равен 16.
Открываем веб-интерфейс OpenWebUI и переходим в него. Заходим в Settings (вызывается кликом по имени пользователя в левом нижнем углу), далее в Admin Setting и затем в Images. Ставим Image Generation Engine в ComfyUI.
В поле ComfyUI Base URL заносим IP адрес с портом, по которому вы открыли до этого ComfyUI. Нажмите на значок со стрелочками «туда-сюда», чтобы проверить соединение с сервером.
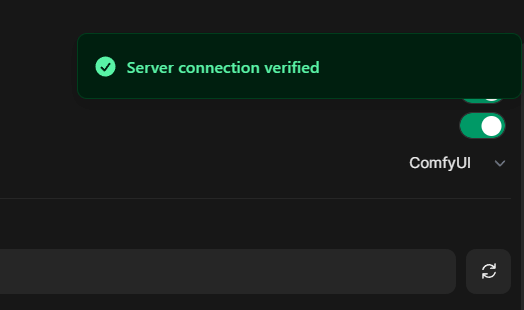
Далее нажимаем на кнопку Click here to upload workflow.json file и загружаем наш экспортированный API workflow. Не перепутайте, именно API, а не первоначальный!
После в таблице ComfyUI Workflow Nodes вводим для prompt* значение нашего ID равное 16. Вверху включаем Image Generation (Experimental) и ниже сразу же Image Prompt Generation.
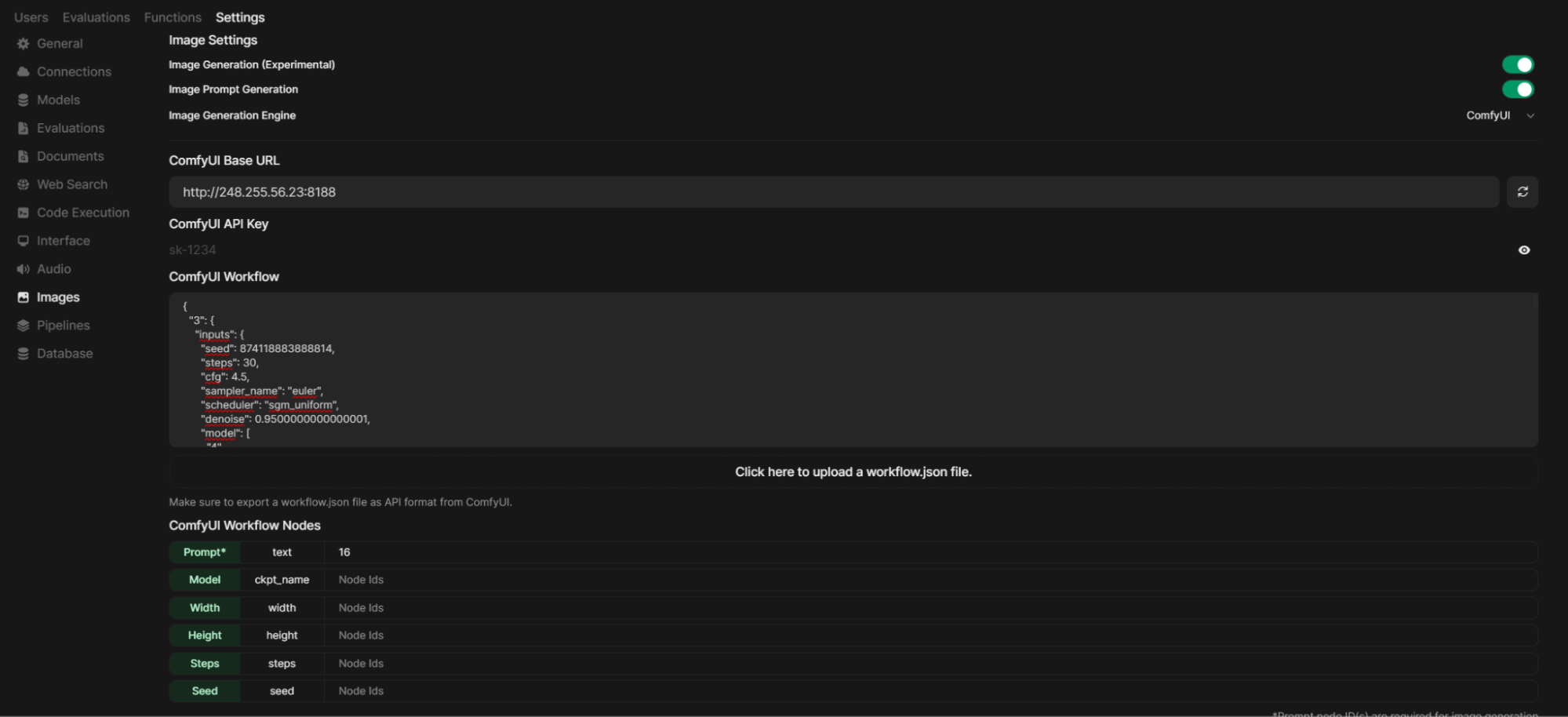
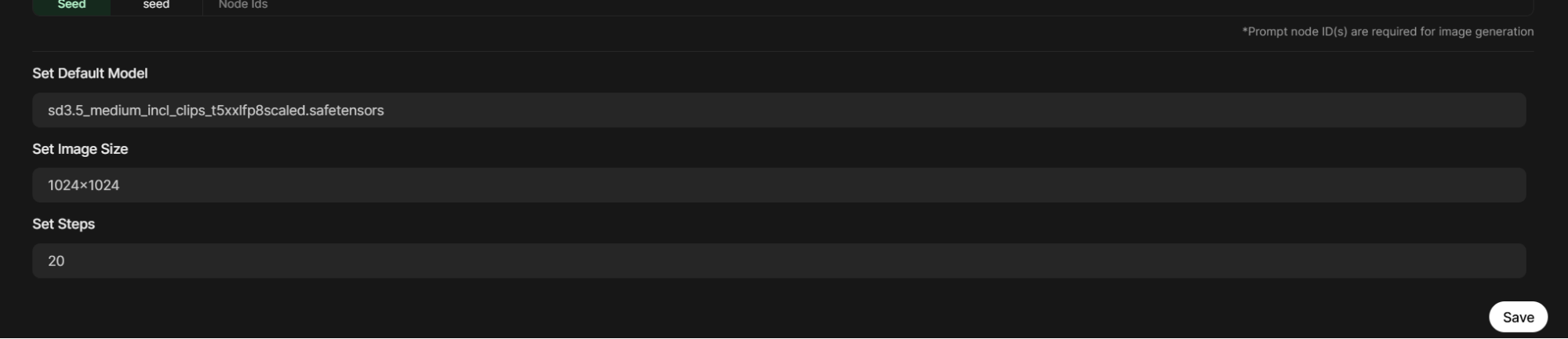
Возвращаемся вниз. В Set Default Model выбираем нашу модель sd3.5_medium_incl_clips_t5xxlfp8scaled.safetensors. В Set Image Size ставим 1024x1024 или другой кратный размер генерации:
1:1 - 1024 x 1024
5:4 - 1152 x 896
3:2 - 1216 x 832
16:9 - 1344 x 768
В Set Steps устанавливаем число проходов генерации. Рекомендуем его поставить от 20 до 40, в зависимости от мощности вашего видеоадаптера. Обязательно нажимаем на Save в правом нижнем углу, чтобы сохранить наши настройки!
Проверяем работу генерации картинок
Начиная с ветки 0.5.x в OpenWebUI появилось два способа генерации картинок. Разберем их оба.
1 способ. Генерация картинок сразу же по введенному промту. Для этого необходимо в строке запроса к нейросети нажати внизу строки чата кнопку Image и ввести промт для картинки. Сверху строки чата появится предупреждение, что вы находитесь в режиме генерации изображений Generate an Image.
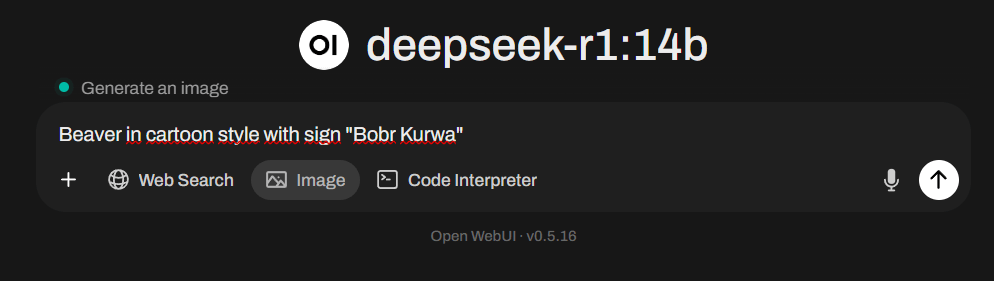
Отправив запрос вы через некоторое время получите изображение от ComfyUI.
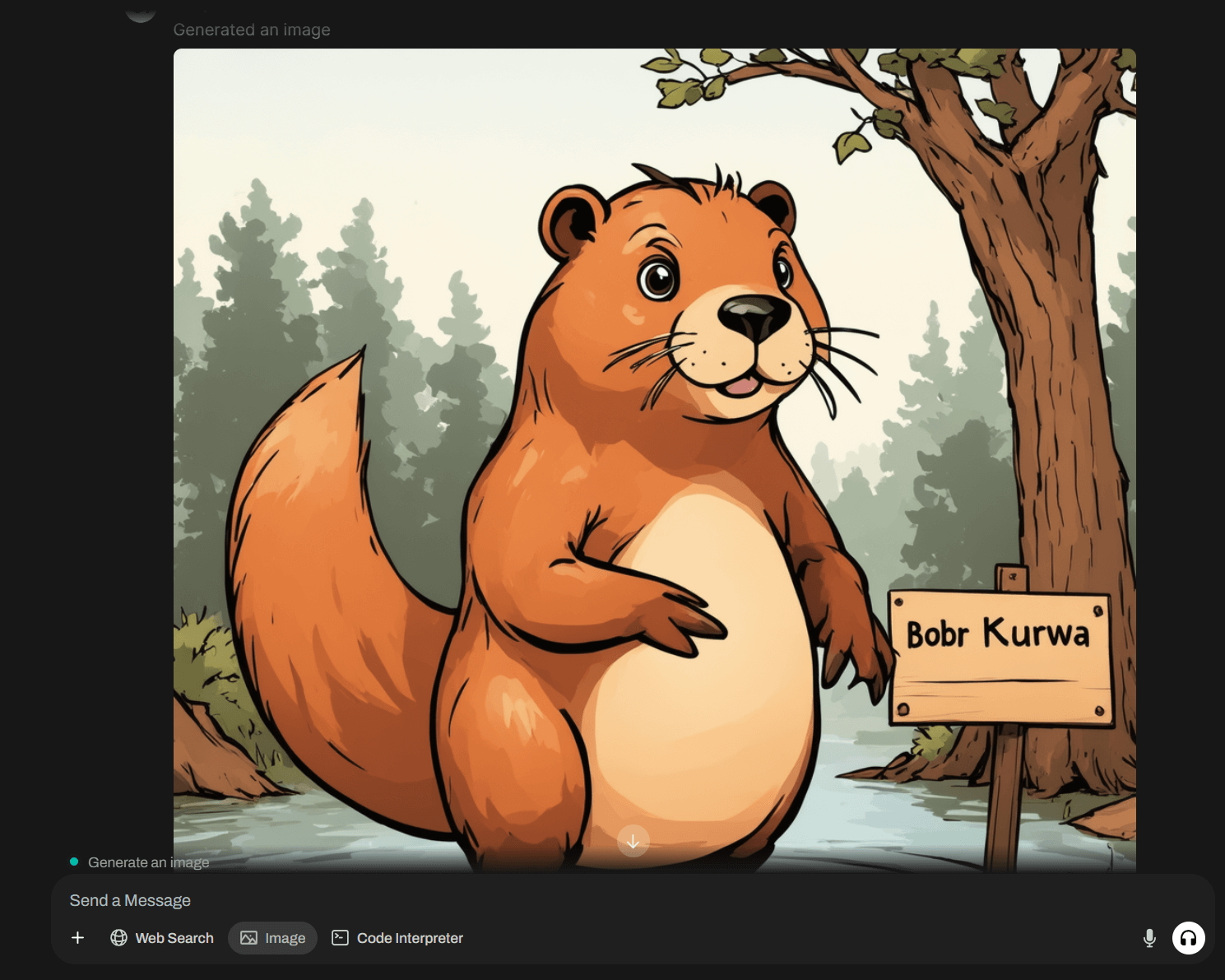
Пока вы снова не нажмете кнопку Image, вы будете находиться в режиме непосредственной генерации картинок по промту.
2 способ. Генерация по ответу нейросети. В этом режиме вы, как обычно, общаетесь с моделью в чате. Например, вы можете попросить ее написать промт или улучшить его. Получив ответ от нейросети, нажмите на значок Generate Image в строке значков внизу ответа.
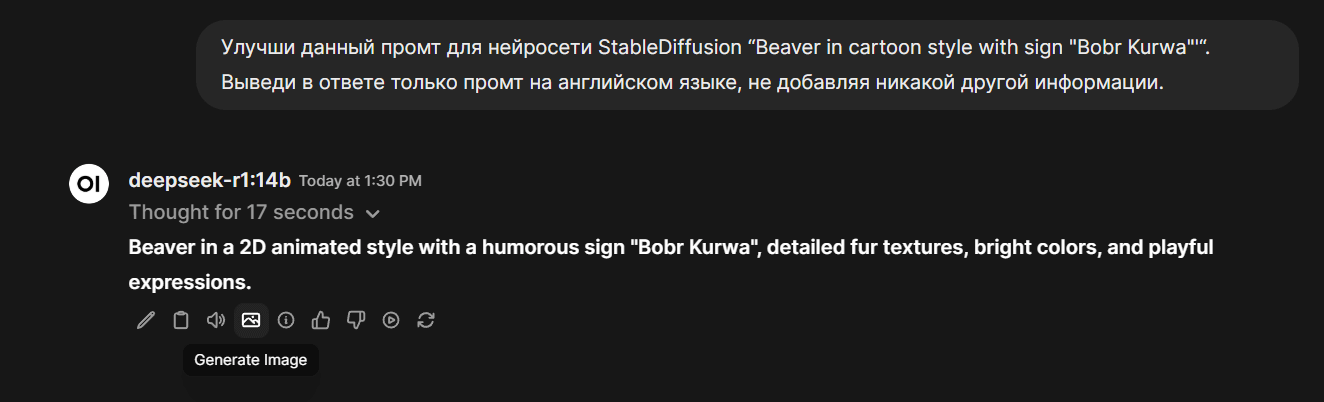
OpenWebUI также пошлет запрос в ComfyUI и выведет вам изображение.

Что мы забыли?
Важный момент - в текущей конфигурации у нас ComfyUI закроется, как только вы закроете командую строку, из которой вы его запустили. Чтобы этого избежать, необходимо поместить ComfyUI в автозапуск. В Linux это проще сделать через сервис systemd.
Для этого, зайдя как root, создайте в директории /etc/system.d/system/ (да, мы знаем, что правильней создавать /usr/lib/systemd/system и потом включать и выключать сервис, создавая данный симлинк) файл comfyui.service со следующим содержимым:
[Unit]
Description=ComfyUI Service
After=network-online.target
[Service]
ExecStart= python3 /root/ComfyUI/main.py --listen 248.255.56.23
Restart=always
RestartSec=3
Environment="PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/cuda/bin"
[Install]
WantedBy=default.target
Потом запустите данный сервис командами
systemctl daemon-reload
service comfyui restart
Проверьте, что все работает, запустив команду
service comfyui status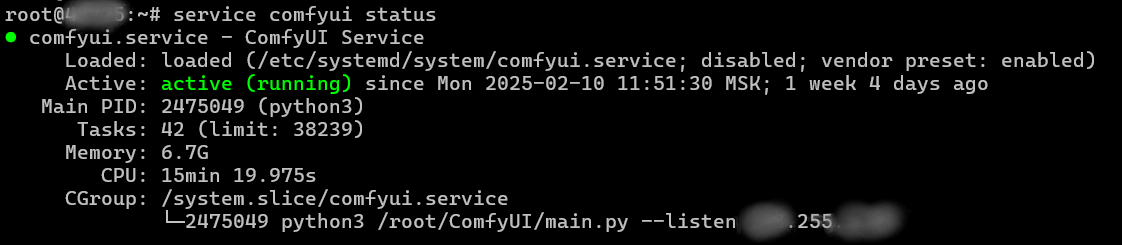
Как видите, добавить поддержку генерации изображений в OpenWebUI не очень сложно, если правильно выполнить всю необходимую последовательность действий. Аналогично вы можете добавить и другие модели или использовать Automatic1111 вместо ComfyUI. В результате вы расширите возможности работы с нейросетевыми моделями и получите замену с открытым кодом проприетарным решениям.