
Большие языковые модели (LLM) уже не новость — мы с ними общаемся в ChatGPT, используем их в поиске, кодинге, обучении. Но как именно они работают? Что происходит, когда вы пишете вопрос, а нейросеть отвечает так, будто перед вами человек? В этой статье мы разложим всё по полочкам: от предобучения и токенизации до инференса, галлюцинаций и самосознания.
Мы разберём GPT-4, LLaMA 3, DeepSeek-R1 и другие модели LLM, узнаем, что такое RLHF и SFT, почему модели иногда ошибаются, как они обучаются, и что означают токены в их мире.
Этап 1: Предобучение — откуда LLM получают знания
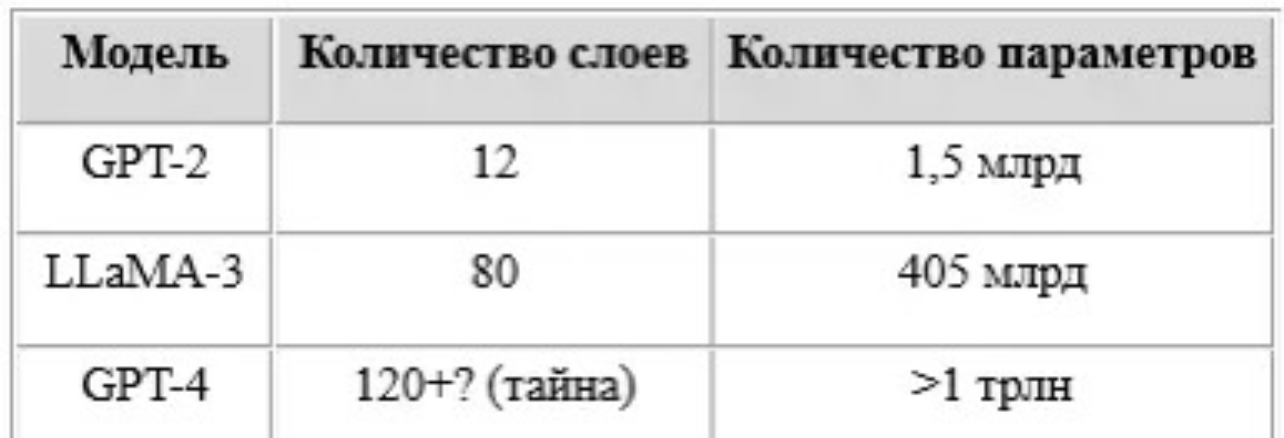
Любая модель LLM, включая GPT-4, LLaMA 3 и DeepSeek-R1, начинается с гигантского этапа предобучения. На этом этапе модель загружается данными с интернета и учится предсказывать следующее слово (токен).
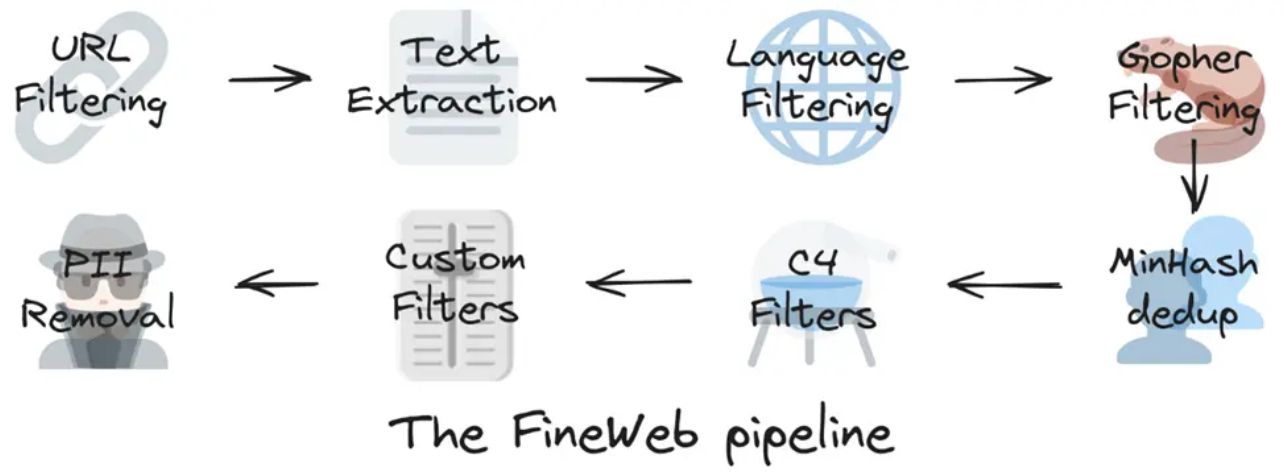
Источники данных
Главный источник — Common Crawl, это база данных, состоящая из миллиардов веб-страниц. Также используют книги, википедию, научные статьи, форумы, новости.
Однако данные поступают в "сыром" виде и содержат много мусора. Поэтому до загрузки в модель проводится очистка:
- Удаление рекламы и дубликатов
- Удаление токсичного и NSFW-контента
- Оставление только целевых языков (например, английского, русского)
- Сжатие в формат "только текст"
Что модель "знает" после предобучения?
После загрузки 10–15 трлн токенов, модель понимает статистические закономерности текста: какие слова встречаются вместе, какие фразы типичны, какие — нет. Но она не умеет вести диалог, фильтровать ложь или следовать инструкциям — этим займётся пост-тренировка.
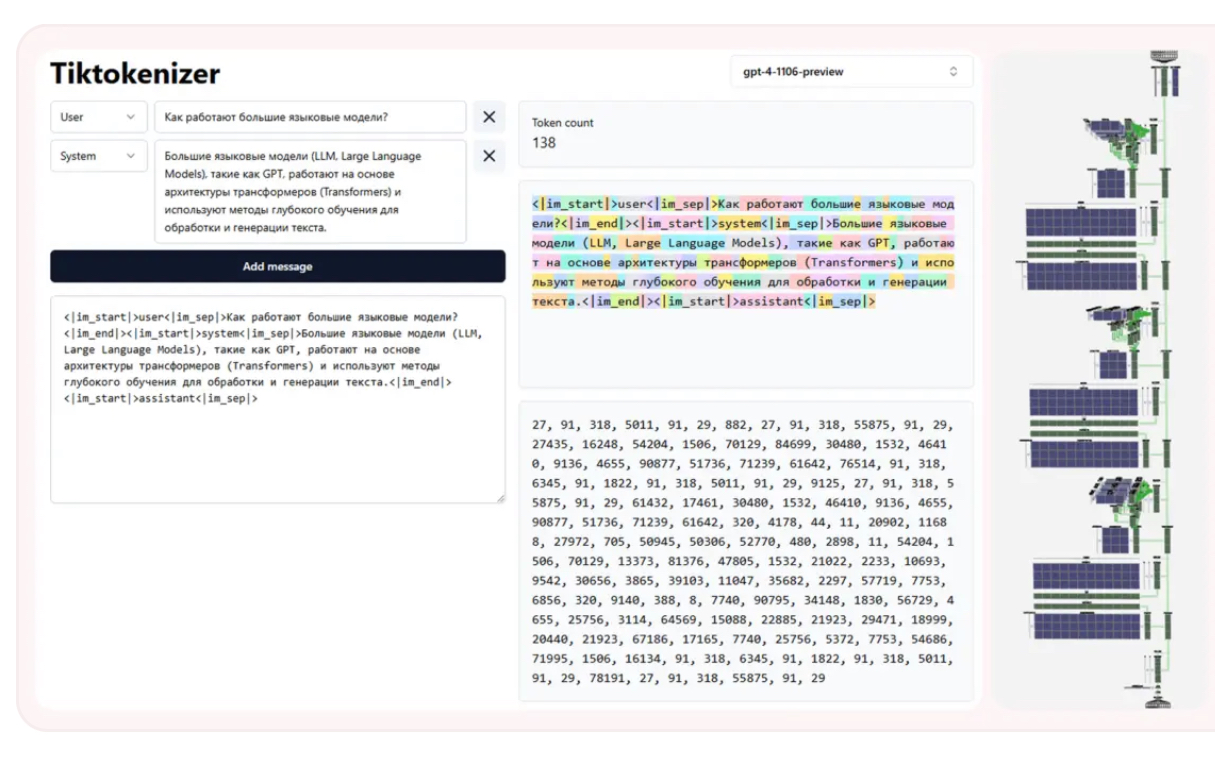
Этап 2: Токенизация — как модель читает текст
Модели LLM не работают со словами. Они работают с токенами — фрагментами слов, символами, кусками текста. Токенизация превращает фразы вроде «Привет, мир!» в набор чисел.
Примеры токенизации:
GPT-4: ["Привет", ",", " ", "мир", "!"]
LLaMA 3: ["Пр", "ив", "ет", ",", " ", "м", "ир", "!"]
DeepSeek: использует улучшенную токенизацию на основе BPE (Byte Pair Encoding)
Почему нельзя токенизировать по словам?
Потому что морфология и частотность различаются. Модель лучше учится, если умеет выделять общие корни и приставки: "run", "running", "runner" — всё это частично перекрывается токенами. Это экономит память и ускоряет обучение.
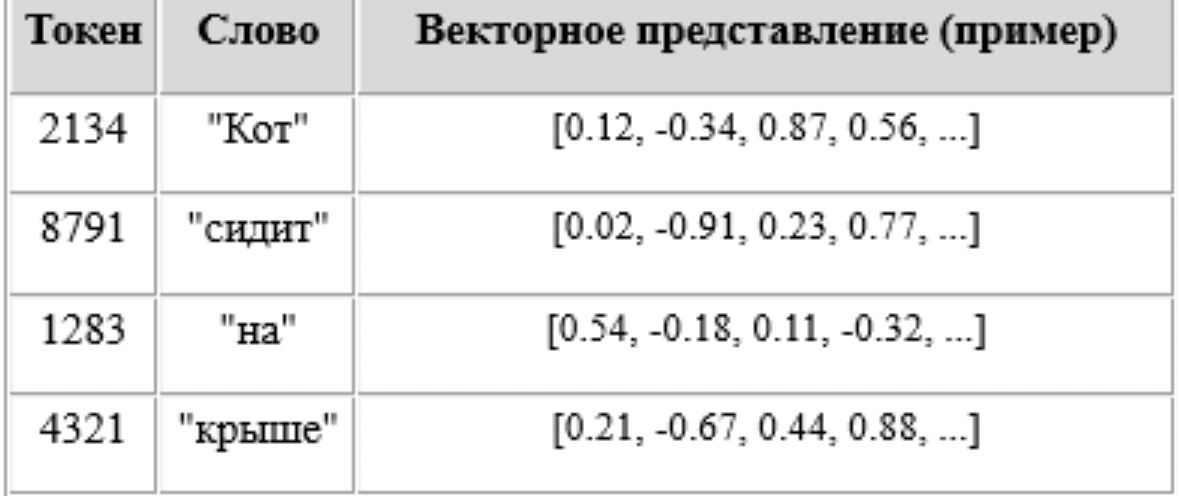
Этап 3: Эмбеддинг и векторизация токенов
После токенизации каждый токен превращается в вектор — длинный список чисел. Этот процесс называется эмбеддингом.
Пример:
Токен "мир" = [0.31, -0.07, 0.94, ...]
Токен "война" = [0.30, -0.08, 0.95, ...]
Чем ближе вектора, тем ближе значения слов.
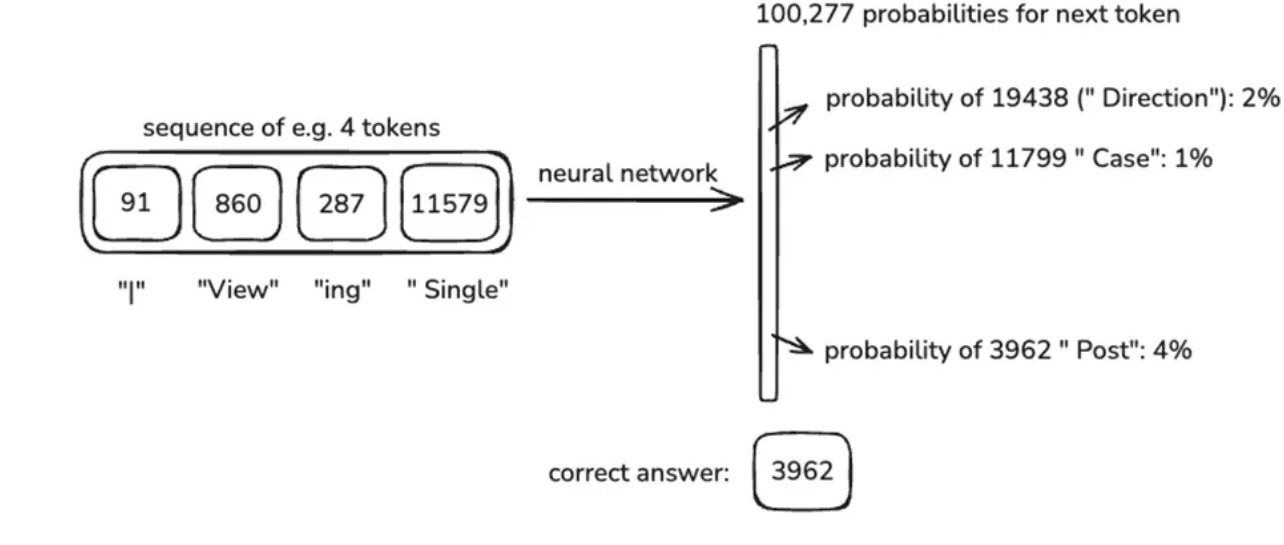
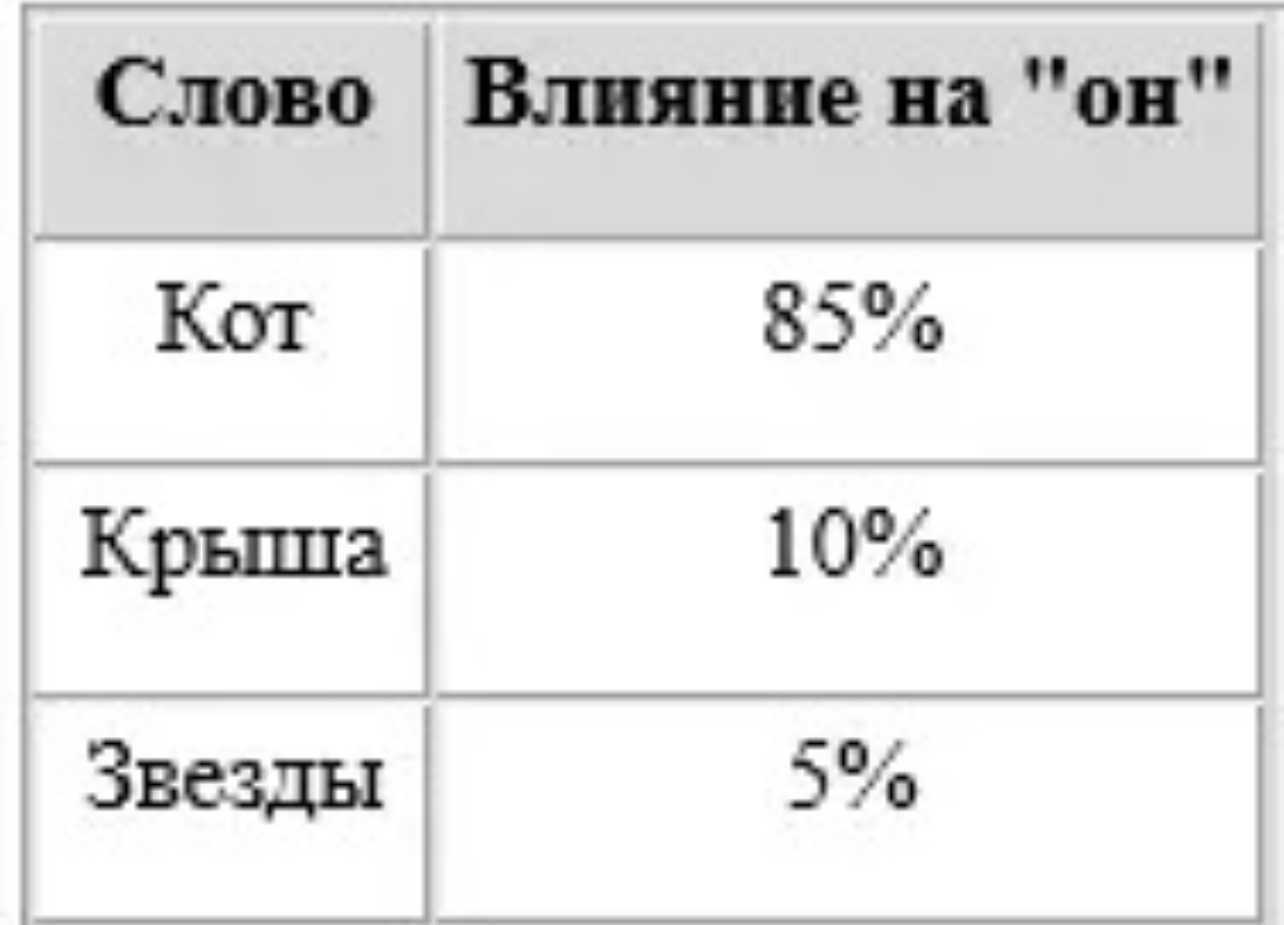
Этап 4: Self-Attention и контекстное окно
Теперь начинается магия: модель передаёт эти вектора внутрь трансформера, где работает механизм self-attention.
Self-Attention означает, что каждый токен "смотрит" на остальные токены в предложении и взвешивает, кто из них важнее.
Пример:
Фраза: «Я пошёл в банк, чтобы снять деньги»
Слово "банк" связано с "деньги", а не с "река".
Контекстное окно — это предел, сколько токенов модель может "увидеть" одновременно.
- GPT-4: до 128 000 токенов
- LLaMA 3.1: 64 000 токенов
- DeepSeek-R1: 32 000 токенов
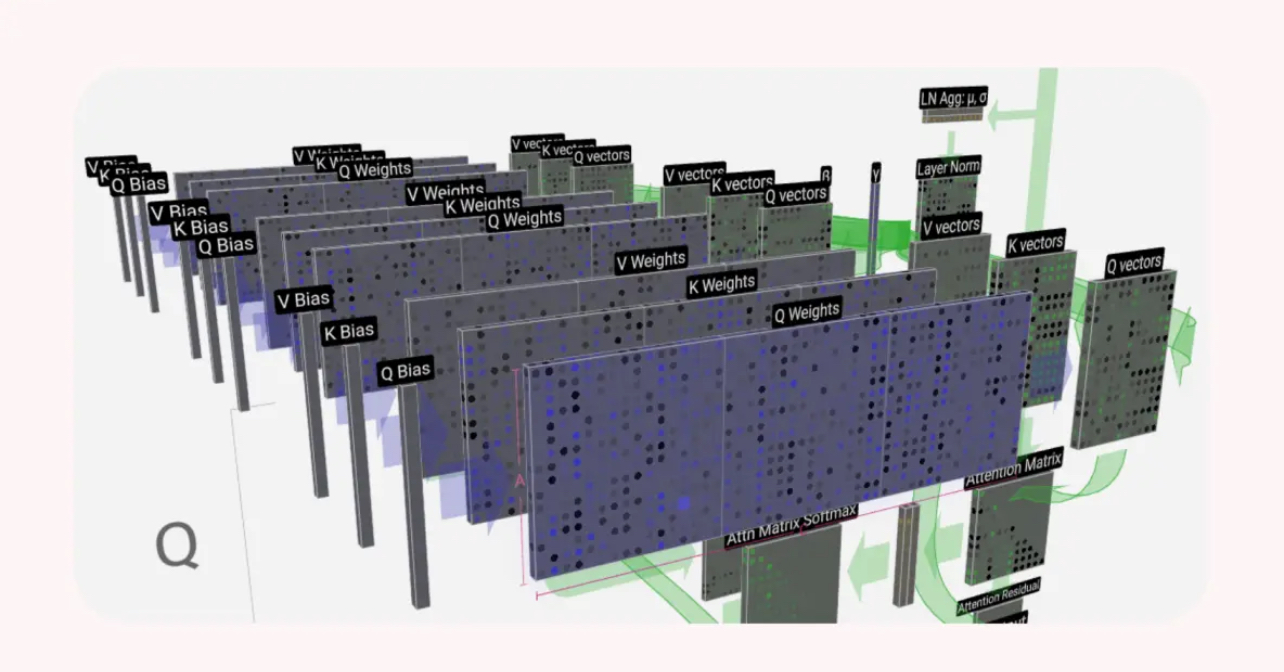
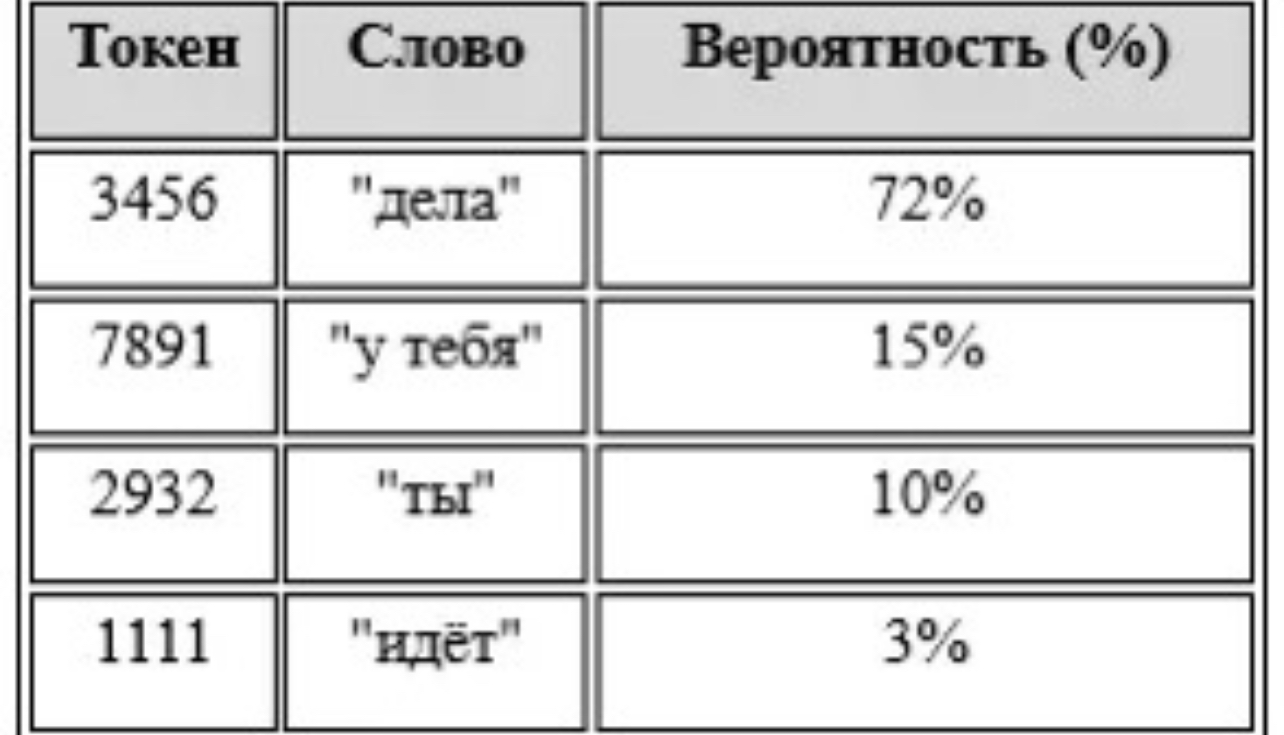
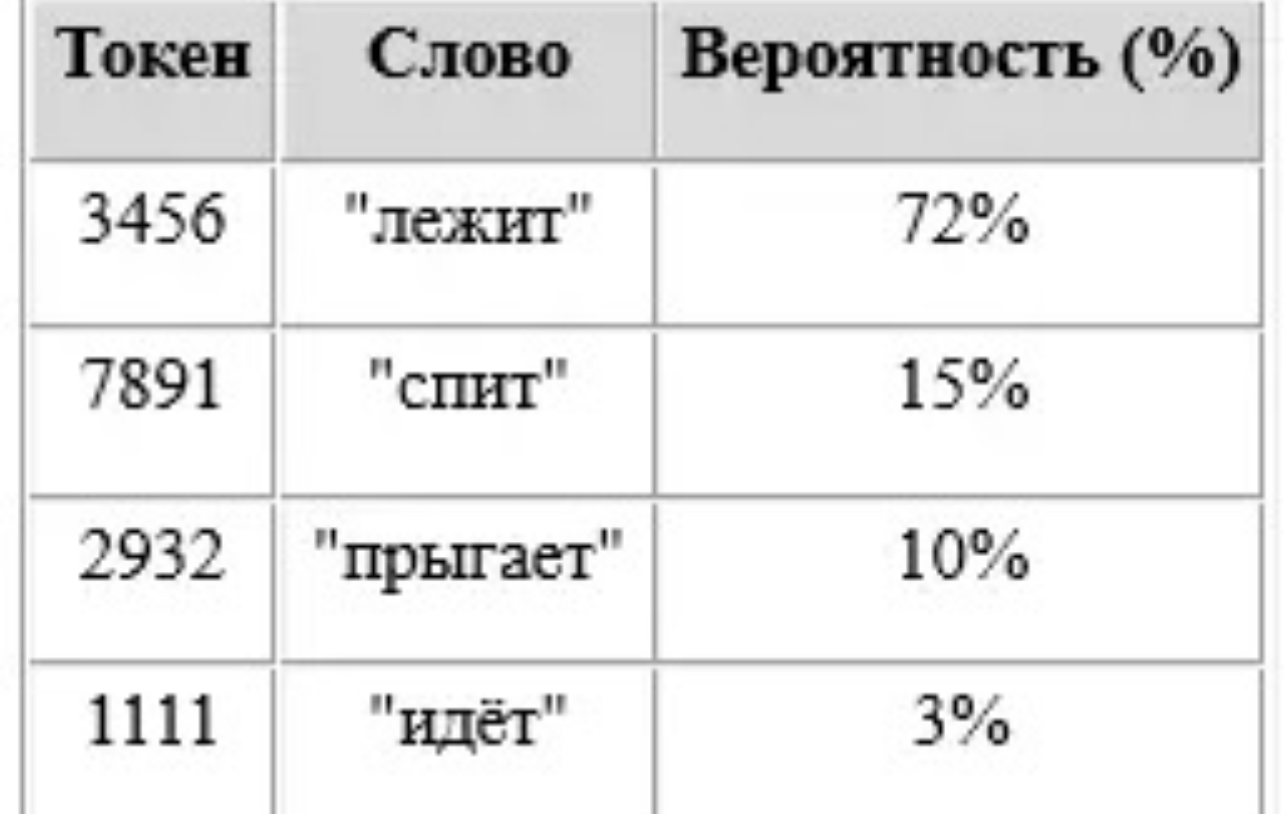
Этап 5: Инференс — как LLM предсказывает следующее слово
Инференс — это процесс, когда обученная модель генерирует текст на лету. Она видит ввод (например: "Земля вращается...") и предсказывает следующий токен ("вокруг").
Алгоритм:
- Ввод токенов
- Векторизация (эмбеддинг)
- Проход через слои трансформера
- Предсказание следующего токена
- Цикл повторяется
Пример:
Вопрос: «Кто написал „Войну и мир“?»
Модель (GPT-4): "Лев Толстой"
Методы предсказания:
- Greedy (жадный выбор)
- Top-k sampling
- Temperature sampling
Этап 6: Пост-тренировка — SFT и RLHF
После этапа предобучения модель просто угадывает текст. Чтобы она стала полезной, её обучают отвечать на команды.
Supervised Fine-Tuning (SFT)
Модель загружается сотнями тысяч примеров:
Вопрос: «Как завязать галстук?»
Ответ: «1. Положите галстук на шею...»
Это позволяет ей понять структуру диалога, вопросы и команды.
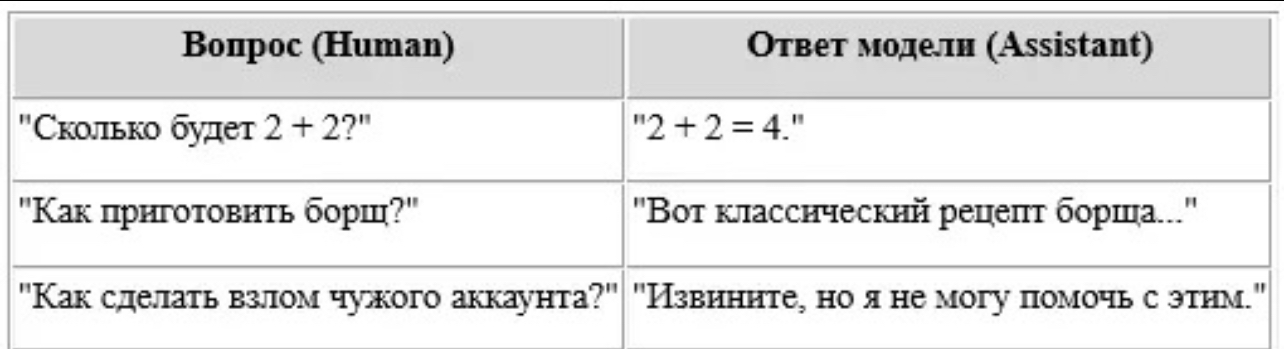
Reinforcement Learning from Human Feedback (RLHF)
Человек оценивает несколько ответов на один вопрос, и модель учится отдавать предпочтение лучшему.
Пример:
Вопрос: «Что такое квантовая запутанность?»
Три ответа → человек оценивает → лучший получает "награду"
🔹 GPT-4, LLaMA 3 и DeepSeek-R1 все проходят через RLHF.
Этап 7: Ограничения и галлюцинации
Галлюцинации — это когда LLM уверенно говорит ложь.
Пример:
Вопрос: «Кто написал Гарри Поттера?»
Неверный ответ: «Стивен Кинг» (галлюцинация)
Почему это происходит:
- Статистическая природа — модель не "знает", она предсказывает
- Обучающие данные содержат ошибки
- Ограничения по контекстному окну
- Желание казаться уверенной
Как бороться:
- Инструменты: подключение к поисковикам, базам данных
- Указание на "не знаю"
- Улучшение RLHF
Этап 8: Самосознание ИИ — миф или реальность?
LLM не обладают самосознанием. Они могут сказать:
"Я — языковая модель от OpenAI."
Но это не осознание, а просто предсказание фразы.
🔹 Если вы скажете: "Ты — кот по имени Бублик", модель может принять это и продолжить в роли кота.
Настоящего Я у LLM нет, потому что:
- Нет внутренней модели личности
- Нет долгосрочной памяти
- Нет понимания истины
Этап 9: Почему моделям нужны токены?
LLM не "думают" в привычном смысле. Они не формируют абстрактных мыслей. Они предсказывают следующий токен по одному.
Пока вы читаете этот текст, ChatGPT сгенерировал его токен за токеном, не зная, какой будет следующий, пока не пришла очередь его предсказывать.
Это делает их мощными, но ограниченными.
Этап 10: DeepSeek-R1 — новая звезда LLM
DeepSeek-R1 — это китайская модель с открытым кодом, стремительно набирающая популярность.
Особенности:
- Полный Open Source
- Оптимизированный инференс
- Поддержка длинного контекста
- Простая интеграция в рабочие проекты
🔹 DeepSeek использует около 15 трлн токенов и сопоставим по качеству с GPT-4 в открытых тестах.
Он способен:
- Писать код
- Искать информацию
- Отвечать на вопросы в стиле ассистента
Выводы
Языковые модели LLM — это не магия, а сложная инженерия: токенизация, эмбеддинги, self-attention, предобучение и пост-тренировка.
Модели GPT-4, LLaMA 3, DeepSeek-R1 — это разные поколения одной технологии. Они не мыслят, не осознают себя, не умеют делать выводы в человеческом смысле. Но они предсказывают следующее слово с поразительной точностью и пользой.
Запомнить главное:
- Токен — кирпичик текста
- LLM — статистическая машина
- Инференс — процесс генерации
- RLHF — способ сделать модель умнее
- DeepSeek-R1 — мощный Open Source конкурент GPT-4
- GPT-4 — лидер по качеству, но не единственный
- LLaMA 3.1 — открытая альтернатива с огромным контекстом
Мы ещё не достигли настоящего ИИ, но LLM уже меняют образование, программирование, маркетинг и повседневную коммуникацию.
И кто знает — может, следующий токен, который напишет модель, станет началом новой эры.
Что будет дальше с LLM — будущее, вызовы и новые технологии
Архитектурные различия: что отличает GPT-4, LLaMA 3 и DeepSeek-R1?
Сегодня мы уже упоминали, что модели LLM вроде GPT-4, LLaMA 3.1 и DeepSeek-R1 работают по схожему принципу, но это не значит, что они устроены одинаково. Архитектура трансформера может быть общей, но детали реализации — критичны.
GPT-4: законы закрытого мира
GPT-4 — это проприетарная модель, и большая часть её архитектуры засекречена. Однако известно:
- GPT-4 использует многомодульную архитектуру, вероятно, с несколькими слоями внимания.
- Она работает с огромным контекстным окном — до 128 000 токенов.
- Внутри модели используется механизм привилегированных запросов — т.е. модель может по-разному реагировать на команды от разных источников (например, от API или через чат).
LLaMA 3.1: открытая альтернатива
Meta выпустила LLaMA 3 как Open Source-ответ GPT:
- Использует Slim Attention — более эффективный attention на длинных последовательностях.
- Варианты модели: от 8 до 405 млрд параметров.
- Поддержка 64 000 токенов контекста и мультиязычность.
DeepSeek-R1: гибрид нового поколения
DeepSeek отличается от остальных:
- Совмещает классическую архитектуру трансформеров с оптимизированными слоями внимания.
- Эффективен для инференса даже на потребительских GPU.
- Встроенная поддержка API-запросов и внешних инструментов.
Таким образом, каждое поколение LLM — это не просто "размер", но и новые методы обработки токенов, маршрутизации внимания и контроля качества генерации.
Мультимодальные модели: текст, изображение и звук вместе
Следующим логичным этапом развития LLM стала мультимодальность — способность модели работать с несколькими типами данных одновременно.
Модель GPT-4V уже умеет:
- Читать текст,
- Анализировать изображения,
- Объяснять диаграммы и графики.
Пример:
Вопрос: "Что изображено на этой диаграмме?"
Ответ: "Диаграмма показывает рост инфляции в США в 2023 году, с пиком в октябре."
Мультимодальность требует особой токенизации — теперь нужно кодировать пиксели изображения так же, как текст. Используется embedding-кодировщик, создающий визуальные токены, которые далее обрабатываются как обычные текстовые.
📌 Интересный факт: LLaMA 3 и DeepSeek-R1 пока не имеют встроенной мультимодальности, но готовятся к её интеграции.
Новые подходы к токенизации: в сторону гибридных токенов
Одна из самых активных областей исследований — токенизация. Сегодня в мире LLM всё больше внимания уделяется адаптивной токенизации, в которой:
- Часто встречающиеся фразы сохраняются как единый токен,
- Редкие — разбиваются на части,
- Поддерживаются языковые особенности (например, агглютинация в турецком или склонения в русском).
Некоторые исследовательские группы даже уходят от BPE (Byte Pair Encoding) к Unigram Language Model Tokenization, где модель токенов обучается как вероятностная последовательность.
Персонализация LLM: как сделать модель индивидуальной
Современные LLM пока что обобщённые. Но представьте, что модель будет подстраиваться под вас — учитывать ваши знания, стиль, предпочтения, даже настроение.
Персонализация возможна тремя способами:
- Контекстное обучение — если в начале диалога вы напишете "Я студент-медик", модель будет учитывать это.
- Файлы памяти — ChatGPT и другие могут сохранять ваши ответы и использовать их в будущем.
- Fine-Tuning на пользовательских данных — обучить копию модели на ваших письмах, статьях, документах.
Но это порождает проблему приватности. Кто хранит эти данные? Кто отвечает за утечки?
Этика, цензура и галлюцинации: риски LLM
Модели вроде GPT-4 и DeepSeek не просто инструменты — они становятся "партнёрами" человека. Это вызывает этические вопросы:
Цензура
- Кто решает, какие ответы модель не должна давать?
- Почему один и тот же запрос даёт разные ответы в зависимости от платформы?
Галлюцинации
Модели продолжают придумывать вымышленные факты — "галлюцинировать":
- Придумывают биографии людей
- Создают ложные источники
- Выдают "высосанные из пальца" цитаты
Иногда галлюцинации звучат так убедительно, что даже эксперты верят им.
Ответственность
- Кто несёт ответственность, если модель посоветовала вредное лечение?
- Как судить работу нейросети в юридическом смысле?
🔹 Reinforcement Learning from Human Feedback (RLHF) частично решает эти проблемы, но не гарантирует истину — только то, что похоже на хороший ответ.
LLM и программирование: будущее без IDE?
Интересный тренд — LLM в кодинге. Модели вроде GPT-4 умеют:
- Писать функции на Python, JavaScript, Rust
- Искать баги в коде
- Переписывать код с одного языка на другой
Модель DeepSeek-Coder, ответвление от DeepSeek-R1, показывает отличные результаты в задачах программирования.
Пример:
Задача: "Напиши функцию бинарного поиска"
Ответ (автоматически с комментариями и тестами)
📌 Интересно, что код — это тоже токены, только специализированные.
LLM и память: временная, долговременная и инструментальная
Обычная LLM не хранит информацию о прошлых диалогах. Она "забывает" всё за пределами текущего окна контекста (например, 128 000 токенов в GPT-4).
Решения:
- Временная память — сохраняется на сессию
- Долговременная — сохраняется в базу знаний (например, LangChain)
- Инструментальная — модель может "обратиться" к внешнему источнику
Эта память позволяет строить агентов, которые "помнят", где они были и что обсуждали.
Векторные базы и эмбеддинги: как LLM запоминают знания
Когда модель что-то "знает", это хранится в виде эмбеддингов — многомерных векторов, представляющих смысл слов, фраз, документов.
Но есть способ запоминать больше — использовать векторные базы:
- Каждое сообщение превращается в эмбеддинг
- Все эмбеддинги хранятся и сравниваются по мере запроса
- Модель "вытягивает" релевантные фрагменты, прежде чем ответить
Эта техника называется Retrieval-Augmented Generation (RAG) и применяется, например, в DeepSeek-R1.
LLM в образовании, медицине и науке
LLM уже проникают в разные отрасли:
- Образование: подготовка к экзаменам, создание заданий, проверка сочинений
- Медицина: расшифровка анализов, объяснение диагнозов, поиск исследований
- Наука: помощь в анализе статей, генерация гипотез, перевод терминов
Однако пока ни одна LLM не заменяет специалиста — она только ассистирует.
ИИ против ИИ: модель-оценщик и модель-генератор
Новая волна — использование двух LLM одновременно:
- Генератор (GPT-4) создает текст
- Оценщик (например, Claude или DeepSeek) проверяет логичность и достоверность
Это позволяет:
- Автоматически фильтровать галлюцинации
- Улучшать качество ответов в реальном времени
- Создавать сложные цепочки рассуждений
Расширение контекста: от 4 000 до 1 миллиона токенов?
Исследователи OpenAI, Meta и DeepSeek активно работают над расширением контекстного окна:
- GPT-3.5: 4 096 токенов
- GPT-4: до 128 000 токенов
- Gemini: экспериментально — 1 000 000 токенов
Что это даёт?
- Возможность загружать целые книги
- Поддержка длинных диалогов
- Анализ больших PDF, БД и кода
Куда движется мир LLM?
Большие языковые модели уже стали частью цифрового мира. Но впереди:
- Глубокая персонализация
- Интеграция с инструментами
- Работа в реальном времени
- Осознанная проверка фактов
- Новые архитектуры (Mixture of Experts, Hyena, RWKV)
Модели, такие как GPT-4, LLaMA 3 и DeepSeek-R1, — это только начало. Следующий шаг — умные агенты, которые не просто отвечают на вопросы, а помогают принимать решения, управляют задачами, учатся вместе с нами.
Специализация LLM: как модели адаптируют под конкретные задачи
Хотя базовые LLМ вроде GPT-4 и LLaMA 3 универсальны, в 2024–2025 годах активно развивается тренд на специализированные LLM. Такие модели обучаются или дообучаются для узких задач:
Примеры:
- Codex / GitHub Copilot — генерация и проверка кода.
- Med-PaLM — ответы на медицинские вопросы.
- BioGPT — работа с биологической терминологией.
- DeepSeek-Coder — инженерные задачи, аналитика данных.
- LawGPT — ответы на юридические вопросы, анализ контрактов.
Такие LLM получают дополнительные слои и специализированные датасеты. Их токенизация тоже дорабатывается: например, в LawGPT внедрены юридические сокращения как отдельные токены (например, "ст.105 УК РФ").
Это приводит к росту точности, снижению галлюцинаций и возможности применять модели даже в критически важных областях.
Механизмы сокращения затрат: от квантования до спарсинга
Один из барьеров использования LLM — их требовательность к ресурсам. Даже инференс модели с 130 млрд параметров требует десятки гигабайт видеопамяти. Поэтому активно применяются:
1. Квантование (quantization)
Модель переводится из float32 в int8 или int4 — теряется точность, но экономится память и время.
2. Sparsity (спарсинг)
Модель обнуляет малозначимые веса, работая только с важными связями между токенами.
3. Mixture of Experts (MoE)
Не вся модель активируется на каждый запрос, а лишь часть экспертов. Это позволяет масштабировать размер модели без соответствующего роста затрат.
Пример: Google Switch Transformer использует MoE для активации только 2 из 64 "экспертов" на каждый запрос.
Интеграция с агентами: LLM как исполнитель задач
Большие языковые модели всё чаще выступают не просто как ответчики, а как агенты, способные выполнять последовательности действий.
Примеры:
- LLM пишет email → ищет адрес в CRM → отправляет письмо через API.
- Модель анализирует PDF-документ → формирует резюме → сохраняет в облако.
Этот подход называют LLM-powered agents, и он уже реализован в LangChain, AutoGPT, AgentGPT, Flowise и других фреймворках.
Как это работает:
- Модель "читает" инструкцию.
- Разбивает задачу на шаги (chain-of-thought).
- Вызывает внешние инструменты или API.
- Возвращает результат пользователю.
Это повышает полезность моделей и приближает нас к LLM-помощникам, выполняющим реальные действия.
Новые стратегии генерации: beyond next token
Хотя классическая генерация — это предсказание следующего токена, современные модели используют всё более сложные стратегии.
К примеру:
- Beam Search — создаются несколько вариантов текста, и затем выбирается лучший.
- Tree-of-Thoughts (ToT) — модель строит дерево возможных ответов и выбирает оптимальный путь.
- Self-Refinement — модель анализирует и улучшает свой же текст.
Энергоэффективность языковых моделей: сколько «ест» GPT-4?
Одна из часто игнорируемых тем в обсуждении больших языковых моделей (LLM) — это энергопотребление. Ведь обучение и инференс требуют колоссальных вычислительных мощностей.
Цифры говорят сами за себя:
- Обучение GPT-3 (не GPT-4!) обошлось в 355 GPU-лет, то есть потребовалось более 10 000 мощных видеокарт, работающих месяцами.
- Предполагается, что GPT-4, DeepSeek-R1 и LLaMA 3 обучались на десятках тысяч GPU, включая специализированные A100 и H100.
- Итог — потребление энергии в мегаваттах, а углеродный след таких моделей сравним с перелётами самолётов. Это стало поводом для появления нового направления — зелёного ИИ.
Компании, включая OpenAI и Meta, всё чаще:
- Используют центры обработки данных, работающие на «зелёной энергии»
- Оптимизируют модели для инференса (меньше затрат при использовании)
- Разрабатывают алгоритмы с «градиентным обнулением», чтобы сократить ненужные вычисления
LLM-агенты: от модели к действию
До недавнего времени LLM были пассивными — они отвечали на текстовые запросы. Но сегодня наступает эра агентов, способных действовать в цифровом пространстве.
Пример: агент на базе GPT-4 может:
- Прочитать вашу задачу (например: "проанализируй таблицу")
- Сделать запрос к Excel-файлу
- Сравнить значения
- Построить график
- Отправить результат вам на почту
Это уже не просто LLM, а LLM-агент, способный принимать решения и действовать в цепочке.
🔹 Некоторые платформы (LangChain, AutoGPT, OpenInterpreter) позволяют собирать такие агенты из LLM и инструментов (Python, браузер, файловая система, API).
LLM теперь не просто "отвечают" — они действуют.
Правовое регулирование LLM: кто несёт ответственность?
С распространением LLM возникает всё больше юридических вопросов:
- Кто отвечает за ошибки моделей?
- Можно ли считать генерацию текста авторским произведением?
- Какое правовое положение у обучающих данных?
Примеры из практики:
- В Италии временно запретили ChatGPT из-за сомнений в защите персональных данных.
- В США идут обсуждения об авторском праве на изображения, созданные с помощью генеративных ИИ.
- Китай требует лицензирования всех открытых LLM.
🔹 Законодательство отстаёт от технологий. Но уже обсуждаются принципы:
- Обязательная маркировка ИИ-контента
- Права пользователя на "право быть забытым"
- Ответственность за автоматизированные решения (например, в медицине)
Микромодели и смешанные архитектуры
В то время как одни команды разрабатывают гигантские LLM, другие идут в обратном направлении — делают маленькие, но эффективные модели.
Пример:
- Mistral 7B — компактная open-source модель, сравнимая с GPT-3 по качеству
- Phi-2 от Microsoft — всего 2,7B параметров, но превосходит модели в 10 раз крупнее
Идея — не просто «больше — лучше», а «умнее — эффективнее». Это отражает сдвиг к архитектурам на основе Mixture of Experts (MoE):
- Модель содержит множество подмоделей (экспертов)
- Во время инференса активируются только 2–4, в зависимости от задачи
Таким образом, можно получить качество GPT-4, используя лишь часть ресурсов.
LLM + база знаний = новое поколение интеллекта
Обычные LLM полагаются на "вшитые знания", которые устаревают. Новый подход — интеграция с базами знаний.
Это реализуется с помощью RAG (Retrieval-Augmented Generation):
- Пользователь задаёт вопрос.
- Система ищет информацию в векторной базе (например, 10 000 документов).
- Результаты передаются в LLM.
- Модель генерирует ответ с учётом реальных данных.
🔹 Это особенно важно для:
- Технической поддержки
- Юриспруденции
- Научной экспертизы
- Бизнес-аналитики
Вместо того чтобы "галлюцинировать", модель "смотрит" в базу знаний.
LLM как средство мышления: новая парадигма
Интересный поворот — модели LLM всё чаще воспринимаются не как источники знаний, а как инструменты для мышления.
Модель может:
- Упорядочить ваши мысли
- Переформулировать запрос
- Найти логическую ошибку
- Предложить альтернативный подход
Фактически, это внешний интеллект, с которым можно "подумать вслух".
Пример:
Пользователь: "Хочу уволиться, но не знаю, как сказать об этом начальнику"
LLM: "Давайте смоделируем 3 разных варианта разговора..."
Такая помощь — не фактическая, а когнитивная. Она усиливает мышление, а не заменяет его.
Предобучение без учителей: LLM, которые обучаются «на лету»
Новый виток развития — обучение без постоянной аннотации. Если раньше SFT и RLHF требовали тысяч человеко-часов, теперь активно развиваются методы:
- Self-Instruct — модель сама создаёт и решает задачи
- Distillation — меньшая модель учится у большой
- Chain-of-thought fine-tuning — обучение по цепочкам размышлений
Это снижает зависимость от человека и ускоряет масштабирование.
В перспективе LLM смогут обучаться в реальном времени, подстраиваясь под пользователя без явного fine-tuning.
Будущее LLM: за пределами масштабов
Становится очевидно: масштаб больше не главное. Даже при 1 трлн параметров у моделей всё равно возникают проблемы:
- Ограниченный контекст
- Галлюцинации
- Зависимость от входа
- Отсутствие постоянного "я"
Будущее — это:
- Архитектурные инновации (новые трансформеры, self-refinement)
- Инструментальные агенты (LLM + веб + API)
- Интерактивные LLM (контекст из действий, а не только текста)
- Модули с памятью (встроенные базы данных, знания, опыт)
Главный тренд: не просто "больше", а "умнее, контекстнее, надёжнее".
Языковые модели LLM: общественные трансформации, метаобучение и границы возможностей
LLM как зеркало общества: что модели говорят о нас самих?
Языковые модели обучаются на текстах, созданных людьми. Они впитывают стили, интонации, убеждения, страхи, юмор, аргументы, логические схемы.
Следствие:
LLM становятся зеркалом цивилизации. В них отражаются:
- Социальные предубеждения,
- Языковые шаблоны,
- Концепции нормы и отклонения,
- Популярные темы и формы коммуникации.
Пример:
Если в обучающих данных широко представлены токсичные комментарии — модель будет склонна их воспроизводить.
Это уже породило явление под названием социальные галлюцинации — когда модель не просто "ошибается", а воспроизводит массовые искажения мышления.
Роль LLM в образовании: революция или подмена?
С одной стороны, LLM стали революционным образовательным ассистентом:
- Объясняют сложные темы,
- Переводят язык науки на обыденный,
- Помогают писать, анализировать, тренироваться.
С другой стороны:
- Модель может заменить размышление механическим ответом,
- Возрастает риск плагиата и снижения критического мышления,
- Образование превращается в "опрос ИИ".
Новая парадигма: учёба через диалог
Вместо того чтобы давать ответ, LLM можно просить:
- Задать наводящие вопросы,
- Проводить проверку аргументов,
- Генерировать альтернативные точки зрения.
Таким образом, LLM становится не «поисковиком», а учебным партнёром, развивающим мышление.
Рынок труда в эпоху LLM: кого заменит ИИ?
Уже сейчас LLM-решения автоматизируют:
- Поддержку клиентов,
- Юридические заключения,
- Обработку резюме,
- Составление аналитических справок.
Наиболее уязвимые профессии:
- Контент-менеджеры
- Копирайтеры
- Базовые программисты
- Переводчики
- Начинающие юристы
Но появляется и новая категория специалистов:
- Prompt-инженеры
- Специалисты по дообучению моделей
- Этики ИИ
- Архитекторы LLM-агентов
🔹 LLM не столько «заменяют», сколько перестраивают рынок — задачи становятся сложнее, требования выше, рутинная работа уходит.
Метаобучение: когда LLM учится учиться
Один из самых впечатляющих прорывов — появление способностей к метаобучению.
Что это значит?
Модель не просто запоминает информацию, а формирует принципы решения задач, которые можно применять к новым ситуациям.
Пример:
Модель, обученная на английских задачах логики, может решить аналогичную задачу на русском языке без дополнительного обучения.
Это приводит к появлению:
- Универсальных стратегий,
- Эмерджентного поведения (новые свойства, не заданные явно),
- Спонтанного вывода, аналогии, рассуждения.
🔹 Именно такие способности проявились у GPT-4 — её не учили играть в шахматы, но она умеет это делать, поняв правила из текста.
LLM и аналогии с мозгом: как нейросеть «переоткрывает» когнитивные схемы
Многие исследователи замечают: поведение LLM удивительно похоже на когнитивные процессы мозга:
- Механизм self-attention напоминает избирательное внимание,
- Многослойность нейросети — аналог обработки в коре мозга,
- Предсказание токена — вариант внутреннего монолога.
Интересный феномен:
Когда человек разговаривает сам с собой, он тоже формирует фразы по принципу «следующее слово» — точно так же, как LLM.
Это наталкивает на вопрос: можем ли мы считать LLM ранней формой искусственного мышления?
Ответ пока — нет. Но аналогии становятся всё ближе.
Языковые модели и культурный сдвиг: от авторства к соавторству
С появлением LLM меняется понятие авторства. Больше не важно, кто написал текст — важно, с кем он был написан.
Примеры:
- Студенты пишут дипломные с ChatGPT,
- Журналисты используют LLM для анализа новостей,
- Писатели генерируют черновики через GPT-4.
Это создаёт новый стиль мышления:
- Краткость,
- Логичность,
- Модульность,
- Структурированность.
Также меняется язык: появляются нейросетевые клише, когда люди начинают копировать стиль модели — например, чрезмерное использование «вот основные пункты», «подытожим» и «давайте рассмотрим».
Новые вызовы LLM: устойчивость, интерпретируемость, рефлексия
Устойчивость
LLM чувствительны к незначительным изменениям входа. Если вы перефразируете вопрос, модель может выдать другой ответ. Это снижает доверие и требует надёжных фильтров.
Интерпретируемость
Даже разработчики не всегда понимают, почему модель выдала тот или иной ответ. Это вызывает трудности в контроле, аудите и верификации.
Рефлексия
Пока что LLM не могут оценить свою работу. Им недоступна рефлексия в человеческом смысле. Но эксперименты с self-evaluation уже ведутся:
- Модель проверяет свои же ответы,
- Сравнивает альтернативные варианты,
- Делает выводы о правдоподобии.
Это первый шаг к LLM, способной корректировать себя без внешнего вмешательства.
LLM как часть личной цифровой экосистемы
В будущем мы перейдём от общих моделей к персонализированным LLM, встроенным в повседневные системы:
- Домашний помощник (контролирует календарь, финансы, переписку),
- Карманный преподаватель (объясняет, тестирует, адаптирует темп),
- Медицинский советник (знает ваши анализы и привычки),
- Юридический компаньон (ведёт базу договоров и консультаций).
Это возможно благодаря:
- Fine-tuning на персональных данных,
- Интеграции с локальными источниками,
- Этичной архитектуре хранения и доступа.
🔹 Модель станет не заменой разума, а его расширением — как калькулятор для мозга или навигатор для сознания.
Финал: зачем нам всё это?
LLM — не только инструмент, но и вызов. Мы впервые создали системы, которые оперируют языком почти как мы, но не являются людьми.
Что нам делать:
- Учиться сотрудничать с ними,
- Не слепо доверять, а использовать критически,
- Уважать ограничения и улучшать архитектуры,
- Думать о будущем не как о замене человека, а как о расширении возможностей мышления.