
С выпуском нового поколения чипов Blackwell для рынка потребительских видеокарт ожидаемо было увидеть версии GPU и для рабочих станций, которые должны были прийти на замену A5000/A6000-серии и быть дешевле, чем GPU уровня A100/H100.
Это и произошло, но при этом Nvidia всех окончательно запутала, выпустив за полгода аж три версии видеокарты RTX PRO 6000 Blackwell. Мы в HOSTKEY к гонке производительности подключились с выходом последней версии, а именно RTX PRO 6000 Blackwell Server Edition, протестировали ее, и нам есть что вам рассказать по итогу (и показать).
* - Карта предоставляется на бесплатный тестовый период на индивидуальных условиях и не во всех случаях.
Что ты такое?
Если смотреть официальные спецификации GPU на сайте Nvidia, то мы видим такую картину:
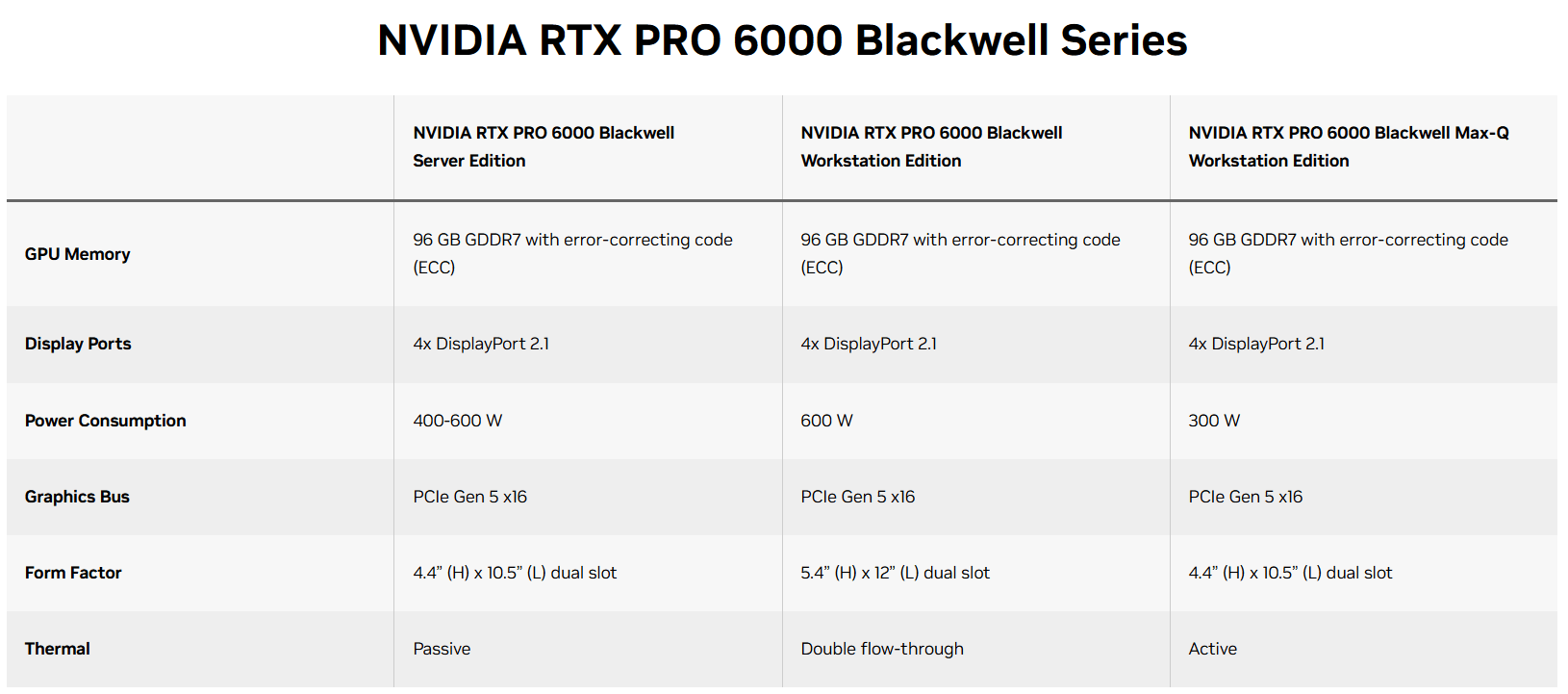
Мы имеем три варианта видеокарт, которые отличаются форм-фактором, типом системы охлаждения и максимальной потребляемой мощностью. Визуально можно предположить, что средняя версия (Workstation Edition) должна быть самой быстрой и самой горячей, судя по потребляемой мощности. Сравним спеки подробней и сравним их с наиболее быстрой RTX 5090D.
|
Workstation Edition |
Max-Q Workstation edition |
Server Edition |
RTX 5090 |
|
|
CUDA Parallel Processing cores |
24064 |
24064 |
24064 |
21760 |
|
Single-Precision Performance (FP32) |
125 TFLOPS |
125 TFLOPS |
120 TFLOPS |
103 TFLOPS |
|
RT Core Performance |
380 TFLOPS |
333 TFLOPS |
355 TFLOPS |
- |
|
Memory Bandwidth |
1792 GB/s |
1792 GB/s |
1597 GB/s |
1792 GB/sec |
|
GPU Memory |
96 GB GDDR7 with ECC |
96 GB GDDR7 with ECC |
96 GB GDDR7 with ECC |
32 GB GDDR7 |
|
Memory Interface |
512-bit |
512-bit |
512-bit |
512-bit |
|
Power Consumption |
Up to 600W (Configurable) |
300W |
600W |
575W |
GPU, который мы тестировали (RTX 6000 Blackwell Server Edition), является самым слабым из линейки (хотя, казалось бы, Server-версия должна быть мощнее Workstation), но всё равно быстрее, чем потребительская 5090, за счет большего числа ядер в чипе. Опять же, по энергопотреблению за счет сниженных частот карта укладывается в 300W, но может за счет переключателя быть переведена в boost-режим, когда работает на частотах, близких Workstation Edition. В режиме 300 Ватт карта холодней, чем RTX 5090, а при разгоне обходит потребительскую версию.

Главная фишка Server Edition — пассивное охлаждение, использующее штатные службы продуваемого серверного корпуса, и за счет своего размера, позволяющее размещать в ряд большое число GPU одновременно (фото с выставки).

Собираем сервер
Тестировать эту видеокарту будем в следующей конфигурации:
- Серверная платформа от ASUS
- Процессор AMD EPYC 9554
- 768 Гб ОЗУ DDR5
- 2x3.84TB NVMe
- 1xRTX 6000 PRO SERVER
Платформа технически позволяет поставить 4 GPU, но из-за энергопотребления в режиме без ограничений по мощности максимум можно поставить две RTX 6000 PRO SERVER. Вся проблема в том, что в данной платформе на каждую сторону по 4 разъема питания, которые подключаются через переходник в карту. Как видно на фото, в корпусе установлены мощные вентиляторы с двух сторон и специальный кожух, что обеспечивает отличную «продуваемость» радиаторов и компонентов GPU.


А теперь тесты
Тестировать мы будем в двух режимах: работа с LLM в связке Ollama + OpenWebUI и генерация видео с помощью свободной модели WAN2 в ComfyUI. А точнее, в нашем нейросетевом помощнике, который задействует сразу несколько моделей для RAG и работает с внешним MCP-сервером. В качестве подопытной LLM выступает Qwen3-14B, который в режиме контекста 16K занимает порядка 14 Гб видеопамяти.
Забегая вперед, скажем, что сравнение по моделям, которые помещаются полностью в GPU, показало примерно 15–20% прироста производительности к RTX 5090, поэтому цифры будем приводить по отношению к другим видеоадаптерам.
Для начала сравним предыдущее поколение в лице A5000 с RTX 6000 PRO. Сравнивать будем в режиме пониженного энергопотребления, где видеокарта на деле пожирает до 450 ватт (буст-режим), а не максимально описанные в документации 300. Напоминаем, что в A5000 стоит 24 Гб GDDR6.
Задаем нашему нейросетевому помощнику следующий вопрос: «Hi. How to install Nvidia drivers on Linux?»
|
GPU |
Скорость отклика, токенов в секунду |
Скорость промпта, токенов в секунду |
Время обработки запроса, сек |
|
A5000 (холодный прогон) |
47.3 |
2700 |
17 |
|
RTX 6000 PRO (холодный прогон) |
103.5 |
8285 |
5 |
|
A5000 (модель уже загружена в GPU) |
48.2 |
2910 |
13 |
|
RTX 6000 PRO (модель уже загружена в GPU) |
107 |
11000 |
4 |
Как видно, по сравнению с A5000, которая до сих пор в деле, новый GPU мощнее в два с лишним раза, а скорость отклика у него (то есть переключение между моделями, поиск и запросы к MCP-серверу, обработка и вывод ответа) быстрее в 3 с лишним раза.
Но использовать RTX 6000 PRO для таких задач — это как колоть орехи микроскопом. Для интереса сравним на такой же задаче с H100 на «горячем» прогоне. У H100 в 3,5 раза меньше CUDA-ядер, меньше частоты и теоретическая мощность примерно в 4 раза в синтетических тестах. Но выигрыш за счет 4 нм техпроцесса против 5 нм у RTX 6000 PRO и в 10 раз большей ширине памяти и ее типе. Хотя самой памяти в нашей версии 80 Гб против 96.
|
GPU |
Скорость отклика, токенов в секунду |
Скорость промпта, токенов в секунду |
Время обработки запроса, сек |
|
H100 (модель уже загружена в GPU) |
60 |
2900 |
4 |
|
RTX 6000 PRO (модель уже загружена в GPU) |
107 |
11000 |
4 |
Как видно, несмотря на двухкратное превосходство RTX 6000 PRO в скорости токенизации, суммарно они идут наравне. Что делает RTX 6000 PRO прекрасной заменой A100/H100 в серверах на инференсе, учитывая, что пропускная способность HBM3 при обмене данными уступает GDDR7. А вот для тренировки или дообучения моделей H100 с ее пониженным энергопотреблением, поддержкой на аппаратном уровне с помощью движка Transformer Engine моделей с точностью FP16/FP8 (H100 только FP4) и ускоренной работой с моделями при их полной загрузке в память (пропускная способность до 3 ТБ/с).
Используем RTX 6000 PRO по полной
Гораздо интересней попробовать эту видеокарту в другой ресурсоемкой задаче — а именно в генерации видео. Для этого будем использовать новую модель от Alibaba с открытыми весами Alibaba и всё это установим в ComfyUI. И у нас здесь опять возникла проблема, а именно CUDA 12.9 (а позже и 13) и ее поддержка в PyTorch. Решением опять же до включения официальной поддержки является установка из ночных сборок:
pip install --pre --upgrade --no-cache-dir torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu129
Используем режим генерации видео по промту (Wan 2.2 14B text to video). Который у нас будет следующим:
A whimsical and humorous scene unfolds on a serene riverbank, where two hardworking beavers in bright yellow safety helmets and rugged orange overalls team up to haul a massive, gleaming server rack toward their meticulously built beaver lodge. The lodge, constructed from logs and stones, features a bold, modern sign reading "HOSTKEY" in bold, tech-inspired typography. The beavers’ determined expressions and the server rack’s glowing lights create a surreal blend of nature and technology. The river sparkles in the sunlight, and the lodge’s entrance is framed by lush greenery, emphasizing the harmony between the beavers’ natural habitat and their unexpected tech-savvy mission. The scene is vibrant, detailed, and filled with playful energy, blending the charm of wildlife with the precision of data infrastructure. Perfect for a lighthearted, tech-themed animation or meme.Запускаем, и сам процесс занимает ~40 минут. Потребление памяти в пиковых режимах и потребляемую мощность видно на следующем скриншоте. Максимальная температура выше 83 градусов не поднималась. Генерация в 720p/24, так как модель позиционируется для него, и установка 1080p или увеличение частоты кадров приводит или к зависанию видеокарты, или генерация может составлять более 2 часов (больше мы не ждали, так как процесс повис на 60%).
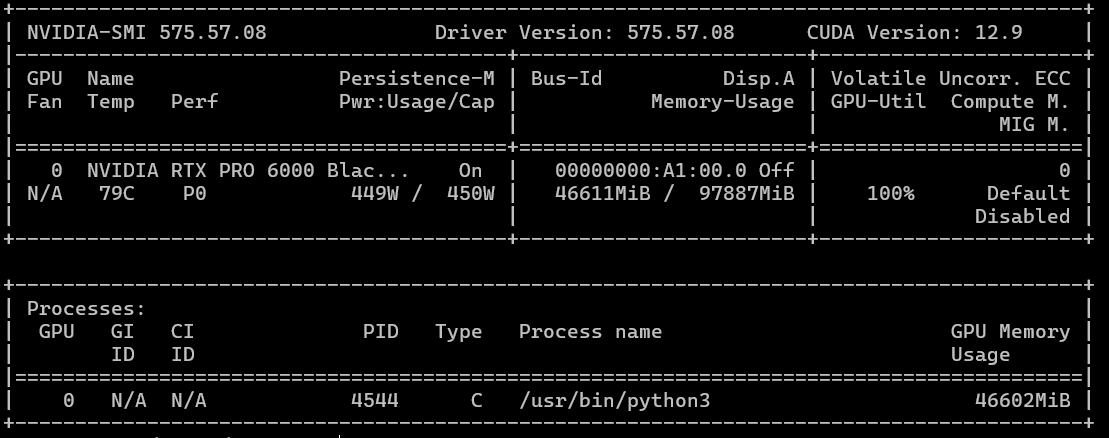

Если же использовать модель WAN 2.2 5B, то генерация похожего видео (видео 5 секунд, 24 кадра) занимает всего 160 секунд.
Добавляем мощности
Как мы упоминали, на данной видеокарте есть переключатель режимов энергопотребления. Если для моделей это не дало сильного прироста, то генерация видео в режиме 600 ватт уже показывает лучшие результаты. Судя по показаниям nvidia-smi, мы смогли выжать из нее еще пять лишних ватт. Но температура в таком режиме может прыгнуть до 90 градусов.
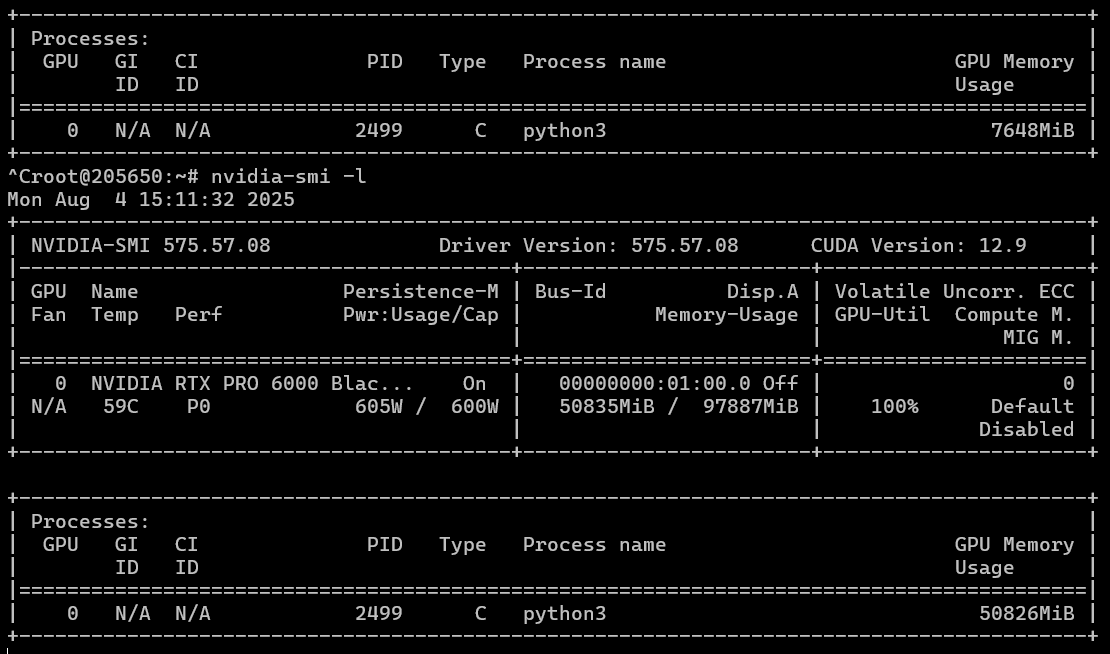
В среднем же энергопотребление в обоих режимах при генерации держится на уровне 200-250 ватт.
Как видно, при увеличении максимальной потребляемой мощности генерация ускоряется на четверть и составляет в среднем 30 минут. Но жертвовать придется температурой чипа и компонентов, и в задачах, которые требуют длительной работы GPU под нагрузкой, лучше их оставить в режиме пониженного энергопотребления.

Выводы
Видеокарта понравилась. Она гораздо стабильнее потребительской 5090, не имеет на борту забиваемых пылью вентиляторов, лучше память с контролем четности, больше частоты. По сравнению с H100 она дешевле в 4 раза, а для задач, не связанных с глубоким обучением нейросетей, дает сравнимые (а то и лучше) результаты. Инференс, работа с графикой и видео будут лучше, чем на предыдущих поколениях, а новая CUDA 13 и последняя 580-я версия драйверов дали еще прирост производительности.
Из минусов стоит отметить отсутствие драйверов (на момент написания статьи) под Windows Server именно для Server Edition. Для Workstation они есть, но при установке выводится сообщение об отсутствии видеокарты. В Linux такой проблемы нет, и мы тестировали ее и в Ubuntu 22.04, и в 24.04. Единственное, что драйвера потребовали для сборки 6 ядро и GCC 12.
* - Карта предоставляется на бесплатный тестовый период на индивидуальных условиях и не во всех случаях.