

В 2006 году Amazon запустил сервис под названием Simple Storage Service (сервис простого хранения). Идея была простая на первый взгляд, дать пользователям интерфейс, в котором можно складывать файлы любого типа, не думая о файловой системе, размере раздела и всём остальном, что обычно идёт в комплекте с дисковым хранилищем. Через девятнадцать лет аббревиатура S3 (сервис объектного хранения) стала фактически нарицательной для целого класса хранилищ. Любой облачный провайдер, который хочет предложить нечто подобное, делает свой сервис «S3-совместимым».
Храните данные, необходимые для работы сервисов: резервные копии, аналитические данные и датасеты для ML.
Любопытно, что сама технология при этом не такая простая, какой кажется по названию. За интерфейсом из трёх HTTP (протокол передачи гипертекста)-методов скрывается распределенная система с собственными решениями по репликации, согласованности и адресации. Многие неочевидные моменты в её работе становятся понятны, только когда сталкиваешься с ними на практике.
Дальше попробуем разобрать, что именно происходит, когда файл «складывается в S3», и почему этот подход стал настолько распространённым. Полностью охватить тему за одну статью не выйдет, поэтому пройдёмся по ключевым местам – устройству, основным компромиссам, типичным сценариям использования.
Что такое S3 хранилище простыми словами
Если убрать маркетинг, S3 представляет собой удаленное хранилище, в которое файлы загружаются и из которого выгружаются по HTTP. Каждый файл получает уникальный идентификатор, по которому к нему можно обратиться. Никакой иерархии папок в привычном виде нет. То, что в интерфейсах выглядит как «папки», на самом деле просто префиксы в именах объектов. Такой подход кажется непривычным после файловых систем, но у него есть причины, до которых я доберусь чуть дальше.
Со стороны разработчика взаимодействие с S3 выглядит примерно так. Есть программный интерфейс приложения (API), в нём несколько основных операций. Положить объект, забрать объект, удалить объект, получить список. На каждый запрос приходит HTTP-ответ. Авторизация происходит через пару ключей, которые подписывают каждый запрос криптографической подписью. Никаких сессий, ничего сложного.
Простота интерфейса обманчива и внутри всё устроено заметно сложнее,. От деталей реализации зависят и скорость, и надежность, и стоимость. Снаружи это всегда одни и те же три-четыре операции, и в этом главная ценность стандарта. Можно написать код один раз и запускать его против любого S3-совместимого хранилища, меняя только адрес сервиса и ключи.
Архитектура S3. Бакеты, объекты, ключи
В S3 три уровня организации данных. Можно представить их как матрёшку.
Аккаунт на верхнем уровне. Это то, что принадлежит пользователю или организации, к нему привязаны ключи доступа и квоты. У одного клиента может быть несколько независимых аккаунтов, и это нормальная практика для изоляции данных разных проектов.
Бакет (bucket) выступает контейнером для объектов внутри аккаунта. У бакета есть имя, и оно должно быть уникальным в пределах всего хранилища, а не только внутри аккаунта. Это интересный момент. Если кто-то зарегистрировал бакет с именем backups, никто другой такой же бакет создать не сможет. Причина в адресации, к которой я сейчас перейду.
Объект включает в себя собственно файл и его метаданные. Под метаданными подразумеваются и стандартные заголовки (тип содержимого, длина, дата изменения), и пользовательские, которые можно прикреплять самостоятельно. У каждого объекта есть ключ. Это строка, которая выглядит как путь, хотя путь условный. images/2024/photo.jpgдля S3 это просто строка-идентификатор. Никаких реальных папок не создаётся.
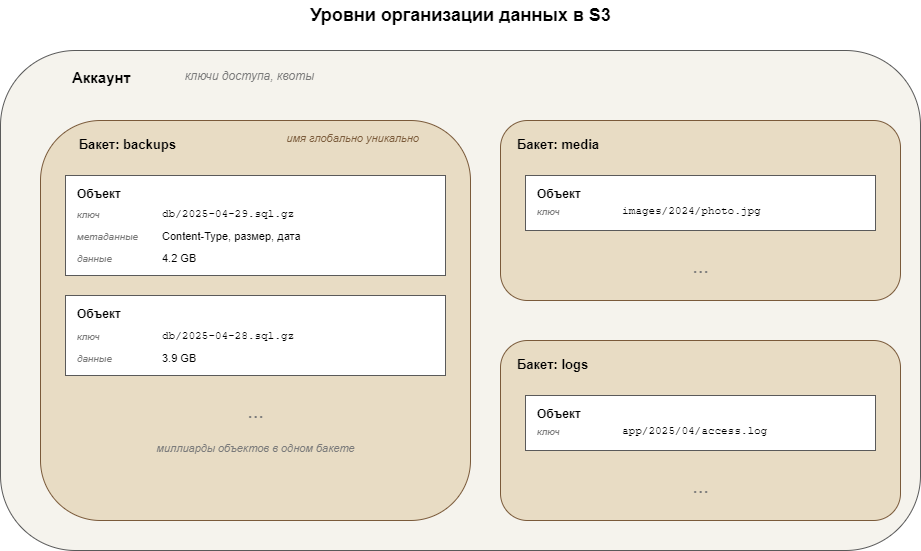
Адресация объекта складывается из трёх частей. Точка входа, имя бакета и ключ объекта. В URL это выглядит примерно так.
https://endpoint/bucket-name/object-keyВозможен и вариант с виртуальным хостом, который тоже допускается стандартом.
https://bucket-name.endpoint/object-key
Из этой схемы сразу понятно, почему имена бакетов уникальны. Они становятся частью адреса, и две точки с одинаковым адресом существовать не могут. Отсюда и жёсткие правила именования в S3 в целом. Только строчные буквы, цифры и дефисы, длина от 3 до 63 символов, нельзя начинать или заканчивать спецсимволами. Имя бакета должно подходить для DNS-записи.
Имена объектов, наоборот, почти не ограничены. Внутрь ключа можно складывать практически что угодно, включая слеши и UTF-8 символы. То, что слеши работают как «папки» в графических клиентах, является условностью графического интерфейса. Когда клиент запрашивает листинг бакета с префиксом images/2024/ и разделителем `/`, он получает объекты, ключи которых начинаются с этого префикса, сгруппированные по символу разделителя. Иллюзия файловой системы возникает на стороне клиента.
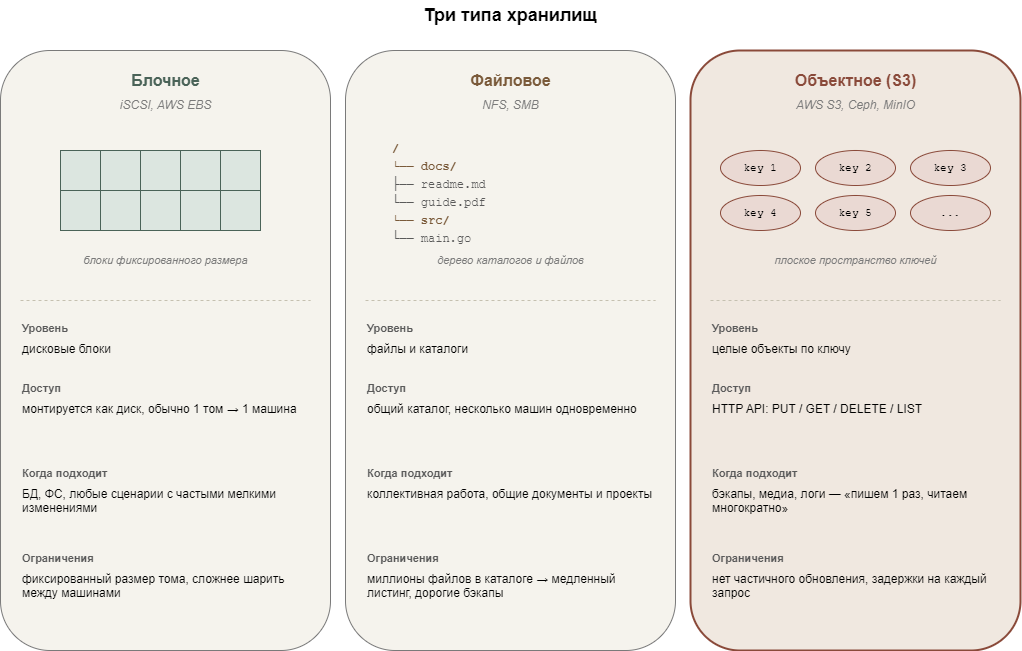
Чем объектное хранилище отличается от файлового и блочного
В этом моменте стоит остановиться, потому что вопрос «зачем нужно ещё одно хранилище, если есть файловая система» самый частый. Если очень коротко, разница в том, на каком уровне хранилище отдаёт данные и как с ним взаимодействуют.
Блочное хранилище работает с дисковыми блоками. Это уровень, на котором операционная система видит «диск». Подключенный по протоколу iSCSI том ничем не отличается от локального диска с точки зрения системы. На нём можно создавать файловые системы, разделы, базы данных, что угодно. Минус в том, что том нужно монтировать, поддерживать и обычно он подключается только к одной машине..
Файловое хранилище оперирует уже файлами и каталогами. Через NFS или SMB можно подключить общий каталог, в котором несколько машин одновременно работают с одними и теми же файлами. Привычная парадигма, удобная для коллективной работы. У файловых систем есть свои пределы. Когда в каталоге появляются миллионы файлов, операции вроде листинга начинают тормозить, метаданные занимают непропорционально много места, бэкапы становятся дорогими.
Объектное хранилище работает с целыми объектами. Достать или положить объект можно только целиком, хотя для больших файлов есть загрузка по частям, при которой файл разбивается клиентом на куски и собирается обратно на стороне сервиса. Архитектура изначально рассчитана на горизонтальное масштабирование, и количество объектов в бакете практически не ограничено — миллионы и миллиарды это нормальные числа, а не граничные. Доступ к конкретному объекту по его ключу остаётся быстрым при любом масштабе.
Из этого следует не очень очевидный вывод. S3 плохо подходит там, где нужны частые мелкие изменения существующих данных. Скажем, под базу данных PostgreSQL объектное хранилище класть бессмысленно, потому что СУБД работает на уровне блоков и постоянно меняет небольшие участки файла. Каждое такое изменение в S3 фактически означает перезапись объекта целиком. Зато S3 отлично работает там, где данные пишутся один раз и потом читаются. Бэкапы, медиафайлы, логи, статические сайты, всё это сценарии «пишем один раз, читаем многократно или один раз».
Граница между «подходит» и «не подходит» проходит примерно по этому водоразделу. Не по объёму данных, не по типу файлов, а по характеру операций.
Как работает S3 изнутри
С внешним API всё понятно. Что происходит, когда запрос доходит до сервера? Здесь начинается самое интересное, и заодно самое неоднозначное, потому что конкретная реализация зависит от провайдера. У AWS это закрытая система, которую можно изучать только по белым книгам и публикациям. Большинство S3-совместимых хранилищ построены на одном из открытых решений. Чаще всего это Ceph, MinIO или SeaweedFS. Дальше будет удобно говорить о конкретной реализации, поэтому возьмём Ceph. Запрос клиента сначала попадает на шлюз, который называется RADOS Gateway. Шлюз анализирует S3 API, проверяет подпись запроса и переводит его в операции внутреннего протокола кластера. Дальше работает сам кластер, в котором данные распределены по множеству узлов хранения.
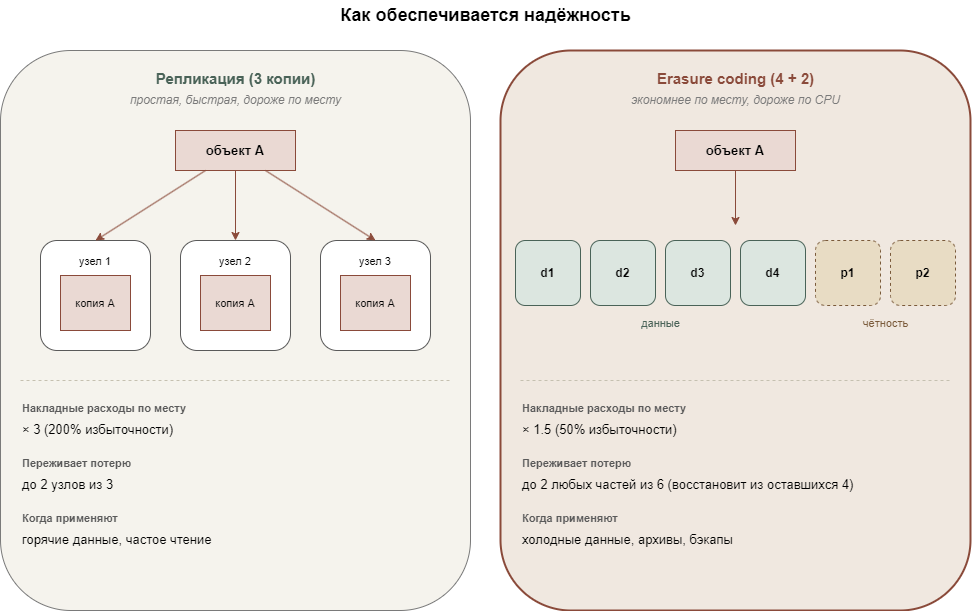
Если шлюз это вход, то распределение данных это уже сама кухня. Когда объект попадает в кластер, он не лежит просто на одном диске. Он разбивается на части, и каждая часть копируется на несколько узлов сразу. Сколько именно копий, определяется политикой репликации. Стандартный вариант предполагает три копии. Если один из узлов выйдет из строя, данные всё ещё доступны на других. Кластер при этом отслеживает состояние реплик и автоматически восстанавливает их при сбоях.
Альтернативный подход называется кодированием с исправлением ошибок (erasure coding) и работает примерно как RAID 5 для распределенных систем. Объект делится на N частей данных и K частей контрольных сумм. Чтобы восстановить объект, достаточно любых N из (N+K) частей. Erasure coding экономит место по сравнению с полной репликацией, но дороже по нагрузке на CPU при чтении и записи. Поэтому его обычно используют для редко запрашиваемых данных, а горячие данные оставляют на простой репликации.
Заявленная надежность облачных хранилищ часто описывается формулой «11 девяток после запятой». Это значит, что вероятность потери одного объекта в год составляет порядка 10⁻¹¹. Цифра красивая, но это статистическая модель, основанная на предположениях о частоте отказов оборудования и времени восстановления. Реальная надежность зависит от того, как именно настроен конкретный кластер. У одного провайдера три копии данных в одном дата-центре, у другого копии раскидываются по разным регионам. Цифры в маркетинговых материалах могут совпадать, а реальная устойчивость к катастрофам отличаться на порядки.
Модель согласованности у S3 со временем тоже изменилась. До 2020 года Amazon S3 работал в модели конечной согласованности (eventual consistency). После записи объекта последующее чтение могло какое-то время возвращать старую версию или ошибку «не найдено». Потом перешли на сильную согласованность чтения после записи (strong read-after-write consistency). У большинства S3-совместимых решений на базе Ceph модель согласованности тоже сильная, но это стоит проверять для конкретного сервиса. Eventual consistency вещь коварная, баги, связанные с ней, проявляются редко и плохо воспроизводятся.
Из дополнительных возможностей, которые есть в стандарте S3, стоит упомянуть две. Версионирование работает так, что при перезаписи объекта старая версия не удаляется, а сохраняется как отдельная версия с собственным идентификатором. Хорошая защита от случайной перезаписи и удаления. Включается отдельно для каждого бакета. Имеет цену, потому что занятое место растет за счёт хранения всех версий.
Политики жизненного цикла (lifecycle-политики) представляют собой правила, по которым объекты автоматически меняют свой класс хранения или удаляются по расписанию. Скажем, через 30 дней после загрузки объект переезжает в более холодное и дешёвое хранилище, а через 90 удаляется совсем. Удобный механизм для управления стоимостью, особенно для логов и бэкапов.
Обе возможности есть в спецификации S3 API, но не каждое S3-совместимое хранилище их полноценно поддерживает. Стоит проверять перед тем, как закладывать их в архитектуру.
Сценарии использования S3 хранилища
В каких случаях объектное хранилище имеет смысл, кажется, понятно из всего предыдущего, но конкретика не помешает.
Резервные копии и архивы. Один из самых очевидных сценариев. Системы резервного копирования вроде Restic, BorgBackup, Duplicati умеют писать резервные копии напрямую в S3. Объектное хранилище здесь подходит почти идеально. Данные пишутся один раз, читаются редко, объемы могут быть большими. Политики жизненного цикла позволяют автоматически удалять старые резервные копии.
Раздача статики и медиафайлов. Картинки, видео, документы для пользователей сайта или приложения. Можно отдавать прямо из S3 или через CDN (сеть доставки контента), которая кэширует контент на краевых узлах. Снимает нагрузку с приложения и упрощает масштабирование. У этого сценария есть подводный камень, и он связан с настройкой прав доступа. Контейнер, открытый «всем на чтение», легко превращается в источник утечек, если в нём оказываются файлы, которые там быть не должны.
Большие данные и обмен данными между микросервисами. Apache Spark, Hadoop, аналитические системы вроде Trino отлично работают с данными в S3. Парадигма «один раз записали, многократно прочитали» здесь отлично подходит. Кроме того, S3 удобен как «общая шина» между сервисами. Один сервис записывает результат своей работы как объект, другой подхватывает.
Хостинг статических сайтов. Если у сайта нет серверной логики (только HTML, CSS, JS, картинки), его можно хостить прямо из контейнера. Получается дёшево и масштабируемо. Подходит для документации, посадочных страниц, портфолио. Не подходит для всего, что требует серверной обработки запросов.
Хранение логов и метрик. Системы наблюдаемости часто складывают агрегированные логи в S3 для долгосрочного хранения. Горячие данные хранятся в Elasticsearch или Loki, холодные в S3 с политикой жизненного цикла. Поиск по холодным логам медленнее, но он и нужен реже.
Список можно продолжать, эти сценарии встречаются чаще всего. Объединяет их одно. Данные либо иммутабельны (резервная копия загрузили, она уже не меняется), либо обновляются целиком, а не точечно.
Преимущества объектного хранилища
Если попробовать собрать сильные стороны S3 в один список, получится примерно так:
- Горизонтальная масштабируемость. Архитектура изначально рассчитана на распределенное хранение, и добавление новых узлов в кластер штатная операция. Объемы измеряются в петабайтах без особых проблем.
- Простая модель доступа. HTTP API, два ключа для авторизации, никаких сессий и сложных протоколов. Проще, чем настраивать NFS-монтирование с правами и сетевыми политиками.
- Совместимость с экосистемой инструментов. Поскольку S3 API стал стандартом, под него написано множество библиотек, утилит и приложений. Если нужно что-то сделать с данными в S3, скорее всего, уже есть готовый инструмент.
- Управление через API. Создание бакетов, выдача прав, политики жизненного цикла, версионирование, всё настраивается через API. Подходит для инфраструктуры как кода.
- Гибкие модели прав. ACL, политики бакетов, временные подписанные ссылки. Можно дать публичный доступ к одному файлу, оставив остальной бакет закрытым. Можно сгенерировать ссылку с ограниченным временем жизни и отправить пользователю, который не имеет прав на бакет в целом.
Есть ещё момент, менее очевидный, но важный. S3 обычно тарифицируется по фактически занимаемому объёму, а не по выделенной квоте. Это удобнее, чем платить за том фиксированного размера, который заполнен на десять процентов.
Ограничения, о которых стоит помнить
Совсем без оговорок про S3 говорить было бы нечестно. У этой архитектуры есть минусы:
- Стоимость трафика. У большинства провайдеров плата за исходящий трафик из S3 заметно выше, чем за хранение. Если приложение активно отдаёт данные пользователям, ежемесячный счёт может удивить, а иногда и шокировать. Тут начинается интересный экономический расчёт, в нём решается, дешевле ли хостить статику в S3 с CDN или поднять выделенный сервер.
- Задержки. Каждый запрос фактически представляет собой HTTP-вызов к удалённому сервису, который проходит через шлюз, аутентификацию, маршрутизацию по кластеру. Для одного объекта это десятки миллисекунд. Если приложение делает много мелких запросов, это превращается в проблему. Решения существуют (батчинг, кэширование, multipart upload), но это уже усложнение кода.
- Отсутствие частичного обновления. Изменить байт в середине большого объекта нельзя. Только перезапись целиком. Для большинства сценариев это не проблема, но иногда упирается.
- Последняя проблема не техническая, а человеческая. S3 быстро становится местом, куда складывают всё подряд по принципу «лень разбираться, куда положить». Без дисциплины (структура префиксов, теги, lifecycle-политики) бакеты быстро превращаются в свалку, в которой невозможно понять, где что лежит и можно ли это удалить. Архитектура предлагает инструменты для порядка, но не заставляет ими пользоваться.
S3-совместимое хранилище HOSTKEY
В завершение пару слов о собственном S3-сервисе HOSTKEY. Сервис развернут в локации NL (Нидерланды), бэкенд построен на Ceph с использованием RADOS Gateway. Для подключения используется точка входа (endpoint) s3-nl.hostkey.com, авторизация по AWS Signature Version 4. То есть всё то же самое, что описано выше. Подключается любой S3-совместимый клиент, от консольного AWS CLI до графических утилит.
S3-совместимое хранилище HOSTKEY доступно по тарифу Standard Storage. В тариф включена квота – 250 ГБ хранилища, 1 ТБ исходящего трафика и 1500 командных запросов в месяц, всё сверх лимитов тарифицируется по факту использования с ежедневным списанием. Входящий трафик бесплатный. На одно хранилище допускается до 100 бакетов, а в рамках аккаунта можно держать несколько независимых хранилищ, каждое тарифицируется отдельно.
Внутри одного аккаунта можно создавать несколько независимых хранилищ с собственными ключами. Удобно для изоляции данных разных проектов или клиентов. Скажем, если фрилансер хостит сайты нескольких заказчиков, каждому можно выделить отдельное хранилище со своими учетными данными. Доступ к одному не открывает доступа к другим.
Подключиться можно через личный кабинет в Invapi, в нём же выдаются ключи. Дальше работает стандартный S3-совместимый клиент. У AWS CLI всё подключается флагом --endpoint-url, у графических клиентов вроде S3 Browser нужно выбрать тип «S3 Compatible Storage» (не «Amazon S3») и указать ту же точку входа.
Что дальше
S3 это не черный ящик, а вполне понятная архитектура, у которой есть свои сильные и слабые стороны. Сильные стороны выражаются в масштабируемости, простоте API и совместимости инструментов. Слабые проявляются в стоимости трафика, задержках на отдельные запросы и неподходящими для частых мелких изменений.
Какой провайдер выбрать, это уже отдельный разговор, и здесь нет универсально правильного ответа. AWS, GCS, Azure Blob, российские облака, S3-совместимые сервисы хостеров, у всех свои особенности, и сравнивать их нужно по конкретным критериям, важным для конкретной задачи. Цена за гигабайт, цена за исходящий трафик, география дата-центров, поддержка дополнительных возможностей API, юридические ограничения по обработке данных. Это всё имеет значение, но рейтинг здесь невозможен в отрыве от контекста.
Если хочется попробовать руками, дальше логично перейти к практической части. О том, как именно подключиться к S3 хранилищу из разных инструментов (AWS CLI, графических клиентов, кода на Python), будет отдельная статья.
Храните данные, необходимые для работы сервисов: резервные копии, аналитические данные и датасеты для ML.