
В апреле компания NVIDIA выпустила на рынок новый продукт — графический процессор малого форм-фактора RTX A4000 ADA, предназначенный для применения в рабочих станциях. Этот процессор пришел на смену A2000 и может быть использован для выполнения сложных задач, в том числе для научно-исследовательских и инженерных расчетов и для визуализации данных.
RTX A4000 ADA оснащена 6144 ядрами CUDA, 192 тензорами и 48 ядрами RT, оперативной памятью GDDR6 ECC VRAM объемом 20 Гб. Одно из ключевых преимуществ нового графического процессора — его энергоэффективность: RTX A4000 ADA потребляет всего 70 Вт, что снижает затраты на электроэнергию и уменьшает тепловыделение в системе. Графический процессор также позволяет управлять несколькими дисплеями благодаря подключению 4x Mini-DisplayPort 1.4a.

При сравнении графических процессоров RTX 4000 SFF Ada с другими устройствами того же класса можно отметить, что при работе в режиме одинарной точности данный продукт показывает производительность, аналогичную последнему поколению графического процессора RTX A4000, который потребляет вдвое больше энергии (140 Вт против 70 Вт).

RTX 4000 SFF Ada построена на архитектуре Ada Lovelace и техпроцессе 5 нм. Это позволяет использовать ядра Tensor Core нового поколения и ядра трассировки лучей, которые значительно повышают производительность, обеспечивая более быструю и эффективную работу с трассировкой лучей и тензорными ядрами, чем RTX A4000. Кроме того, RTX 4000 SFF Ada упакован в небольшой корпус — длина карты 168 мм, толщина равна двум слотам расширения.

Улучшение ядер трассировки лучей обеспечивает эффективную работу в средах, где используется эта технология, таких как 3D-дизайн и рендеринг. Объем памяти нового GPU (20 Гб) позволяет справляться с большими средами.

Согласно заявлениям производителя, тензорные ядра четвертого поколения обеспечивают высокую производительность вычислений ИИ — двукратное увеличение производительности по сравнению с предыдущим поколением. Новые тензорные ядра поддерживают ускорение FP8. Эта особенность нового графического процессора может хорошо подойти тем, кто разрабатывает и развертывает модели ИИ в таких средах, как геномика и компьютерное зрение.
Также стоит отметить, что увеличение количества механизмов кодирования и декодирования делает RTX 4000 SFF Ada хорошим решением для мультимедийных рабочих нагрузок, таких как работа с видео.
Технические характеристики видеокарт NVIDIA RTX A4000 и RTX A5000, RTX 3090
| RTX A4000 ADA | NVIDIA RTX A4000 | NVIDIA RTX A5000 | RTX 3090 | |
| Архитектура | Ada Lovelace | Ampere | Ampere | Ampere |
| Техпроцесс | 5 нм | 8 нм | 8 нм | 8 нм |
| Графический процессор | AD104 | GA102 | GA104 | GA102 |
| Количество транзисторов (млн) | 35,800 | 17,400 | 28,300 | 28,300 |
| Пропускная способность памяти (Гб/с) | 280.0 | 448 | 768 | 936.2 |
| Разрядность шины видеопамяти (бит) | 160 | 256 | 384 | 384 |
| Память GPU (Гб) | 20 | 16 | 24 | 24 |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 | GDDR6X |
| Ядра CUDA | 6,144 | 6 144 | 8192 | 10496 |
| Тензорные ядра | 192 | 192 | 256 | 328 |
| Ядра RT | 48 | 48 | 64 | 82 |
| SP perf (терафлопс) | 19.2 | 19,2 | 27,8 | 35,6 |
| RT Core performance (терафлопс) | 44.3 | 37,4 | 54,2 | 69,5 |
| Tensor performance (терафлопс) | 306.8 | 153,4 | 222,2 | 285 |
| Максимальная мощность (Вт) | 70 | 140 | 230 | 350 |
| Интерфейс | PCIe 4.0 x 16 | PCI-E 4.0 x16 | PCI-E 4.0 x16 | PCIe 4.0 x16 |
| Разъемы | 4x Mini DisplayPort 1.4a | ДП 1.4 (4) | ДП 1.4 (4) | ДП 1.4 (4) |
| Форм-фактор | 2 слота | 1 слот | 2 слота | 2-3 слота |
| Программное обеспечение vGPU | нет | нет | есть неограниченно | есть с ограничениями |
| Nvlink | нет | нет | 2x RTX A5000 | есть |
| Поддержка CUDA | 11.6 | 8.6 | 8.6 | 8.6 |
| Поддержка VULKAN | 1.3 | есть | есть | есть, 1.2 |
| Цена (руб.) | 100 000 | 125 000 | 220 000 | 100 000 |
Описание тестовой среды
| RTX A4000 ADA | RTX A4000 | |
| Процессор | AMD Ryzen 9 5950X 3.4GHz (16 cores) | OctaCore Intel Xeon E-2288G, 3,5 GHz |
| Оперативная память | 4x 32 Gb DDR4 ECC SO-DIMM | 2x 32 GB DDR4-3200 ECC DDR4 SDRAM 1600 МГц |
| Накопитель | 1Tb NVMe SSD | Samsung SSD 980 PRO 1TB |
| Материнская плата | ASRock X570D4I-2T | Asus P11C-I Series |
| Операционная система | Microsoft Windows 10 | Microsoft Windows 10 |
Результаты в тестах
V-Ray 5 Benchmark
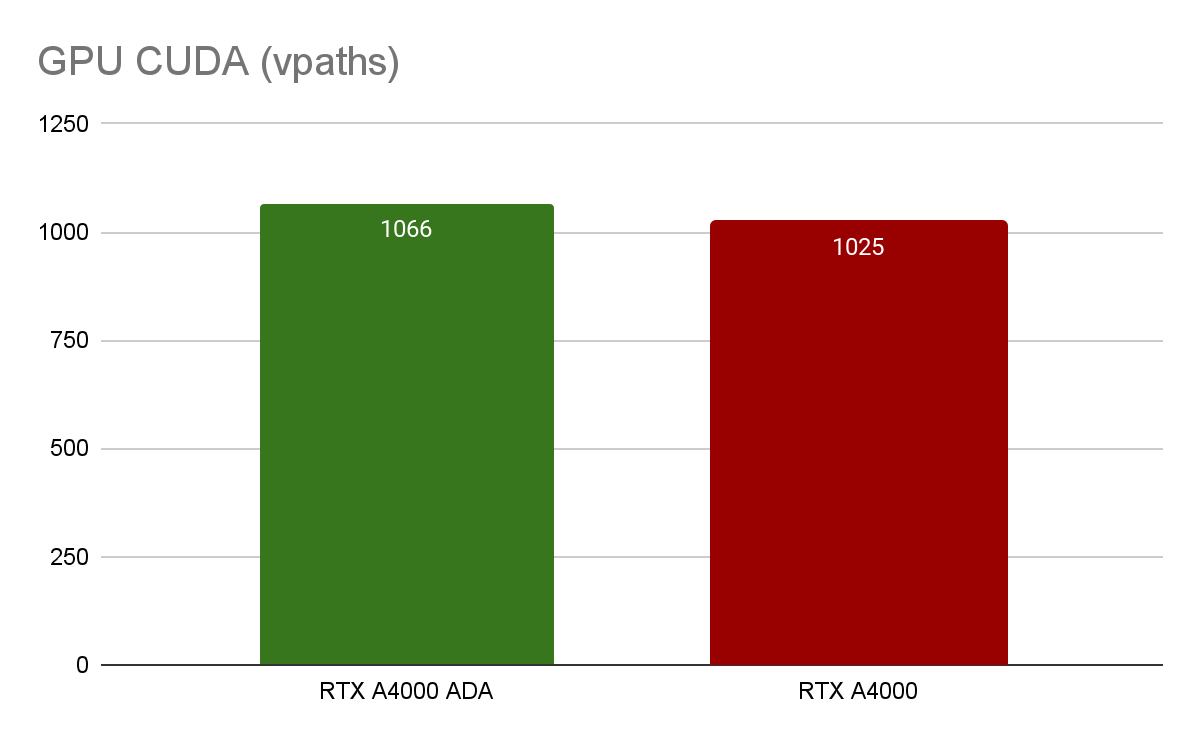
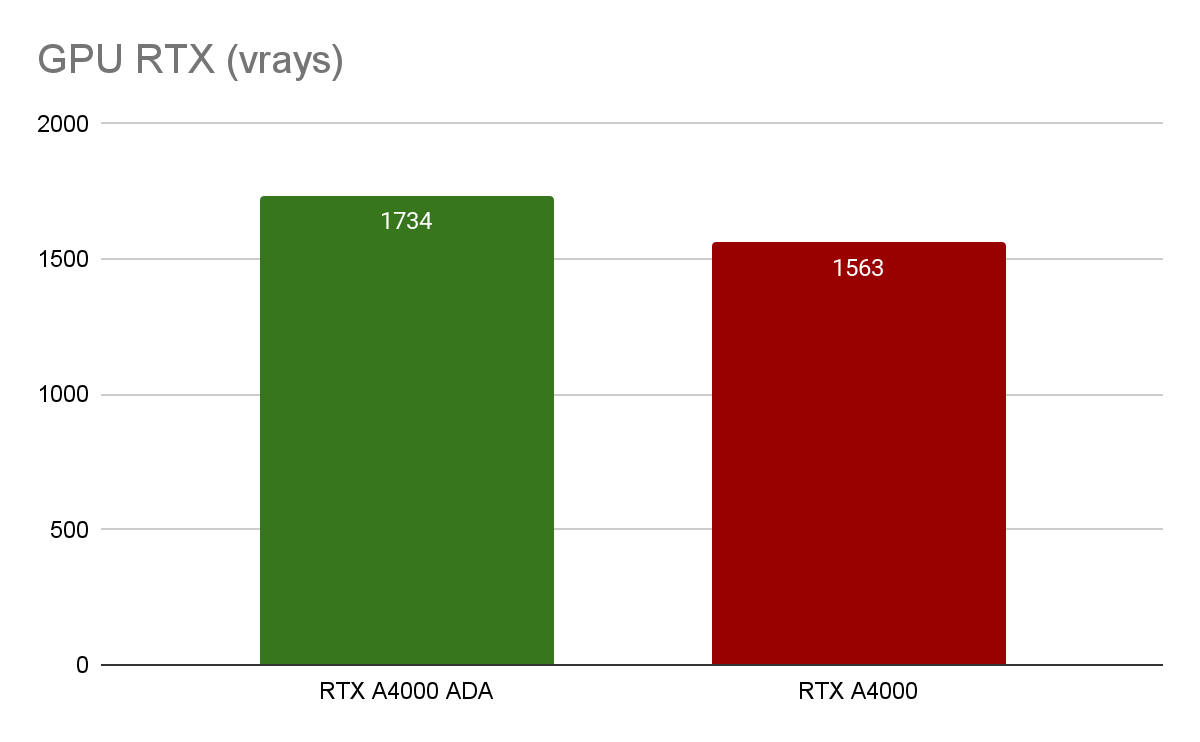
Тесты V-Ray GPU CUDA и RTX позволяют измерить относительную производительность GPU при рендеринге. GPU RTX A4000 незначительно уступает по производительности RTX A4000 ADA (4% и 11% соответственно).
Машинное обучение
«Собаки против кошек»
Для сравнения производительности GPU для нейросетей мы используем набор данных «Собаки против кошек» — тест анализирует содержимое фотографии и различает, изображена на фото кошка или собака. Все необходимые исходные данные находятся здесь. Мы запускали этот тест на разных GPU и в различных облачных сервисах и получили следующие результаты:
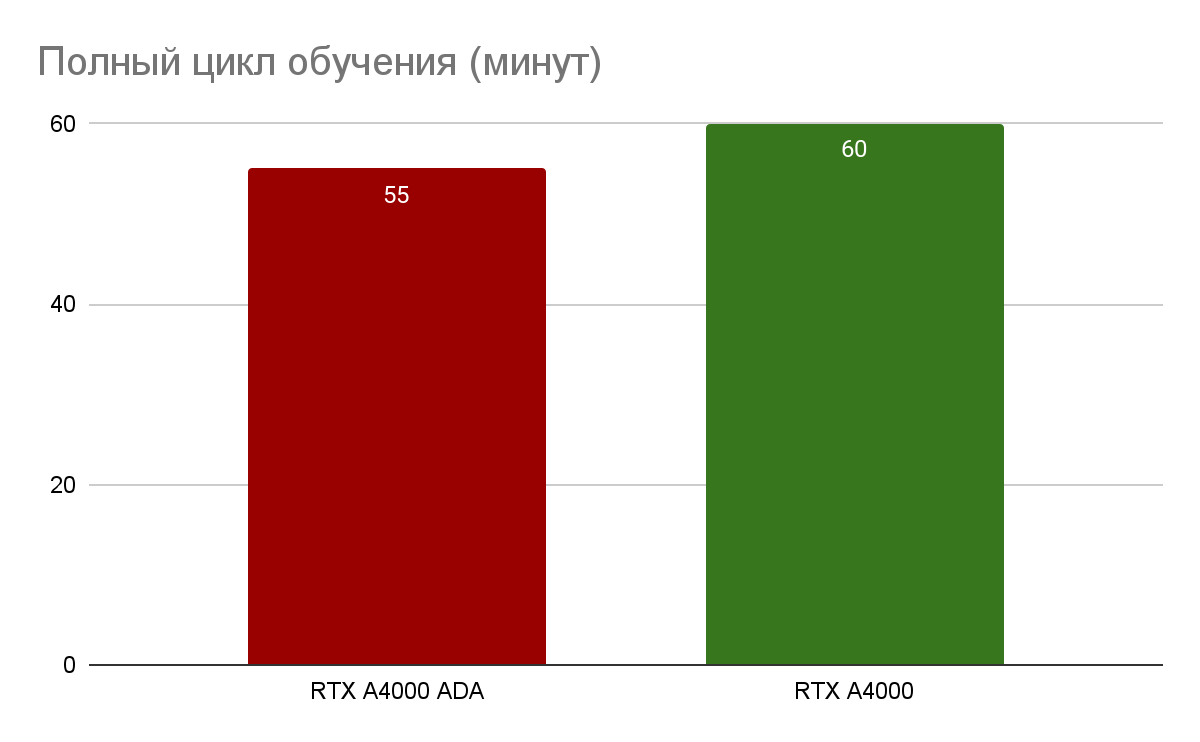
В этом тесте результат RTX A4000 ADA незначительно превзошел RTX A4000 (9%), но следует помнить о небольшом размере и низком энергопотреблении нового GPU.
AI-Benchmark
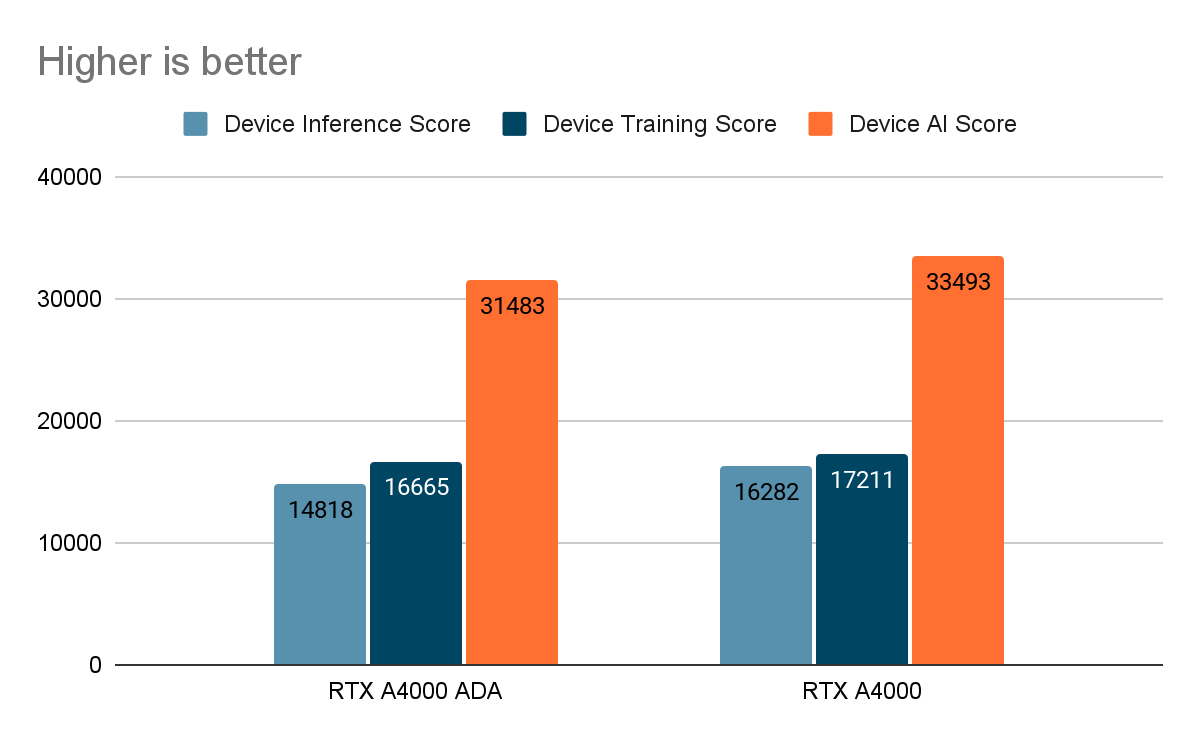
AI-Benchmark позволяет измерить производительность устройства во время выполнения задачи вывода AI-моделей. Единицы измерения могут зависеть от теста, но обычно это количество операций в секунду (OPS) или количество изображений в секунду (FPS).
| RTX A4000 | RTX A4000 ADA | |
| 1/19. MobileNet-V2 | 1.1 — inference | batch=50, size=224x224: 38.5 ± 2.4 ms 1.2 — training | batch=50, size=224x224: 109 ± 4 ms | 1.1 — inference | batch=50, size=224x224: 53.5 ± 0.7 ms 1.2 — training | batch=50, size=224x224: 130.1 ± 0.6 ms |
| 2/19. Inception-V3 | 2.1 — inference | batch=20, size=346x346: 36.1 ± 1.8 ms 2.2 — training | batch=20, size=346x346: 137.4 ± 0.6 ms | 2.1 — inference | batch=20, size=346x346: 36.8 ± 1.1 ms 2.2 — training | batch=20, size=346x346: 147.5 ± 0.8 ms |
| 3/19. Inception-V4 | 3.1 — inference | batch=10, size=346x346: 34.0 ± 0.9 ms 3.2 — training | batch=10, size=346x346: 139.4 ± 1.0 ms | 3.1 — inference | batch=10, size=346x346: 33.0 ± 0.8 ms 3.2 — training | batch=10, size=346x346: 135.7 ± 0.9 ms |
| 4/19. Inception-ResNet-V2 | 4.1 — inference | batch=10, size=346x346: 45.7 ± 0.6 ms 4.2 — training | batch=8, size=346x346: 153.4 ± 0.8 ms | 4.1 — inference batch=10, size=346x346: 33.6 ± 0.7 ms 4.2 — training batch=8, size=346x346: 132 ± 1 ms |
| 5/19. ResNet-V2-50 | 5.1 — inference | batch=10, size=346x346: 25.3 ± 0.5 ms 5.2 — training | batch=10, size=346x346: 91.1 ± 0.8 ms | 5.1 — inference | batch=10, size=346x346: 26.1 ± 0.5 ms 5.2 — training | batch=10, size=346x346: 92.3 ± 0.6 ms |
| 6/19. ResNet-V2-152 | 6.1 — inference | batch=10, size=256x256: 32.4 ± 0.5 ms 6.2 — training | batch=10, size=256x256: 131.4 ± 0.7 ms | 6.1 — inference | batch=10, size=256x256: 23.7 ± 0.6 ms 6.2 — training | batch=10, size=256x256: 107.1 ± 0.9 ms |
| 7/19. VGG-16 | 7.1 — inference | batch=20, size=224x224: 54.9 ± 0.9 ms 7.2 — training | batch=2, size=224x224: 83.6 ± 0.7 ms | 7.1 — inference | batch=20, size=224x224: 66.3 ± 0.9 ms 7.2 — training | batch=2, size=224x224: 109.3 ± 0.8 ms |
| 8/19. SRCNN 9-5-5 | 8.1 — inference | batch=10, size=512x512: 51.5 ± 0.9 ms 8.2 — inference | batch=1, size=1536x1536: 45.7 ± 0.9 ms 8.3 — training | batch=10, size=512x512: 183 ± 1 ms | 8.1 — inference | batch=10, size=512x512: 59.9 ± 1.6 ms 8.2 — inference | batch=1, size=1536x1536: 53.1 ± 0.7 ms 8.3 — training | batch=10, size=512x512: 176 ± 2 ms |
| 9/19. VGG-19 Super-Res | 9.1 — inference | batch=10, size=256x256: 99.5 ± 0.8 ms 9.2 — inference | batch=1, size=1024x1024: 162 ± 1 ms 9.3 — training | batch=10, size=224x224: 204 ± 2 ms | |
| 10/19. ResNet-SRGAN | 10.1 — inference | batch=10, size=512x512: 85.8 ± 0.6 ms 10.2 — inference | batch=1, size=1536x1536: 82.4 ± 1.9 ms 10.3 — training | batch=5, size=512x512: 133 ± 1 ms | 10.1 — inference | batch=10, size=512x512: 98.9 ± 0.8 ms 10.2 — inference | batch=1, size=1536x1536: 86.1 ± 0.6 ms 10.3 — training | batch=5, size=512x512: 130.9 ± 0.6 ms |
| 11/19. ResNet-DPED | 11.1 — inference | batch=10, size=256x256: 114.9 ± 0.6 ms 11.2 — inference | batch=1, size=1024x1024: 182 ± 2 ms 11.3 — training | batch=15, size=128x128: 178.1 ± 0.8 ms | 11.1 — inference | batch=10, size=256x256: 146.4 ± 0.5 ms 11.2 — inference | batch=1, size=1024x1024: 234.3 ± 0.5 ms 11.3 — training | batch=15, size=128x128: 234.7 ± 0.6 ms |
| 12/19. U-Net | 12.1 — inference | batch=4, size=512x512: 180.8 ± 0.7 ms 12.2 — inference | batch=1, size=1024x1024: 177.0 ± 0.4 ms 12.3 — training | batch=4, size=256x256: 198.6 ± 0.5 ms | 12.1 — inference | batch=4, size=512x512: 222.9 ± 0.5 ms 12.2 — inference | batch=1, size=1024x1024: 220.4 ± 0.6 ms 12.3 — training | batch=4, size=256x256: 229.1 ± 0.7 ms |
| 13/19. Nvidia-SPADE | 13.1 — inference | batch=5, size=128x128: 54.5 ± 0.5 ms 13.2 — training | batch=1, size=128x128: 103.6 ± 0.6 ms | 13.1 — inference | batch=5, size=128x128: 59.6 ± 0.6 ms 13.2 — training | batch=1, size=128x128: 94.6 ± 0.6 ms |
| 14/19. ICNet | 14.1 — inference | batch=5, size=1024x1536: 126.3 ± 0.8 ms 14.2 — training | batch=10, size=1024x1536: 426 ± 9 ms | 14.1 — inference | batch=5, size=1024x1536: 144 ± 4 ms 14.2 — training | batch=10, size=1024x1536: 475 ± 17 ms |
| 15/19. PSPNet | 15.1 — inference | batch=5, size=720x720: 249 ± 12 ms 15.2 — training | batch=1, size=512x512: 104.6 ± 0.6 ms | 15.1 — inference | batch=5, size=720x720: 291.4 ± 0.5 ms 15.2 — training | batch=1, size=512x512: 99.8 ± 0.9 ms |
| 16/19. DeepLab | 16.1 — inference | batch=2, size=512x512: 71.7 ± 0.6 ms 16.2 — training | batch=1, size=384x384: 84.9 ± 0.5 ms | 16.1 — inference | batch=2, size=512x512: 71.5 ± 0.7 ms 16.2 — training | batch=1, size=384x384: 69.4 ± 0.6 ms |
| 17/19. Pixel-RNN | 17.1 — inference | batch=50, size=64x64: 299 ± 14 ms 17.2 — training | batch=10, size=64x64: 1258 ± 64 ms | 17.1 — inference | batch=50, size=64x64: 321 ± 30 ms 17.2 — training | batch=10, size=64x64: 1278 ± 74 ms |
| 18/19. LSTM-Sentiment | 18.1 — inference | batch=100, size=1024x300: 395 ± 11 ms 18.2 — training | batch=10, size=1024x300: 676 ± 15 ms | 18.1 — inference | batch=100, size=1024x300: 345 ± 10 ms 18.2 — training | batch=10, size=1024x300: 774 ± 17 ms |
| 19/19. GNMT-Translation | 19.1 — inference | batch=1, size=1x20: 119 ± 2 ms | 19.1 — inference | batch=1, size=1x20: 156 ± 1 ms |
Результаты этого теста показывают, что производительность RTX A4000 незначительно (на 6%) выше, чем у RTX A4000 ADA. Однако, стоит отметить, что результаты тестов могут различаться в зависимости от конкретных задач и условий работы.
PyTorch
RTX A 4000
| Benchmarking | Model average train time (ms) |
| Training double precision type mnasnet0_5 | 62.995805740356445 |
| Training double precision type mnasnet0_75 | 98.39066505432129 |
| Training double precision type mnasnet1_0 | 126.60405158996582 |
| Training double precision type mnasnet1_3 | 186.89460277557373 |
| Training double precision type resnet18 | 428.08079719543457 |
| Training double precision type resnet34 | 883.5790348052979 |
| Training double precision type resnet50 | 1016.3950300216675 |
| Training double precision type resnet101 | 1927.2308254241943 |
| Training double precision type resnet152 | 2815.663013458252 |
| Training double precision type resnext50_32x4d | 1075.4373741149902 |
| Training double precision type resnext101_32x8d | 4050.0641918182373 |
| Training double precision type wide_resnet50_2 | 2615.9953451156616 |
| Training double precision type wide_resnet101_2 | 5218.524832725525 |
| Training double precision type densenet121 | 751.9759511947632 |
| Training double precision type densenet169 | 910.3225564956665 |
| Training double precision type densenet201 | 1163.036551475525 |
| Training double precision type densenet161 | 2141.505298614502 |
| Training double precision type squeezenet1_0 | 203.14435005187988 |
| Training double precision type squeezenet1_1 | 98.04857730865479 |
| Training double precision type vgg11 | 1697.710485458374 |
| Training double precision type vgg11_bn | 1729.2972660064697 |
| Training double precision type vgg13 | 2491.615080833435 |
| Training double precision type vgg13_bn | 2545.1631927490234 |
| Training double precision type vgg16 | 3371.1953449249268 |
| Training double precision type vgg16_bn | 3423.8639068603516 |
| Training double precision type vgg19_bn | 4314.5153522491455 |
| Training double precision type vgg19 | 4249.422650337219 |
| Training double precision type mobilenet_v3_large | 105.54619789123535 |
| Training double precision type mobilenet_v3_small | 37.6680850982666 |
| Training double precision type shufflenet_v2_x0_5 | 26.51611328125 |
| Training double precision type shufflenet_v2_x1_0 | 61.260504722595215 |
| Training double precision type shufflenet_v2_x1_5 | 105.30067920684814 |
| Training double precision type shufflenet_v2_x2_0 | 181.03694438934326 |
| Inference double precision type mnasnet0_5 | 17.397074699401855 |
| Inference double precision type mnasnet0_75 | 28.902697563171387 |
| Inference double precision type mnasnet1_0 | 38.387718200683594 |
| Inference double precision type mnasnet1_3 | 58.228821754455566 |
| Inference double precision type resnet18 | 147.95727252960205 |
| Inference double precision type resnet34 | 293.519492149353 |
| Inference double precision type resnet50 | 336.44991874694824 |
| Inference double precision type resnet101 | 637.9982376098633 |
| Inference double precision type resnet152 | 948.9351654052734 |
| Inference double precision type resnext50_32x4d | 372.80876636505127 |
| Inference double precision type resnext101_32x8d | 1385.1624917984009 |
| Inference double precision type wide_resnet50_2 | 873.048791885376 |
| Inference double precision type wide_resnet101_2 | 1729.2765426635742 |
| Inference double precision type densenet121 | 270.13323307037354 |
| Inference double precision type densenet169 | 327.1932888031006 |
| Inference double precision type densenet201 | 414.733362197876 |
| Inference double precision type densenet161 | 766.3542318344116 |
| Inference double precision type squeezenet1_0 | 74.86292839050293 |
| Inference double precision type squeezenet1_1 | 34.04905319213867 |
| Inference double precision type vgg11 | 576.3767147064209 |
| Inference double precision type vgg11_bn | 580.5839586257935 |
| Inference double precision type vgg13 | 853.4365510940552 |
| Inference double precision type vgg13_bn | 860.3136301040649 |
| Inference double precision type vgg16 | 1145.091052055359 |
| Inference double precision type vgg16_bn | 1152.8028392791748 |
| Inference double precision type vgg19_bn | 1444.9562692642212 |
| Inference double precision type vgg19 | 1437.0987701416016 |
| Inference double precision type mobilenet_v3_large | 30.876317024230957 |
| Inference double precision type mobilenet_v3_small | 11.234536170959473 |
| Inference double precision type shufflenet_v2_x0_5 | 7.425284385681152 |
| Inference double precision type shufflenet_v2_x1_0 | 18.25782299041748 |
| Inference double precision type shufflenet_v2_x1_5 | 33.34946632385254 |
| Inference double precision type shufflenet_v2_x2_0 | 57.84676551818848 |
RTX A4000 ADA
| Benchmarking | Model average train time |
| Training half precision type mnasnet0_5 | 20.266618728637695 |
| Training half precision type mnasnet0_75 | 21.445374488830566 |
| Training half precision type mnasnet1_0 | 26.714019775390625 |
| Training half precision type mnasnet1_3 | 26.5126371383667 |
| Training half precision type resnet18 | 19.624991416931152 |
| Training half precision type resnet34 | 32.46446132659912 |
| Training half precision type resnet50 | 57.17473030090332 |
| Training half precision type resnet101 | 98.20127010345459 |
| Training half precision type resnet152 | 138.18389415740967 |
| Training half precision type resnext50_32x4d | 75.56005001068115 |
| Training half precision type resnext101_32x8d | 228.8706636428833 |
| Training half precision type wide_resnet50_2 | 113.76442432403564 |
| Training half precision type wide_resnet101_2 | 204.17311191558838 |
| Training half precision type densenet121 | 68.97401332855225 |
| Training half precision type densenet169 | 85.16453742980957 |
| Training half precision type densenet201 | 103.299241065979 |
| Training half precision type densenet161 | 137.54578113555908 |
| Training half precision type squeezenet1_0 | 16.71830177307129 |
| Training half precision type squeezenet1_1 | 12.906527519226074 |
| Training half precision type vgg11 | 51.7004919052124 |
| Training half precision type vgg11_bn | 57.63327598571777 |
| Training half precision type vgg13 | 86.10869407653809 |
| Training half precision type vgg13_bn | 95.86676120758057 |
| Training half precision type vgg16 | 102.91589260101318 |
| Training half precision type vgg16_bn | 113.74778270721436 |
| Training half precision type vgg19_bn | 131.56734943389893 |
| Training half precision type vgg19 | 119.70191955566406 |
| Training half precision type mobilenet_v3_large | 31.30636692047119 |
| Training half precision type mobilenet_v3_small | 19.44464683532715 |
| Training half precision type shufflenet_v2_x0_5 | 13.710575103759766 |
| Training half precision type shufflenet_v2_x1_0 | 23.608479499816895 |
| Training half precision type shufflenet_v2_x1_5 | 26.793746948242188 |
| Training half precision type shufflenet_v2_x2_0 | 24.550962448120117 |
| Inference half precision type mnasnet0_5 | 4.418272972106934 |
| Inference half precision type mnasnet0_75 | 4.021778106689453 |
| Inference half precision type mnasnet1_0 | 4.42598819732666 |
| Inference half precision type mnasnet1_3 | 4.618926048278809 |
| Inference half precision type resnet18 | 5.803341865539551 |
| Inference half precision type resnet34 | 9.756693840026855 |
| Inference half precision type resnet50 | 15.873079299926758 |
| Inference half precision type resnet101 | 28.268003463745117 |
| Inference half precision type resnet152 | 40.04594326019287 |
| Inference half precision type resnext50_32x4d | 19.53421115875244 |
| Inference half precision type resnext101_32x8d | 62.44826316833496 |
| Inference half precision type wide_resnet50_2 | 33.533992767333984 |
| Inference half precision type wide_resnet101_2 | 59.60897445678711 |
| Inference half precision type densenet121 | 18.052735328674316 |
| Inference half precision type densenet169 | 21.956982612609863 |
| Inference half precision type densenet201 | 27.85182476043701 |
| Inference half precision type densenet161 | 37.41891860961914 |
| Inference half precision type squeezenet1_0 | 4.391803741455078 |
| Inference half precision type squeezenet1_1 | 2.4281740188598633 |
| Inference half precision type vgg11 | 17.11493968963623 |
| Inference half precision type vgg11_bn | 18.40585231781006 |
| Inference half precision type vgg13 | 28.438148498535156 |
| Inference half precision type vgg13_bn | 30.672597885131836 |
| Inference half precision type vgg16 | 34.43562984466553 |
| Inference half precision type vgg16_bn | 36.92122936248779 |
| Inference half precision type vgg19_bn | 43.144264221191406 |
| Inference half precision type vgg19 | 40.5385684967041 |
| Inference half precision type mobilenet_v3_large | 5.350713729858398 |
| Inference half precision type mobilenet_v3_small | 4.016985893249512 |
| Inference half precision type shufflenet_v2_x0_5 | 5.079126358032227 |
| Inference half precision type shufflenet_v2_x1_0 | 5.593156814575195 |
| Inference half precision type shufflenet_v2_x1_5 | 5.649552345275879 |
| Inference half precision type shufflenet_v2_x2_0 | 5.355663299560547 |
| Training double precision type mnasnet0_5 | 50.2386999130249 |
| Training double precision type mnasnet0_75 | 80.66896915435791 |
| Training double precision type mnasnet1_0 | 103.32422733306885 |
| Training double precision type mnasnet1_3 | 154.6230697631836 |
| Training double precision type resnet18 | 337.94031620025635 |
| Training double precision type resnet34 | 677.7706575393677 |
| Training double precision type resnet50 | 789.9243211746216 |
| Training double precision type resnet101 | 1484.3351316452026 |
| Training double precision type resnet152 | 2170.570478439331 |
| Training double precision type resnext50_32x4d | 877.3719882965088 |
| Training double precision type resnext101_32x8d | 3652.4944639205933 |
| Training double precision type wide_resnet50_2 | 2154.612874984741 |
| Training double precision type wide_resnet101_2 | 4176.522083282471 |
| Training double precision type densenet121 | 607.8699731826782 |
| Training double precision type densenet169 | 744.6409797668457 |
| Training double precision type densenet201 | 962.677731513977 |
| Training double precision type densenet161 | 1759.772515296936 |
| Training double precision type squeezenet1_0 | 164.3690824508667 |
| Training double precision type squeezenet1_1 | 78.70647430419922 |
| Training double precision type vgg11 | 1362.6095294952393 |
| Training double precision type vgg11_bn | 1387.2539138793945 |
| Training double precision type vgg13 | 2006.0230445861816 |
| Training double precision type vgg13_bn | 2047.526364326477 |
| Training double precision type vgg16 | 2702.2086429595947 |
| Training double precision type vgg16_bn | 2747.241234779358 |
| Training double precision type vgg19_bn | 3447.1724700927734 |
| Training double precision type vgg19 | 3397.990345954895 |
| Training double precision type mobilenet_v3_large | 84.65698719024658 |
| Training double precision type mobilenet_v3_small | 29.816465377807617 |
| Training double precision type shufflenet_v2_x0_5 | 27.401342391967773 |
| Training double precision type shufflenet_v2_x1_0 | 48.322744369506836 |
| Training double precision type shufflenet_v2_x1_5 | 82.22103118896484 |
| Training double precision type shufflenet_v2_x2_0 | 141.7021369934082 |
| Inference double precision type mnasnet0_5 | 12.988653182983398 |
| Inference double precision type mnasnet0_75 | 22.422199249267578 |
| Inference double precision type mnasnet1_0 | 30.056486129760742 |
| Inference double precision type mnasnet1_3 | 46.953935623168945 |
| Inference double precision type resnet18 | 118.04479122161865 |
| Inference double precision type resnet34 | 231.52336597442627 |
| Inference double precision type resnet50 | 268.63497734069824 |
| Inference double precision type resnet101 | 495.2010440826416 |
| Inference double precision type resnet152 | 726.4922094345093 |
| Inference double precision type resnext50_32x4d | 291.47679328918457 |
| Inference double precision type resnext101_32x8d | 1055.10901927948 |
| Inference double precision type wide_resnet50_2 | 690.6917667388916 |
| Inference double precision type wide_resnet101_2 | 1347.5529861450195 |
| Inference double precision type densenet121 | 224.35829639434814 |
| Inference double precision type densenet169 | 268.9145278930664 |
| Inference double precision type densenet201 | 343.1972026824951 |
| Inference double precision type densenet161 | 635.866231918335 |
| Inference double precision type squeezenet1_0 | 61.92759037017822 |
| Inference double precision type squeezenet1_1 | 27.009410858154297 |
| Inference double precision type vgg11 | 462.3375129699707 |
| Inference double precision type vgg11_bn | 468.4495782852173 |
| Inference double precision type vgg13 | 692.8219032287598 |
| Inference double precision type vgg13_bn | 703.3538103103638 |
| Inference double precision type vgg16 | 924.4353818893433 |
| Inference double precision type vgg16_bn | 936.5075063705444 |
| Inference double precision type vgg19_bn | 1169.098300933838 |
| Inference double precision type vgg19 | 1156.3771772384644 |
| Inference double precision type mobilenet_v3_large | 24.2356014251709 |
| Inference double precision type mobilenet_v3_small | 8.85490894317627 |
| Inference double precision type shufflenet_v2_x0_5 | 6.360034942626953 |
| Inference double precision type shufflenet_v2_x1_0 | 14.301743507385254 |
| Inference double precision type shufflenet_v2_x1_5 | 24.863481521606445 |
| Inference double precision type shufflenet_v2_x2_0 | 43.8505744934082 |
Заключение
Новая видеокарта показала себя эффективным решением для выполнения различных рабочих задач. Благодаря своим компактным размерам она отлично подойдет для мощных компьютеров форм-фактора SFF (Small Form Factor). Также стоит отметить, что 6144 ядра CUDA и 20 ГБ памяти со 160-разрядной шиной делают эту карту одной из самых производительных на рынке. При этом низкое TDP в 70 Вт позволяет снизить затраты на энергопотребление. Четыре порта Mini-DisplayPort позволяют использовать карту с несколькими мониторами или в качестве решения для многоканальной графики.
RTX 4000 SFF Ada представляет собой значительный прогресс по сравнению с предыдущими поколениями, обеспечивает производительность, эквивалентную карте с удвоенной потребляемой мощностью. Благодаря отсутствию разъема питания PCIe RTX 4000 SFF Ada легко интегрировать в рабочие станции с низким энергопотреблением при сохранении высокой производительности.