
«Предупреждение болезни HDD или SDD может спасти вашу рабочую неделю», — учили старейшины DevOps. И они были правы!
Представьте: у вас целая когорта виртуальных машин, работающих на oVirt. Но что произойдет, если диск в одном из узлов начнет сбоить? Pandemonium!
И вот тут на сцену выходит наш герой — smartctl_exporter. Этот маленький, но мощный инструмент постоянно следит за S.M.A.R.T.-данными ваших дисков, словно врач с термометром и стетоскопом. Если он заметит проблемы, то немедленно отправит тревогу в Prometheus и Grafana, чтобы вы могли принять меры. Ниже краткая информация о нем и о его настройке.
Выделенные серверы с процессорами 4 поколения AMD EPYC 9354 / 9124 / 9554 / 9754 и Intel Xeon Silver 4416+
Арендуйте высокопроизводительный выделенный сервер на базе процессоров AMD EPYC и Intel Xeon последнего поколения, с оперативной памятью DDR5 и хранилищем NVME. Серверы доступны для заказа в ультрасовременном дата-центре в Москве и Амстердаме.
🔶 Инсталляционный платеж: Бесплатно 🔶 Скидка до 12% в зависимости от срока аренды 🔶 Время сдачи: следующий рабочий день
Как работает этот инструмент?
Вкратце это можно описать так:
- Smartctl_exporter проникает внутрь ваших дисков и собирает информацию о их состоянии с помощью Smartmontools.
- Все собранные данные отправляются по HTTP на порт 9633, где Prometheus с жадностью их «глотает».
- Prometheus, в свою очередь, преобразует эти данные в понятную форму, которую Grafana легко отображает в виде красивых графиков и диаграмм.
- Если smart_exporter обнаружит серьезную угрозу (например, диск может скоро вылететь), он тут же отправит вам уведомление, чтобы вы успели принять необходимые меры.
Минус — инструмент имеет ограничения по работе некоторыми SCSI/SAS- и NVMe-дисками, которые отсутствуют в базе smartctl/smartd.
В самом сердце smartctl_exporter, внутри функции main, определяется список устройств для мониторинга. Если задан флаг smartctl.device, экспортер использует указанные устройства. В противном случае он обращается к функции scanDevices, которая выполняет сканирование и подгружает список доступных устройств.
Smart_exporter устанавливается на каждый оVirt Node (компонент, установленный на каждом отдельном хосте, который управляет всеми ресурсами этого хоста и запущенными на нем виртуальными машинами) по пути /usr/bin/smartctl_exporter. В качестве ОС используется CentOS 8 Stream. Для бесперебойной работы необходимо убедиться, что на oVirt Engine (центральный сервер управления, который контролирует все хосты виртуализации, дисковые ресурсы и виртуальные сети) установлена версия GoLang, не ниже той, что использовалась для написания экспортера.
Создание сервиса
Для работы экспортера также необходимо создать сервис systemd. Для этого идем в каталог /usr/lib/systemd/system/ и создаем файл smartctl_exporter.service:
[Unit]
Description=smartctl exporter service
After=network-online.target
[Service]
Type=simple
PIDFile=/run/smartctl_exporter.pid
ExecStart=/usr/bin/smartctl_exporter
User=root
Group=root
SyslogIdentifier=smartctl_exporter
Restart=on-failure
RemainAfterExit=no
RestartSec=100ms
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.targetПосле необходимо активизировать сервис и запустить его командами:
systemctl daemon-reload
systemctl start smartctl_exporter.serviceПроверяем статус работы командой:
systemctl status smartctl_exporter.service.Если все хорошо, увидим вывод, похожий на этот:
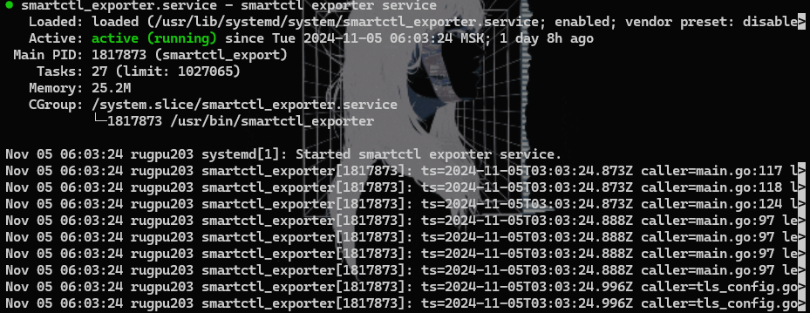
Теперь надо убедиться, что нужный нам порт 9633, куда будут отдаваться метрики, не закрыт фаерволом.
Для этого вводим команду:
netstat -na | grep 9633 Смотрим вывод. Если порт открыт, результат будет следующим:

Если порт закрыт, нужно открыть его вручную:
firewall-cmd --add-port 9633/tcpДалее следует проверить, «тянется» ли метрика. Для этого, находясь на ноде, вводим:
curl http://localhost:9633/metricsСмотрим вывод:
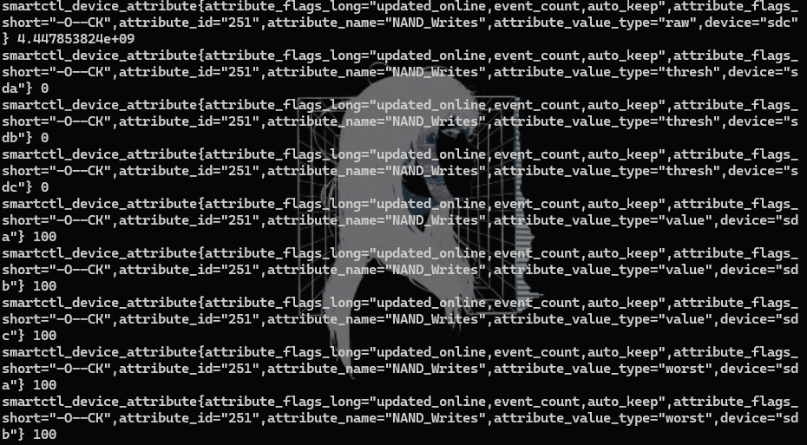 Создание алерта Prometheus
Первым делом создаем алерт. У нас в HOSTKEY мы храним их в gitlab по пути /devops/ansible-playbooks/prometheus_playbook/ files/alerts.
Создание алерта Prometheus
Первым делом создаем алерт. У нас в HOSTKEY мы храним их в gitlab по пути /devops/ansible-playbooks/prometheus_playbook/ files/alerts.
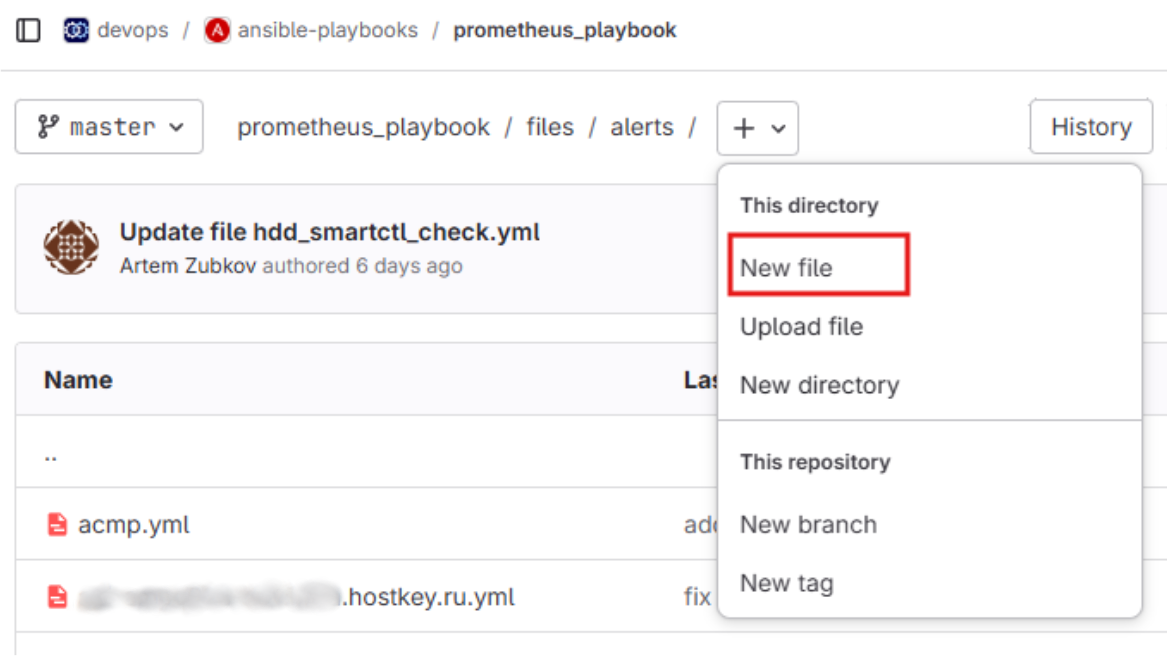
Создаем файл в формате .yml и пишем алерт, где указываем имя самого алерта, нужный для мониторинга атрибут и значение, на которое будет срабатывать алерт, время обновления, типа алерта (в нашем примере warning), а также описание. Формат алерта следующий:
groups:
- name: hdd_smartctl_check.rules
rules:
#===================service is down========================
— alert: Service is down
expr: up{job="smart_exporter"} == 0
for: 0m
labels:
severity: critical
annotations:
summary: Service is down ({{ $labels.instance }})
description: "Service is not reachable."
#===================Uncorrectable disk sectors============
— alert: Uncorrectable disk sectors
expr: smartctl_device_attribute{attribute_name="Offline_Uncorrectable",attribute_value_type="raw",job="smart_exporter"} > 10
for: 0m
labels:
severity: warning
annotations:
summary: Uncorrectable disk sectors ({{ $labels.name }})
description: "Value: {{ $value }}\nName: {{ $labels.name }}"
#===================DiskCurrentPendingSector========================
— alert: DiskCurrentPendingSector
expr: smartctl_device_attribute{attribute_name="Current_Pending_Sector",attribute_value_type="raw",job="smart_exporter"} > 10
for: 0m
labels:
severity: warning
annotations:
summary: DiskCurrentPendingSector ({{ $labels.name }})
description: "Value: {{ $value }}\nName: {{ $labels.name }}"
#===================Disk reallocated sectors=====================
— alert: Disk reallocated sectors
expr: smartctl_device_attribute{attribute_name="Reallocated_Sector_Ct",attribute_value_type="raw",job="smart_exporter"} > 10
for: 0m
labels:
severity: warning
annotations:
summary: Disk reallocated sectors ({{ $labels.name }})
description: "Value: {{ $value }}\nName: {{ $labels.name }}"Сохраняем файл hdd_smartctl_check.yml и переходим в каталог /devops/ansible-playbooks/prometheus_playbook/group_vars.
Открываем файл federation_ru.yaml. В верхней части документа, рядом с остальными таргетами, ниже создаем свой:
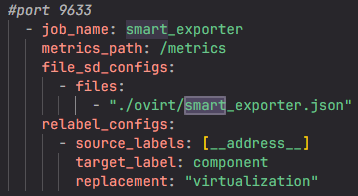
В таргете прописываем имя таргета, путь на каталог на HTTP, поднятый ранее на 9633 порту. Далее после labels указываем название сервиса и компонент virtualization:

Обращаем внимание, что вместо списка адресов присутствует вызов __address__. Файл с адресами всех нод генерируется при каждом прогоне плейбука,так что вводить огромное количество адресов не придется.
В самом начале документа после поля rule_files нужно указать имя написанного алерта:
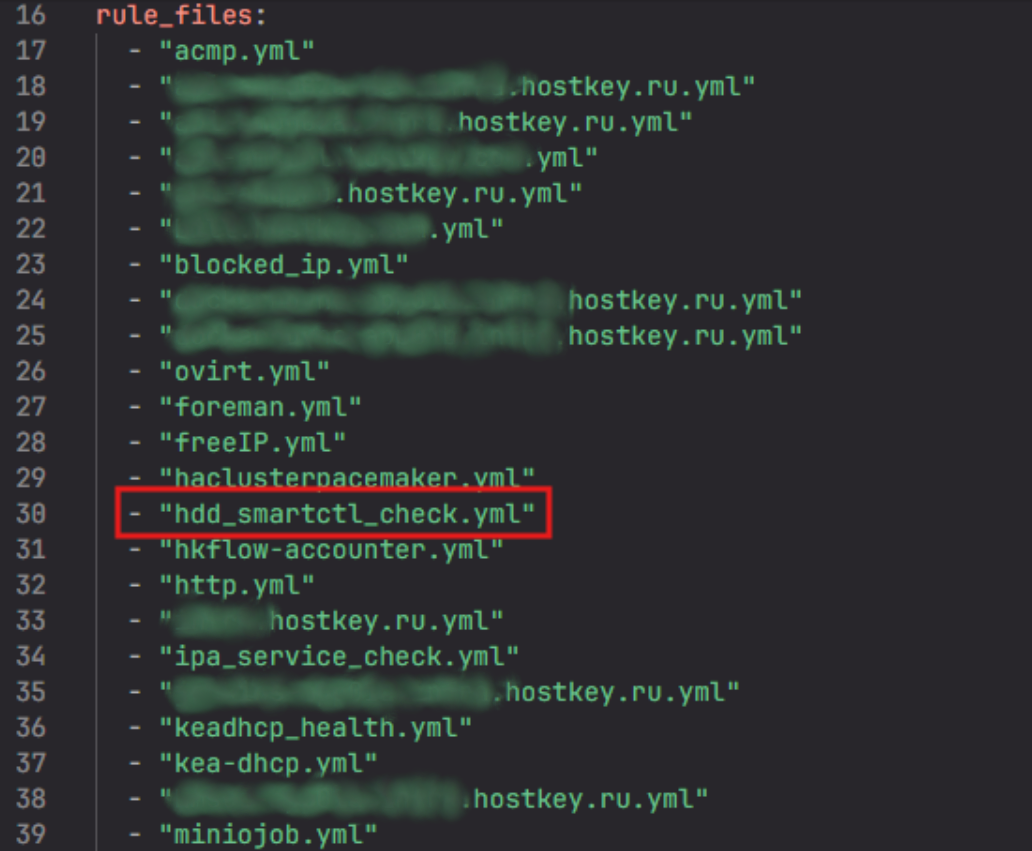
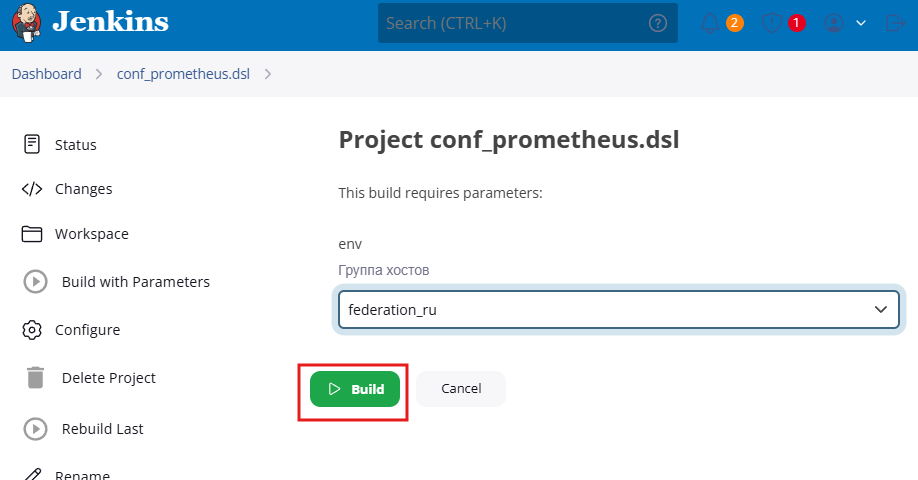
Далее переходим к нашей внутренней Jenkins-задаче conf_prometheus.dsl и запускаем обновление мониторинга для всех серверов:
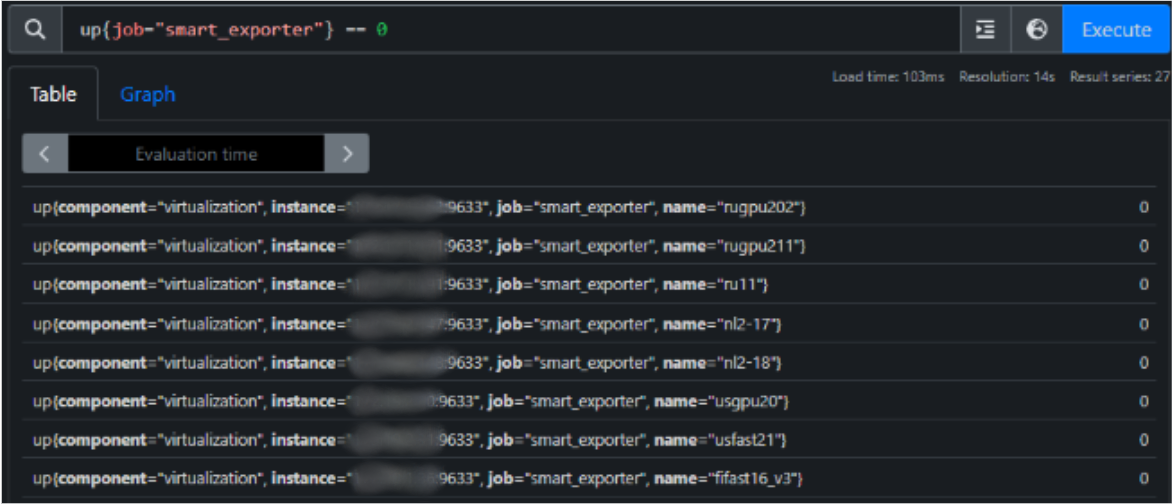
После успешного обновления следует перейти в веб-интерфейс Prometeus и проверить отработку таргета, введя имя искомого атрибута, например up{job="smart_exporter"} == 0. Если проблем не возникло, то вывод будет примерно таким:
Вывод алерта на дэшборд Grafana
Алерты из Prometheus далее идут в Grafana, где выводятся на общий дэшборд. В нашем случае необходимо вывести алерты на отдельный дэшборд приложения с метриками, связанными с oVirt.
Делается это следующем образом: открываем дэшборд oVirt в Grafana, выбираем Edit и вписываем название алерта в формате job!="cert_cheker". Обязательно после должна быть запятая, а если вписывается в середине поля, то с обоих сторон:

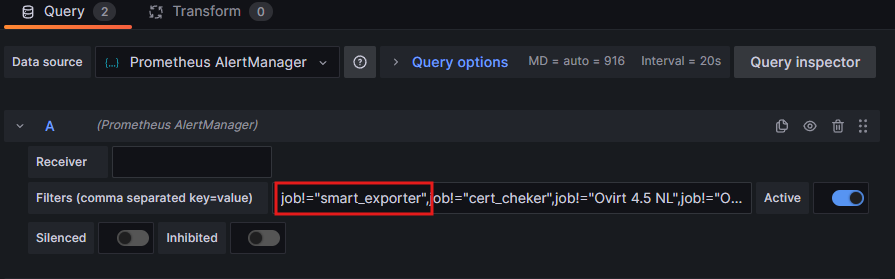
Далее идем в дэшборд Prometheus AlertManager — Ovirt checks:
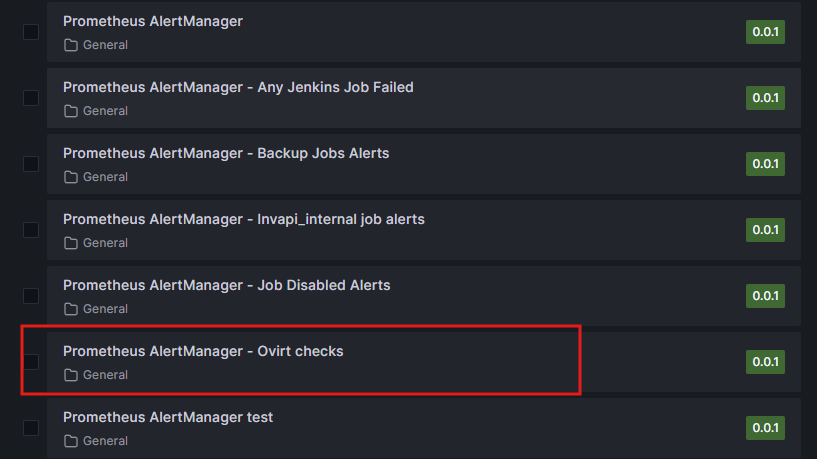
Снова заходим в настройки панели:
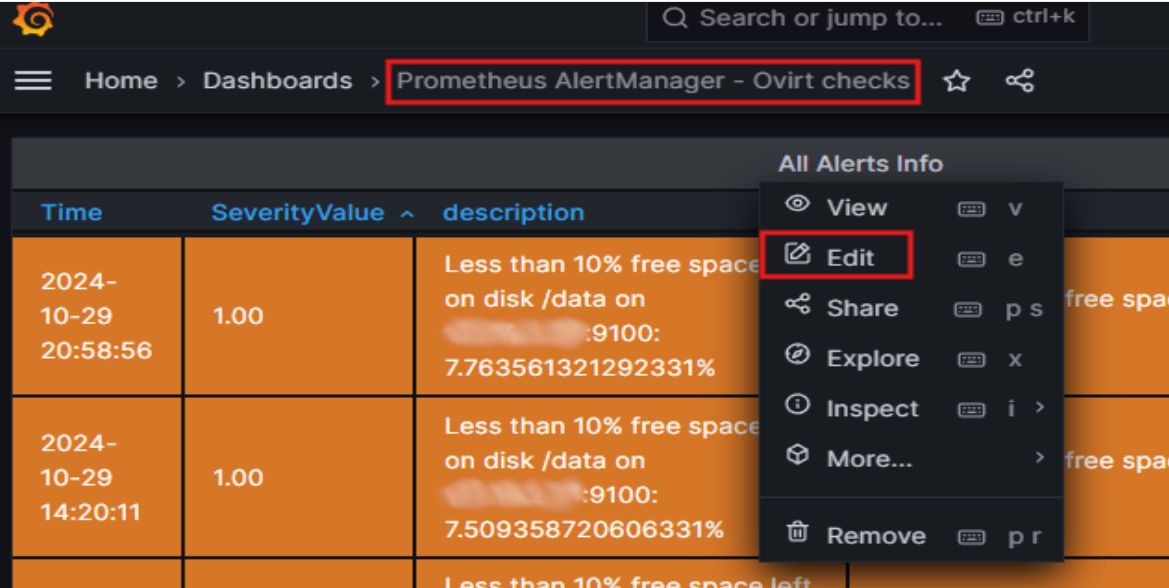
Жмем на добавление запроса (+ Query):
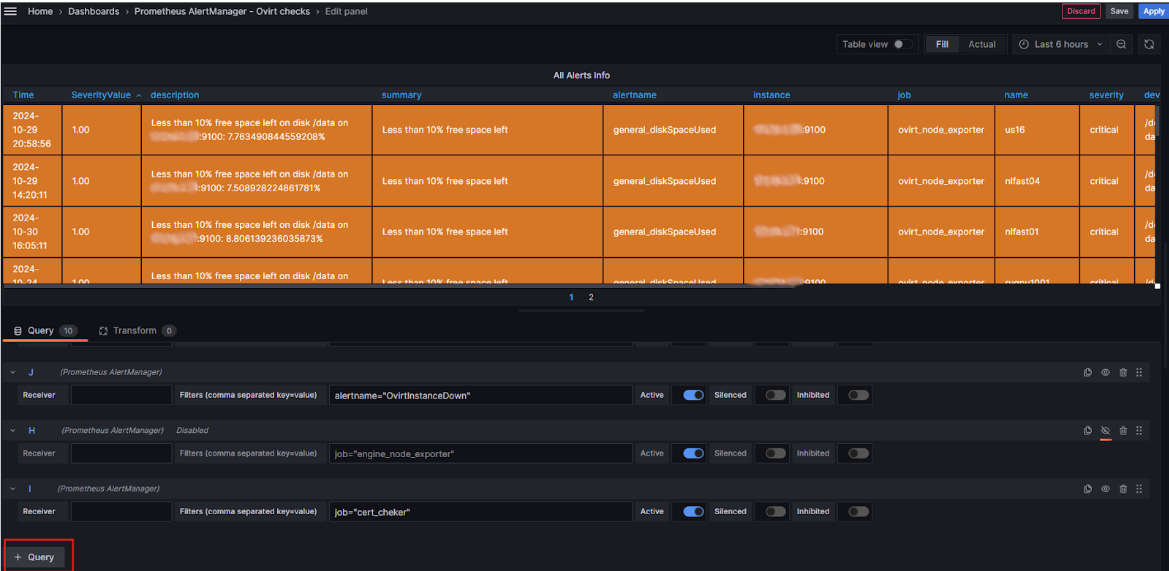
И в появившемся поле вписываем имя алерта в формате job="smart_exporter", после чего нажимаем Save в верхней части страницы:
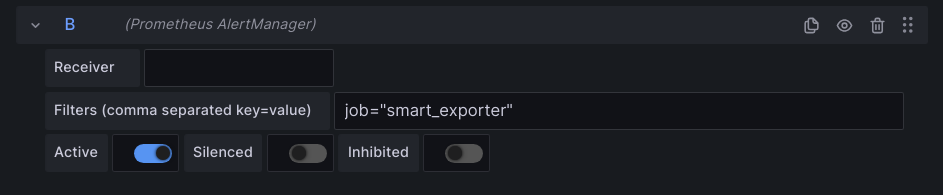
После выполненных действий алерт будет выводится а дэшборд oVirt — настройку можно считать оконченной.
Что можно сказать по итогу: инструмент хороший, позволяет извлекать значительное количество информации, но в текущей реализации работает преимущественно с HDD-дисками, а для SSD метрики по большей части выводятся не по классическому SMART-ATA-стандарту. И часть NVME-дисков вообще не видит (у нас таких, к счастью, не попалось). Поэтому для SSD-дисков пришлось разбирать «простыню» вывода и вычленять из нее нужные атрибуты и переписывать алерты. Также инструмент хорошо интегрируется только с Prometheus, но для нас это не критично.
А вы чем мониторите ваши диски на серверах?
Выделенные серверы с процессорами 4 поколения AMD EPYC 9354 / 9124 / 9554 / 9754 и Intel Xeon Silver 4416+
Арендуйте высокопроизводительный выделенный сервер на базе процессоров AMD EPYC и Intel Xeon последнего поколения, с оперативной памятью DDR5 и хранилищем NVME. Серверы доступны для заказа в ультрасовременном дата-центре в Москве и Амстердаме.
🔶 Инсталляционный платеж: Бесплатно 🔶 Скидка до 12% в зависимости от срока аренды 🔶 Время сдачи: следующий рабочий день