
Автор: Иван Богданов, Технический писатель / Technical Writer компании HOSTKEY
В одной из прошлых статей мы описали облачный проект за тысячу рублей. Представьте, что он выстрелил. Пользователи хлынули потоком, нагрузка выросла в десять раз, и теперь автоскейлинг регулярно поднимает 8–10 инстансов Node.js. Красиво работает, но счет за месяц неприятно вырос и продолжает ползти вверх. В какой-то момент вы смотрите на эти цифры и думаете: «А что, если просто взять нормальный сервер?»
Это классический путь эволюции проекта. Облако идеально для старта — быстро, гибко, без капитальных вложений, но когда нагрузка становится стабильной и предсказуемой, экономика меняется. Начальная конфигурация выделенного сервера с 4 ядрами, 32 GB RAM и RAID из SSD стоит 4500 ₽ в месяц (или 3600 ₽ при оплате за год). При постоянной нагрузке это значительно выгоднее, чем поддерживать облачный кластер из нескольких инстансов.
Что такое выделенный сервер
Выделенный сервер (dedicated server или в простонародье «дедик») — это физический сервер в дата-центре провайдера, который арендуется целиком под ваш проект. Не виртуальная машина, где ресурсы делятся с соседями, а целая железка: процессор, память, диски — всё работает только на вас. Никакой борьбы за CPU с десятком других клиентов, никаких просадок производительности из-за того, что сосед по гипервизору запустил обучение нейросети. Ресурсы предсказуемы, производительность стабильна.
Звучит идеально, но тут начинается самое интересное. «Взять сервер» — это как сказать «купить машину». Какую? Седан для города, внедорожник для бездорожья или спорткар для треков? Точно так же и с серверами: есть bare-metal для максимальной производительности, managed для тех, кто не хочет возиться с настройкой, GPU-серверы для машинного обучения, storage-конфигурации для терабайтов данных. Выбор зависит от задачи, бюджета и того, насколько глубоко вы готовы погружаться в администрирование.
Чтобы не потеряться в вариантах, разберем основные типы выделенных серверов.
Сравнительная таблица: типы выделенных серверов:
|
Тип сервера |
Краткое описание |
Аппаратная конфигурация |
Сценарий применения |
Преимущества |
Ограничения |
|
Bare-metal (физический) |
Физический сервер целиком в распоряжении одного клиента (по умолчанию нет уровня виртуализации). |
Высокопроизводительные CPU (Xeon/EPYC), до сотен ГБ/ТБ RAM, NVMe/SAS/SSD, аппаратные RAID, выделенный канал. |
БД с высокой нагрузкой, критичные веб-приложения, низколатентные сервисы, большие монолитные приложения. |
Максимальная производительность и предсказуемость, полный доступ к железу. |
Менее гибок в масштабировании по сравнению с облаком; требует настройки/поддержки (если unmanaged). |
|
Managed (управляемый) |
Провайдер обеспечивает мониторинг, бэкапы, патчи, поддержку 24/7. |
Любая из аппаратных конфигураций - важен уровень сервисов (SLA, резервирование). |
Компании без собственных сильных ИТ-команд, критичные сервисы, требующие SLA. |
Снижает нагрузку на команду, профессиональная поддержка, часто встроенные бэкапы и безопасность. |
Выше цена; ограниченная свобода/root-доступ в зависимости от провайдера. |
|
Unmanaged/Self-managed |
Клиент отвечает за установку, безопасность, обновления; провайдер лишь обеспечивает железо и сеть. |
Стандартный выделенный сервер, клиент сам настраивает ОС/ПО. |
Опытные системные админы, кастомные стеки, оптимизация под конкретные задачи. |
Низкая цена по сравнению с managed; максимум контроля. |
Требует навыков; ответственность за безопасность и обновления. |
|
GPU-серверы (вычислительные ускорители) |
Серверы с одной или несколькими мощными GPU (NVIDIA A100/H100, RTX и т.п.). |
Многоядерные CPU + 1–8+ GPU, быстрые NVMe, усиленная система охлаждения и питания. |
Тренировка/инференс ML-моделей, рендеринг, научные расчеты, CUDA/OpenCL-напр. |
Существенное ускорение параллельных вычислений; незаменимы для AI и рендеринга. |
Очень высокая стоимость GPU; потребление энергии и охлаждение; ограниченная доступность. |
|
Storage-optimized (NAS/SAN/NVMe) |
Оптимизированные под объем и надежность хранилища: NAS (файлы), SAN (блоки), NVMe (высокая IOPS). |
Множество HDD/SSD (включая NVMe), аппаратные контроллеры RAID, крупные массивы памяти в кеш. |
Архивы, мультимедиа, большие объемы данных, резервное копирование, хранилища виртуальных машин. |
Большой объем и надежность, оптимизация IOPS/пропускной способности. |
Стоимость за большой емкий пул; сложность резервирования и восстановления; сетевые требования (SAN/NAS). |
|
HPC/Compute-optimized |
Серверы для тяжелых вычислений и кластеров (научные расчёты). |
Многоядерные CPU (часто многосокетные), большой ECC RAM, быстродействующие NVMe, специализированные высокоскоростные сети. |
Научные расчеты, моделирование, аналитика, крупные базы данных, кластерные задачи. |
Очень высокая вычислительная плотность и пропускная способность; поддержка кластеров. |
Дорогие; требует специфической инфраструктуры и ПО; сложная настройка. |
|
Gaming/Low-latency (игровые) |
Выделенные серверы, оптимизированные по сети: DDoS-защита, низкая латентность и высокая пропускная способность. |
Высокочастотные CPU, достаточный RAM, NVMe для быстрых загрузок, географически распределенные точки присутствия. |
Хостинг игровых серверов (MMO, матчевые игры), киберспортивные турниры, ре-тайм приложения. |
Низкая задержка, DDoS-защита, готовые тул-киты для игр. |
Требуют оптимизации сети; конкуренция по локациям и пропускной способности. |
|
Colocation (размещение своего железа в ДЦ) |
Вы размещаете свое физическое оборудование в стойке провайдера и платите за пространство/питание/сеть. |
Любое свое железо (серверы собственной сборки или бренда). |
Компании, желающие владеть оборудованием, соблюдать нормативные требования, иметь полный контроль над железом. |
Полный контроль над аппаратной частью; можно выбирать конфигурацию без аренды. |
Высокие капитальные затраты (покупка оборудования), ответственность за обслуживание; нужна техническая команда на стороне клиента. |
Архитектура: все на одном железе
Принципиальное отличие от облака — мы больше не распределяем компоненты по разным виртуальным машинам. Всё живет на одном физическом сервере, но изолированно:
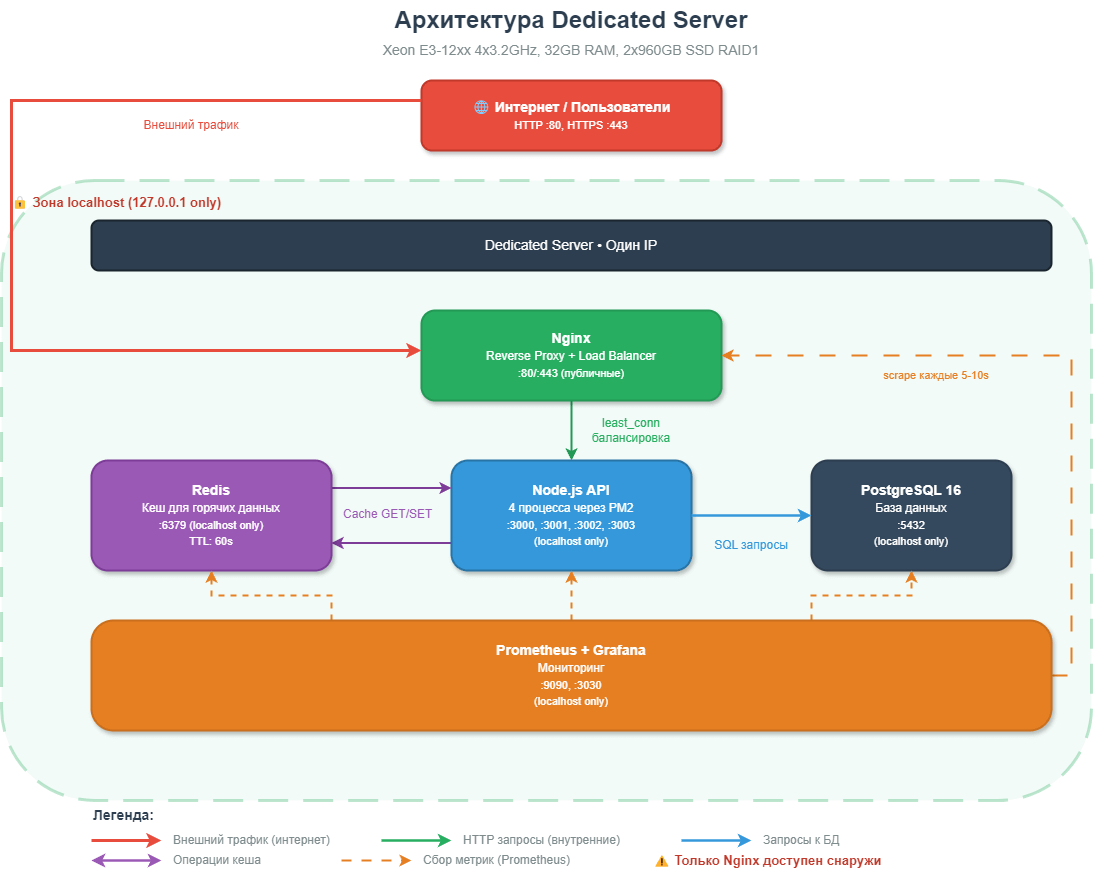
Ключевые отличия от VPS-архитектуры:
|
VPS (3 сервера) |
Dedicated (1 сервер) |
|
|
Сеть |
Внешние IP, межсерверное общение |
Все на localhost |
|
База |
MySQL на отдельном VPS |
PostgreSQL локально |
|
Кеш |
Не было |
Redis для /restaurants |
|
API |
1 процесс Node.js |
4 процесса через PM2 |
|
Прокси |
Не было |
Nginx с балансировкой |
|
Безопасность |
Firewall на каждом VPS |
Один firewall, Nginx auth |
|
Стоимость (рублей в месяц) |
1049 |
4500 |
Настройка - реальная оценка сложности
Не буду дублировать весь процесс развертывания, но давайте честно — это не «три клика», как в облаке. Настройка выделенного сервера требует знаний и времени, и я не хочу создавать иллюзию, что это простая задача.
Процесс начинается с базовой защиты сервера. Нужно настроить UFW-фаервол, установить Fail2Ban от брутфорса SSH, сгенерировать SSH-ключи и создать swap-файл. На это уйдет минут 30, если знаете, что делаете. Дальше — PostgreSQL 16, и вот тут начинается интересное. Сама установка занимает пять минут, но дальше нужно понять, что такое shared_buffers, как правильно выставить effective_cache_size под ваши 32 GB RAM, что делать с work_mem и почему random_page_cost для SSD должен быть 1.1, а не дефолтные 4.0. Каждый параметр влияет на производительность, и неправильная настройка может съесть половину потенциала сервера. Это час-два работы с документацией.
Redis ставится проще — тут основная задача понять политики вытеснения кеша. Нужно ли нам персистентность данных на диск или держим всё только в памяти? Какую стратегию выбрать — allkeys-lru или volatile-tti? Еще минут 30 на понимание и настройку Node.js и PM2 — тут час уходит на настройку кластера из 4 процессов, автозапуск при перезагрузке системы, правильное логирование и ротацию логов. PM2 в действии — 4 процесса Node.js в cluster-режиме, готовые обрабатывать запросы через Nginx:

Nginx как reverse proxy — это отдельная история. Нужно настроить проксирование к четырем процессам Node.js, выбрать стратегию балансировки (least_conn в нашем случае), настроить таймауты, keepalive соединения, правильно передать заголовки. Если нужен SSL — добавь еще час на получение сертификатов через Let's Encrypt и настройку редиректов. И, наконец, Prometheus с Grafana — установка, конфигурация scrape targets для всех компонентов, создание базовых дашбордов для мониторинга. Еще час-два, но мониторинг и графики того стоят.
Реальное время? Для опытного DevOps-специалиста, который знает эти технологии и просто настраивает их под конкретный кейс, часов 4–6 с учетом тестирования и отладки. Для разработчика с базовыми знаниями Linux, который будет гуглить половину команд и читать документацию, день-два. Для новичка, который впервые сталкивается с production-настройкой Linux-сервера, дня три-пять с учетом обучения и исправления ошибок.
И самое важное — нужно понимать основы Linux: как работает файловая система, права доступа, systemd-сервисы. Нужно знать базовую безопасность — как работает SSH, зачем нужен фаервол, как настроить fail2ban. Понимать, как работают веб-серверы и reverse proxy. Разбираться в основах SQL и настройке СУБД. Уметь настроить мониторинг и отлаживать проблемы, когда что-то пошло не так.
Это не игрушечный проект для туториала — это production-стек, который требует ответственности. Если сервер упадет в три часа ночи — чинить придется самостоятельно. Техподдержка провайдера выделенного сервера заменит только сгоревшее железо, но разбираться, почему упал PostgreSQL или закончилась память — это ваша личная задача.
Тестирование
После настройки сервера самое время проверить, насколько хорошо он справляется с реальной нагрузкой. Тесты не ради красивых цифр в отчете, а чтобы понять пределы системы, найти узкие места и убедиться, что под нагрузкой всё работает стабильно. Запускаем два типа тестов: latency test (последовательные запросы для измерения чистой скорости ответа) и load test (параллельные клиенты для имитации реальной нагрузки).
Методология
Все тесты запускаются с клиентской машины через PowerShell-скрипты, имитируя реальных пользователей с разной интенсивностью запросов. Это важный момент — мы не гоняем Apache Bench с localhost, а создаем реальную сетевую нагрузку через интернет. Эндпоинт для теста — GET /api/restaurants, который возвращает список ресторанов из PostgreSQL с кешированием в Redis на 60 секунд и имитацией CPU-нагрузки (100 000 итераций математических вычислений для каждого запроса).
Latency Test: проверка чистой скорости
Первый тест — 100 последовательных запросов с задержкой 50 мс между ними. Цель — измерить минимально возможную задержку системы без конкуренции за ресурсы.
|
Метрика |
Значение |
|
Успешных запросов |
100/100 (100%) |
|
Средняя латентность |
58.23 мс |
|
Медиана |
56.32 мс |
|
P95 |
60.17 мс |
|
P99 |
62.24 мс |
|
Максимум |
209.19 мс |
|
Стандартное отклонение |
15.24 мс |
99% запросов обрабатываются за 50-100 миллисекунд, что очень быстро для API с обращением к базе данных. Один выброс в 209 мс — это нормально и может быть связано с garbage collection, промахом кеша или кратковременной нагрузкой на CPU. Стандартное отклонение всего 15.24 мс говорит о стабильной работе системы.
Multi-Client Test: имитация реальных пользователей
Второй тест — 10 параллельных клиентов делают запросы в течение 4 минут с задержкой 10 мс между запросами. Это имитация умеренной, но постоянной нагрузки.
|
Метрика |
Значение |
|
Длительность теста |
253 сек (4 мин 13 сек) |
|
Всего запросов |
30,494 |
|
Успешных запросов |
30,494 (100%) |
|
Ошибок |
0 |
|
Средний RPS |
120.48 req/sec |
|
Латентность мин |
53.02 мс |
|
Латентность средняя |
57.32 мс |
|
Латентность макс |
342.33 мс |
|
Запросов на клиента |
~3,049 |
Сервер легко справляется со 120 RPS без единой ошибки. Средняя латентность практически не изменилась по сравнению с одиночными запросами (57 мс против 58 мс), что говорит о хорошей масштабируемости. Максимальная латентность выросла до 342 мс, но это все еще приемлемо — вероятно, связано с конкуренцией за соединения к PostgreSQL или моментами, когда кеш Redis истекал.
Роль Redis кеша
Отдельного внимания заслуживает влияние Redis на производительность. График Cache Hit Rate за период тестирования показывает две четкие волны активности:
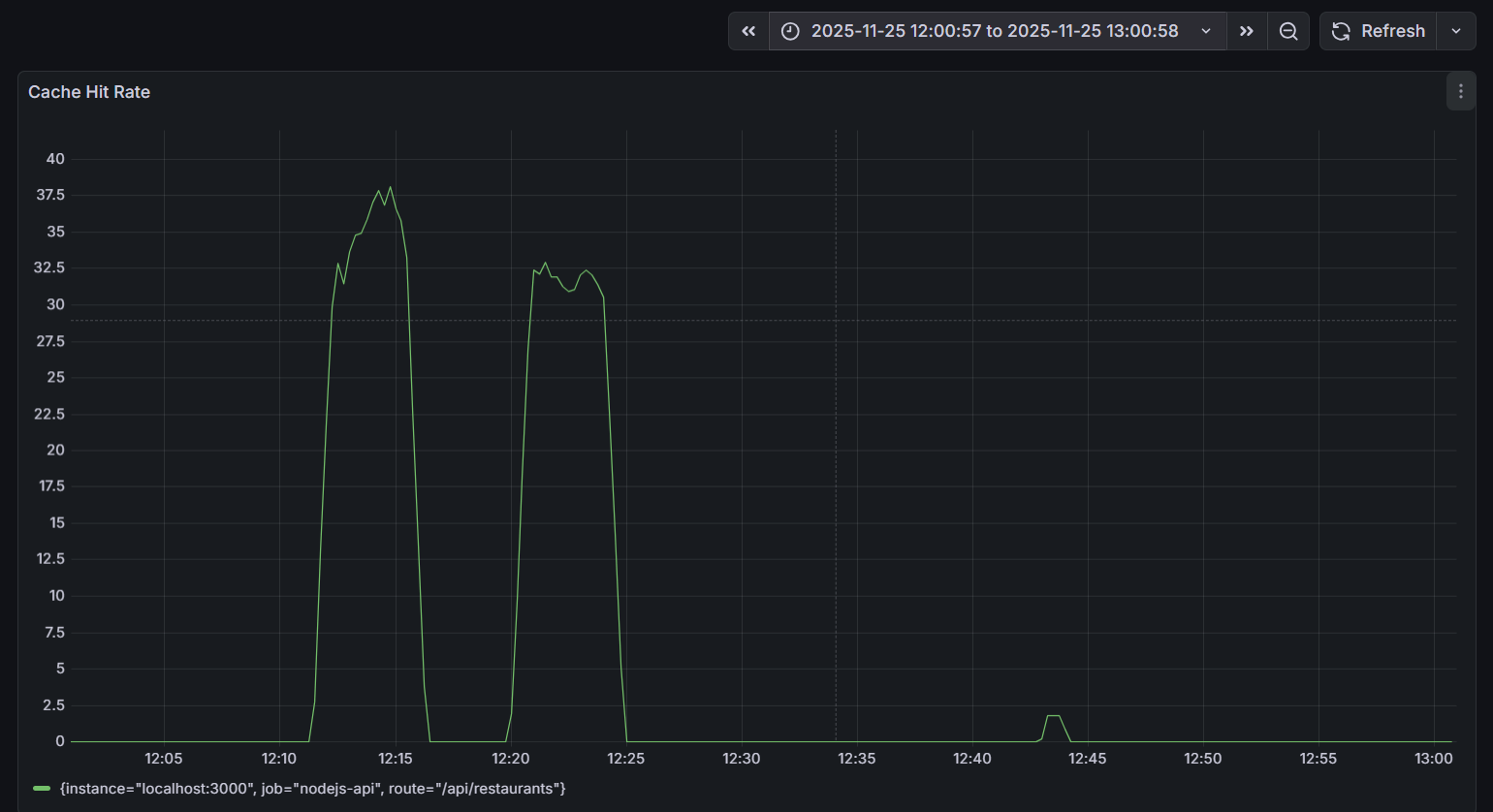
Запросы к Redis-кешу в памяти обрабатываются на порядок быстрее, чем запросы к PostgreSQL с диска (средняя латентность 57 мс). При пиковых 37 cache hits/sec из общих 120 RPS это означает, что ~30% запросов существенно ускоряются, снижая общую нагрузку на базу данных.
Сравнение с облачной архитектурой
Напомню, в облачной версии у нас было три виртуальные машины за ~1000₽/месяц с аналогичным функционалом. Выделенный сервер за 4500₽ дает отличную производительность, более стабильную латентность, Redis-кеширование из коробки, полный контроль над конфигурацией и предсказуемую стоимость, но за это приходится платить временем на настройку, администрирование и мониторинг.
Практический вывод: цифры подтверждают экономическую целесообразность перехода на выделенный сервер при стабильной нагрузке, но только если есть DevOps-компетенции для настройки и поддержки. Сервер работает быстрее и стабильнее облака при правильной конфигурации, но требует умения эту конфигурацию создать и поддерживать.
Выводы
Наш эксперимент показал две вещи одновременно, и обе правдивы. Облако не всегда дороже — для старта, для непредсказуемых нагрузок, для команд без DevOps-опыта оно оптимально и часто единственно разумно. Выделенный сервер не устарел и не избыточно сложен — для стабильных нагрузок, для команд с DevOps-компетенциями, для проектов с предсказуемым трафиком он экономичнее и производительнее.
Главная ошибка, которую я вижу в обсуждениях облака против выделенного сервера, — это выбор технологии по хайпу или по цене в вакууме. «Все идут в облако, значит и мне надо» — плохая мотивация. «Дедик в три раза дешевле, надо экономить» — тоже плохая мотивация, если не учитывать скрытые затраты времени. Выбирайте то, что решает вашу конкретную задачу с оптимальным для вас соотношением цены, производительности, удобства и требуемых компетенций.
Мы начали с трех облачных виртуальных машин за тысячу рублей, получили работающее API, поняли архитектуру, набили руку на реальной нагрузке. Затем перешли на выделенный сервер за 4500 ₽ и получили в полтора раза больше производительности при меньших затратах под постоянной нагрузкой, но путь от облака к выделенному серверу занял время — нужно было всё настроить, отладить, протестировать, убедиться, что мониторинг работает, что бэкапы делаются, что при падении систему можно быстро восстановить.
Выделенный сервер не «лучше» облака, и облако не «лучше» выделенного сервера — они просто разные. Выделенный сервер дешевле по деньгам, но дороже по времени. Дает больше контроля, но требует больше ответственности. Обеспечивает более высокую производительность за счет выделенных ресурсов, но сложнее в настройке и поддержке. Предсказуемая фиксированная цена против непредсказуемых инцидентов, которые нужно уметь чинить.
Если есть сомнения, то лучше начинать с облака. Это правильный совет для 80% проектов. Облако даст вам скорость запуска, позволит сфокусироваться на продукте, а не на настройке PostgreSQL. Когда проект дорастет, когда появятся стабильные паттерны нагрузки, когда в команде будет человек с DevOps-опытом, тогда можно осознанно принять решение о миграции на выделенный сервер. Это должно быть осознанное решение с пониманием всех trade-offs, а не просто «давайте сэкономим».
Главный урок нашего кейса — инфраструктура должна служить бизнесу, а не наоборот. Если облако позволяет быстрее делать фичи и масштабироваться без головной боли — стоит выбрать его. Если выделенный сервер экономит бюджет при наличии компетенций для его поддержки — то его и нужно брать.