
Автор: Иван Богданов, Технический писатель / Technical Writer компании HOSTKEY
В предыдущих статьях мы прошли путь от облачных VPS за тысячу рублей до выделенного сервера за 4500 рублей. Облако дает гибкость и быстрый старт, выделенный сервер принес производительность и предсказуемую цену, но что, если не выбирать между ними, а использовать оба подхода одновременно?
Представьте ситуацию. Ваш проект вырос, вы перешли на выделенный сервер. Базовая нагрузка стабильна — выделенный сервер справляется отлично. Однако раз в неделю бывают пики: маркетинг запускает акцию, блогер упомянул ваш сервис, или просто пятничный вечер принес в три раза больше заказов. В эти моменты сервер задыхается, пользователи видят таймауты, а вы нервно смотрите на графики CPU и думаете: «Докупить ли второй дедик на 4500 ради двух часов пиковой нагрузки в неделю?»
Это классический кейс для гибридной архитектуры.
Что такое гибридная архитектура
Гибридная архитектура — это когда стабильная базовая нагрузка обрабатывается на выделенном сервере, а пиковая — на временных облачных инстансах. Ключевое отличие от чистого облака или чистого выделенного сервера — эластичность по требованию. База работает постоянно на железе, которое вы арендуете на долгий срок. Пики покрываются облачными воркерами, время жизни которых определяется вашими потребностями (хоть минуты, хоть часы) и стоит копейки. Вы не переплачиваете за простаивающие мощности и не душите пользователей таймаутами во время пиков.
Сравним:
|
Параметр |
Облако |
Выделенный сервер |
Гибрид (облако + выделенный) |
|
Базовая стоимость (руб/мес) |
от 1000 |
от 4500 |
от 4800 |
|
Стоимость при пиках |
+1000 рублей × N часов автоскейлинга |
не изменяется, ресурсов может не хватить |
+260 рублей × N воркеров × часы |
|
Производительность |
средняя, зависит от соседей по гипервизору |
высокая, предсказуемая |
высокая база + эластичные пики |
|
Сложность настройки |
низкая (managed сервисы) |
средняя (ручная настройка) |
высокая (два контура инфраструктуры) |
|
Гибкость/адаптируемость |
максимальная |
минимальная |
высокая |
|
Требуемые навыки |
базовые DevOps |
средние Linux/DB |
продвинутые DevOps + networking |
|
Время масштабирования |
30-60 сек (автоскейлинг) |
часы/дни (дозакупка железа) |
60-90 сек (создание VPS) |
|
Управление |
API/вебка провайдера облака |
ручное |
Скрипты автоматизации |
|
Кейсы |
стартап с непредсказуемым ростом, пилотные проекты, сезонный бизнес |
базы данных, CI/CD, внутренние сервисы с ровной нагрузкой |
Продуктовая среда со стабильной базой и периодическими всплесками (акции, рассылки, отчёты) |
- Когда и что имеет смысл выбрать:
- Облако — стартапы на этапе поиска ниши, сезонный бизнес (туризм, e-commerce перед праздниками), MVP и эксперименты, когда непонятно, какая нагрузка будет через час или завтра.
- Выделенный сервер — базы данных, CI/CD раннеры, внутренние сервисы компании, всё, где нагрузка ровная и предсказуемая 24/7, а скачки если и бывают, то в пределах 20–30%.
- Гибрид — продуктовые системы с выраженными пиками: онлайн-кинотеатры (премьеры, вечерние часы), билетные сервисы (старт продаж), образовательные платформы (начало курсов, дедлайны), маркетинговые акции, почтовые рассылки, вебинары — любые сценарии, где вы заранее знаете, что нагрузка вырастет в разы.
Для примера приведу ключевые случаи, когда гибрид является оптимальным выбором:
|
Сценарий |
Типичные примеры |
Критерий выбора гибрида |
Архитектурное решение |
|
Низкая задержка и близость к данным |
Финтех/HFT, SCADA, игровые серверы, управление оборудованием |
Задержка < 1–10 мс |
Критичные сервисы и БД - он-прем; аналитика и бэкапы - облако |
|
“Гравитация данных” |
Телеком, видеоплатформы, промышленные сенсоры |
TB-PB данных; дорогой исходящий трафик |
Первичные данные локально; облако - для агрегации и ML |
|
Регуляторика и резидентность |
Банки, медицина, госсектор, 152-ФЗ/GDPR |
Данные не должны покидать юрисдикцию |
Чувствительные данные он-прем; облако - после анонимизации |
|
Легаси-системы |
ERP, CRM, банковский процессинг, промышленные контроллеры |
Высокие риски рефакторинга; зависимость от железа |
Ядро он-прем; постепенная контейнеризация и вынос API-шлюзов |
|
Пиковые нагрузки |
E-commerce (распродажи), бухгалтерия (отчётный период), маркетинговые кампании |
Пик > 2–3× от базы, краткосрочно |
Stateful-часть он-прем; фронты и вычисления - автомасштабирование в облаке |
|
Дорогой исходящий трафик |
Стриминг, видеохостинг, бэкапы больших объёмов |
Постоянный обмен > 10–20 TB/день |
«Горячие» данные локально; «холодные» архивы — в облаке |
|
Отказоустойчивость и георезерв |
Критичные сервисы с жёстким SLA |
SLA требует доступность 99,9% + и защиту от локальных катастроф (пожар, наводнение, отключение ЦОД). RTO < 1 часа, RPO < 15 минут. Один сайт не обеспечивает требуемую отказоустойчивость. |
Две схемы резервирования: актив-пассив (он-прем работает, облако ждёт аварии) или актив-актив (оба сайта под нагрузкой, трафик балансируется). Данные синхронизируются между площадками синхронно (без потерь, но медленнее) или асинхронно (быстрее, но возможна потеря последних секунд при сбое) |
|
Эдж и IoT |
Фабрики, розница, автономные системы |
Обработка у источника; агрегация в центре |
Локальные эдж-ноды + центральная аналитика в облаке |
|
Слияния и поглощения |
Интеграция разнородной инфраструктуры |
Быстрое объединение без полной миграции |
Гибрид как слой интеграции: федеративная идентификация, единый мониторинг |
|
AI/ML-пайплайны |
Обучение моделей, масштабируемый инференс |
Большие датасеты локально; потребность в эластичном выводе |
Данные и GPU-кластер он-прем; инференс в облаке с автомасштабированием |
Архитектура: получаем лучшее из двух миров
Принципиальное отличие гибридной архитектуры — разделение ответственности между стабильной базой и эластичными воркерами. Давайте разберем конкретный пример автомасштабируемой архитектуры, чтобы увидеть, как это работает на практике. Возьмем наш кейс с сервисом доставки еды из прошлых статей.
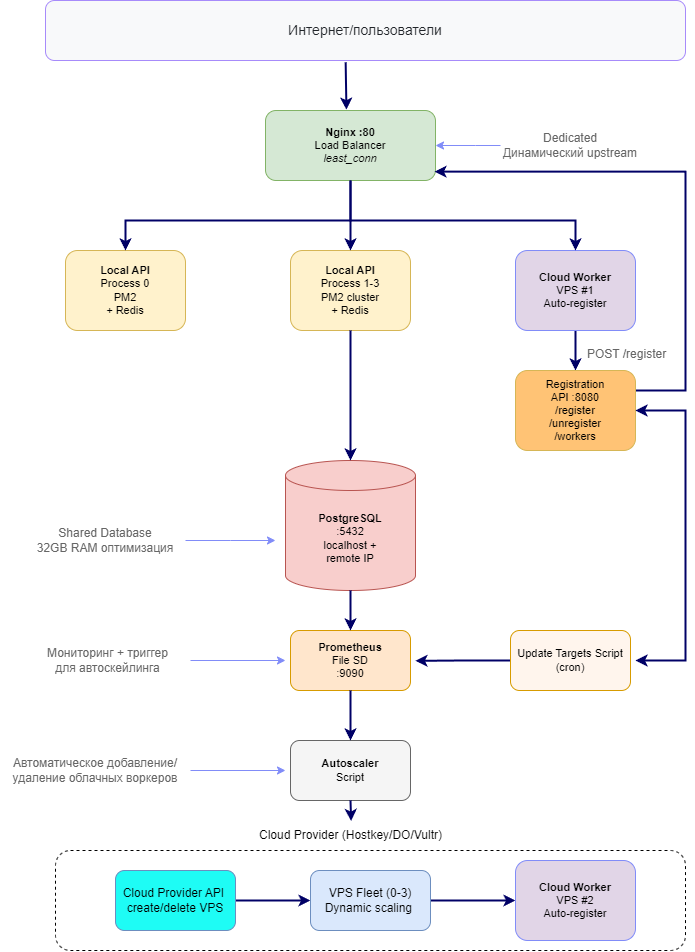
Базовый слой (выделенный сервер) — это фундамент системы за 4500₽/мес. PostgreSQL 16 с оптимизацией под 32GB RAM выступает единственным stateful компонентом, рядом с ним Redis кеширует горячие запросы вроде /api/restaurants с TTL 60 секунд. Четыре процесса Node.js через PM2 cluster обрабатывают базовую нагрузку, Nginx работает как обратный прокси и балансировщик нагрузки с динамическими серверами бэкенда, а Prometheus с Grafana следят за всей системой:
Эластичный слой (Cloud Workers) добавляет VPS vm.nano (1 core, 1 GB RAM) по требованию. Каждый воркер — это Node.js процесс с автоматической регистрацией в Nginx, который подключается к общей PostgreSQL на выделенном сервере. Живут воркеры от 10 минут до нескольких часов, стоят около 0,4 руб/час (260 руб/мес ÷ 720 часов).
Worker Registration API (выделенный сервер) — мозг системы. Простой Express-сервер с тремя endpoints: регистрация воркера, удаление из балансировки и список активных. Воркер стартует, через 2 секунды шлет POST на /register, API добавляет строку server ${ip}:${port} max_fails=3 fail_timeout=30s; в /etc/nginx/conf.d/upstreams/cloud-workers.conf, делает nginx -s reload, и через 5 секунд воркер уже получает трафик.
Динамический Nginx собирает upstream из двух файлов. Статичный local.conf содержит четыре локальных процесса с weight=2, а cloud-workers.conf меняется на лету при автоскейлинге. Nginx использует стратегию least_conn и после каждого изменения файла выполняет перезагрузку без простоя.
Cloud Worker — практически копия локального API, но подключается к remote PostgreSQL и не использует Redis. Это добавляет 10–20 ms к латентности, зато упрощает архитектуру — один источник данных для всех. При старте воркер ждет 2 секунды и автоматически регистрируется в Nginx через fetch-запрос. Никакой ручной настройки.

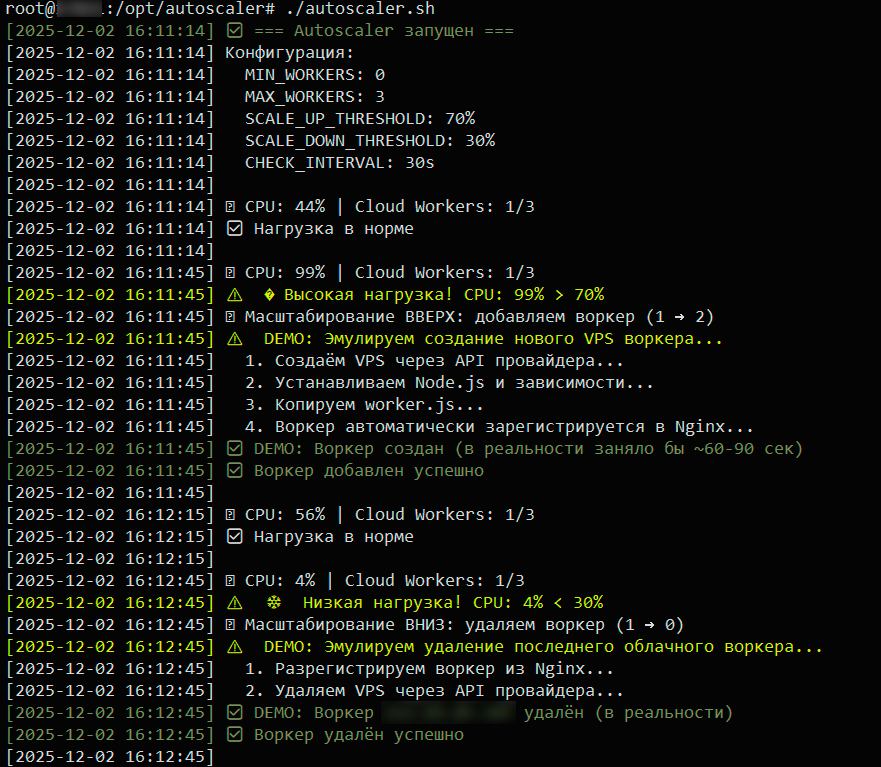
Запускаем autoscaler и генерируем агрессивную нагрузку с wrk (8 потоков, 400 соединений). Система мгновенно реагирует: CPU подскакивает с 44% до 99%, autoscaler принимает решение масштабироваться вверх, и в production это означало бы API-вызов к провайдеру для создания VPS, ожидание 60–90 секунд, пока воркер загрузится и зарегистрируется в Nginx. Через 30 секунд CPU падает до 56% — нагрузка распределилась.
Останавливаем нагрузочный тест, CPU проседает до 4%, и система принимает решение масштабироваться вниз — удаляет воркер, экономя 0,4 рубля за каждый час простоя. Логика autoscaler работает: система видит реальную нагрузку через Prometheus, принимает правильные решения, соблюдает пороги MIN/MAX workers и не паникует на кратковременных скачках. Для production осталось только заменить DEMO-функции на реальные API-вызовы к облачному провайдеру.
Настройка - честная оценка сложности
Не будем врать — настроить гибридную архитектуру сложнее, чем просто «взять VPS» или «купить дедик». Это требует понимания сразу нескольких технологий и умения их связать вместе.
PostgreSQL для удаленного доступа — сама установка занимает 5 минут, но настроить безопасный удаленный доступ — это отдельная задача на 1–2 часа. Нужно изменить listen_addresses с localhost на конкретный IP (не 0.0.0.0 для безопасности), настроить pg_hba.conf с белым списком IP адресов облачных воркеров, открыть порт 5432 в firewall только для известных IP и оптимизировать параметры под 32 GB RAM. Ошиблись хоть в одном — воркер не подключится или подключится кто попало.
Nginx с динамическими серверами бэкенда настроить как обратный прокси просто, но сделать так, чтобы он перечитывал список бэкендов на лету без даунтайма, требует понимания, как работают include директивы, зачем нужен nginx -s reload вместо restart, почему least_conn лучше round-robin для нашего кейса. Это еще 1-2 часа.
Worker Registration API — написать сам API на Express занимает час, но обеспечить безопасность — это другое дело. Слушать на 0.0.0.0, но только для known IP через firewall, валидировать входные данные (не добавить случайно ; rm -rf /), правильно писать в файлы от имени root, обрабатывать ошибки при reload Nginx. Плюс тестирование — убедиться, что при падении воркера не падает весь балансировщик. В сумме 2–3 часа.
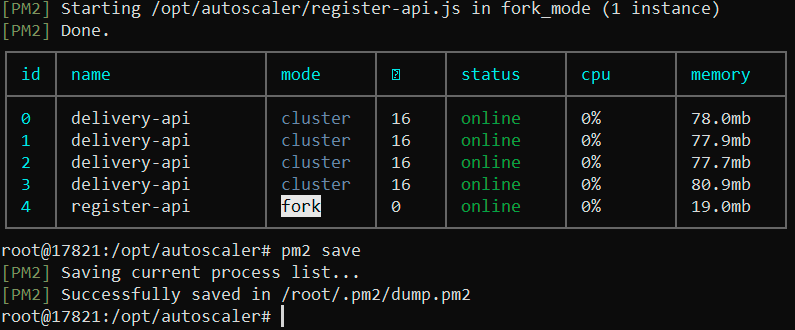
Облачный воркер — создать отдельный worker.js вместо копирования server.js правильное решение. Это позволяет убрать зависимость от Redis, добавить логику автоматической регистрации при старте, установить метку server_type: 'cloud' для отслеживания в метриках. Но учтите: на облачном VPS могут быть старые версии Node.js, другая версия npm, конфликты с Docker. Мы столкнулись с Node.js v12 вместо v20 — пришлось обновлять, а это еще час на разбирательства.
Prometheus с file-based service discovery - для динамических облачных воркеров нужно понять как работает file_sd_configs, написать скрипт который генерирует JSON, добавить его в crontab и убедиться что Prometheus подхватывает новые targets за 30 секунд. Еще 1-2 часа.
Autoscaler скрипт — самая сложная часть на 3–4 часа. Скрипт каждые 30 секунд запрашивает avg CPU из Prometheus через PromQL, принимает решение создавать воркер (CPU > 70%) или удалять (CPU < 30%), интегрируется с API провайдера, ждет, пока VPS создастся (~60–90 сек) и воркер зарегистрируется, логирует все действия и соблюдает лимиты MIN_WORKERS / MAX_WORKERS. Мы сделали DEMO версию без реального API — она просто эмулирует создание/удаление. Для продуктовой среды нужно добавить 2–3 часа на интеграцию с конкретным провайдером.
Реальное время? Для опытного DevOps с опытом Nginx, PostgreSQL, Prometheus и облачными API — день работы (6–8 часов чистого времени с учетом отладки). Для разработчика с базовыми знаниями Linux, который будет гуглить половину команд, — два-три дня. Для новичка — лучше не браться. Серьезно. Сначала лучше освоить каждый компонент: PostgreSQL, Nginx, Prometheus. Гибридная архитектура — это не учебный проект, это продуктовый стек, требующий знаний и отработанных навыков.
Выводы
Гибридная архитектура — это не универсальная таблетка от всех болезней, а инструмент для конкретной ситуации: у вас есть стабильная базовая нагрузка, которая отлично живет на выделенном сервере, но периодически случаются пики и начинаются проблемы с производительностью.
Экономика простая. Выделенный сервер стоит 4500 рублей в месяц, это фиксированная база. Облачный воркер съедает примерно 0,4 рубля в час, то есть 260 рублей, если работает месяц. Вам он не нужен нон-стоп — нужно два воркера на три часа в пятницу вечером, один воркер на час в понедельник утром и четыре воркера на два часа, когда маркетинг запустил акцию. Это копейки. За месяц вы потратите 200–300 рублей на эластичность вместо 4500 рублей на второй выделенный сервер, простаивающий 90% времени. Разумеется, в наших расчетах не учитываются расходы на труд инженеров, только непосредственно траты на инфраструктуру.
Сложность настройки — да, она есть. Мы прошли весь путь и примерно оценили затраты времени. Это не «кликнуть кнопку в панели» и не «два часа вечером после работы». Придется разбираться с PostgreSQL, удаленным доступом, Nginx, динамическими апстримами, Prometheus, service discovery и писать autoscaler. Что важно — эту настройку вы делаете один раз. Дальше система работает сама: воркеры появляются, когда нужно, исчезают, когда не нужно, а вы просто смотрите в Grafana, как оно само себя масштабирует.
Альтернативы? Можно докупить второй выделенный сервер за 4500 рублей и не беспокоиться, но тогда вы переплачиваете 54 тысячи в год за железо, которое большую часть времени простаивает. Можно переехать в облако целиком и платить за автоскейлинг, но там вы теряете в производительности и стабильности — привет соседям по гипервизору. Можно оставить всё как есть и мириться с таймаутами в пики, но тогда пользователи могут уйти к конкурентам.
Последний момент — это не конечная точка эволюции. Гибридная архитектура — это промежуточный этап между «у меня один дедик» и «у меня Kubernetes-кластер на трех дата-центрах». Когда проект вырастет еще больше, вы придете к оркестрации контейнеров, service mesh и всей этой сложной инфраструктуре. На этапе «выделенный сервер справляется, но иногда задыхается» гибрид дает максимум пользы за минимум усилий. Настроили один раз, дальше оно работает само, а вы спокойно запускаете маркетинговые акции, зная, что система выдержит.