
Open WebUI — вебинтерфейс с открытым исходным кодом, предназначенный для работы с различными LLM-интерфейсами, такими как Ollama или другими совместимыми с API от OpenAI. Он предлагает широкий спектр функций — основные из них направлены на повышения удобства в управлении моделями и запросах к ним. Вы можете развернуть Open WebUI как на сервере, так и локально на своей домашней машине и получить нейросетевой комбайн у себя на столе.
Платформа позволяет пользователям легко взаимодействовать и управлять моделями языкового обучения (LLM) через интуитивно понятный графический интерфейс как на ПК, так и с мобильных устройств, в том числе голосом в стиле чатов OpenAI.
Поскольку Open WebUI продолжает развиваться благодаря активному сообществу пользователей и разработчиков, которые вносят свой вклад в его совершенствование, то, с одной стороны, происходит постоянное улучшение платформы, добавление новых функций и оптимизацию существующих, а с другой — документация не успевает за всеми этими изменениями. Поэтому мы решили дать 10 советов, которые помогут вам раскрыть потенциал Ollama, Stable Diffusion и самого Open WebUI. Все примеры приведены для англоязычного интерфейса, но вы интуитивно найдете нужные пункты и разделы в Open WebUI и на других языках.
Попробуйте AI-чат-бот на собственном GPU-сервере.
HOSTKEY предлагает персональный AI-чат-бот на основе Ollama и OpenWebUI с предустановленной моделью Llama3.1 8b, который доступен на вашем собственном сервере! Это инновационное решение разработано для тех, кто ценит безопасность данных, масштабируемость и экономию средств.
Основные преимущества
- Безопасность и конфиденциальность данных. Все данные обрабатываются на вашем сервере, что исключает доступ третьих лиц к конфиденциальным данным.
- Экономия средств. Оплачивайте только аренду сервера — использование нейросети бесплатно, стоимость не зависит от количества пользователей.
- Масштабируемость. Легко переносите чат-бот между серверами, увеличивайте или уменьшайте вычислительные мощности и контролируйте расходы.
- Гибкая настройка. Подключайте и настраивайте различные LLM-модели, в том числе Phi3, Mistral, Gemma и Code Llama.
Совет 1. В Open WebUI можно поставить любую модель для Ollama из списка поддерживаемых
Для этого достаточно перейти по ссылке https://ollama.com/library и с помощью поисковой строки найти нужную модель. Если в названии модели нет префикса до /, значит она загружена разработчиками Ollama и проверена на работоспособность, если есть — эта модель загружена сообществом.
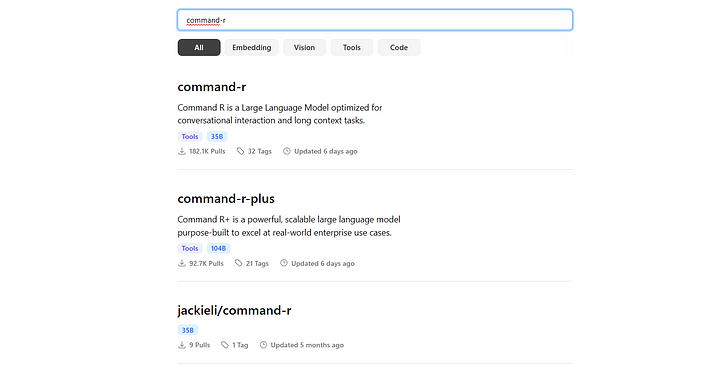
Обращайте внимание на теги у модели: последний показывает ее размер в миллиардах параметров. Чем это число больше, тем «мощнее» модель, но тем больше места в памяти она занимает. Вы также можете выбирать модели по типу:
- Tools — модели как для общего применения в режиме «запрос — ответ», так и для специализированного (математические и т. п.).
- Code — модели, которые натренированы на написание кода.
- Embeding — модели, которые необходимы для преобразования сложной структуры данных в более простую форму. Они нужны для поиска информации в документах, разбора данных поиска в интернете, создания RAG и т. п.
- Vision — мультимодальные модели, которые могут распознать загруженную картинку, ответить на вопросы по ней и т. п.
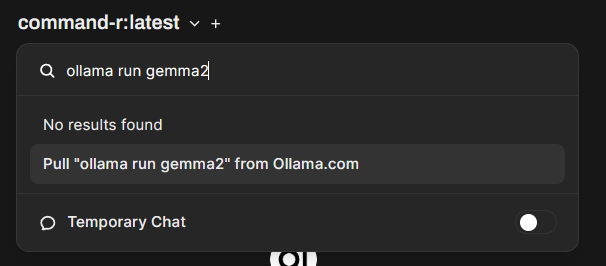
Для установки модели в Open WebUI нужно зайти в ее карточку, выбрать ее размер и сжатие из выпадающего списка и скопировать код типа ollama run gemma2. Затем нужно перейти в Open WebUI, вставить данную команду в строку поиска, появляющуюся по клику на название модели и кликнуть на текст Pull ollama run gemma2 from Ollama.com.
Через некоторое время (зависит от размера модели) модель будет скачана и установлена в Ollama.
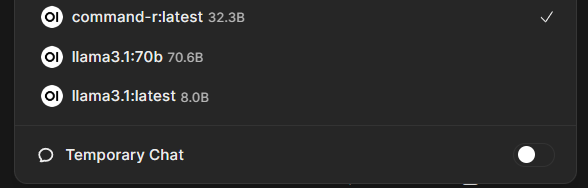
Совет 2. В Open WebUI можно поставить модель большего размера, чем видеопамять вашей видеокарты
Некоторые пользователи беспокоятся, что выбранная ими модель «не влезет» в имеющийся объем видеопамяти. Ollama (а точнее лежащая в ее основе llama.cpp) может работать в режиме GPU Offload, то есть слои нейросети будут разделяться при вычислениях между видеокартой и CPU и кэшироваться в ОЗУ и на дисковых носителях. Это будет влиять на скорость обработки, но как видно из скрина, на сервере с видеокартой 4090 c 24 Гб видеопамяти и 64 Гб ОЗУ запускалась даже модель Reflection 70b, хотя и очень медленно (порядка 4–5 символов в секунду), а та же Command R 32b работала быстро. На локальных машинах с 8 Гб видеопамяти также будет нормально работать gemma2 9B, которая не поменяется полностью.
Совет 3. Можно удалять и обновлять модели прямо из Open WebUI
Модели Ollama обновляются и исправляются с достаточной регулярностью, поэтому рекомендуется время от времени загружать их новые версии. Также модель зачастую остается с тем же именем, но с улучшенным содержанием.
Для обновления всех моделей, загруженных в Ollama, необходимо зайти в Settings — Admin Settings — Models, нажав на имя пользователя в левом нижнем углу и перейдя по менюшкам. Далее вы можете или обновить все модели, нажав на кнопку в разделе Manage Ollama Models, или удалить нужную модель, выбрав ее из выпадающего меню пункта Delete a model и нажав на значок мусорного бака.

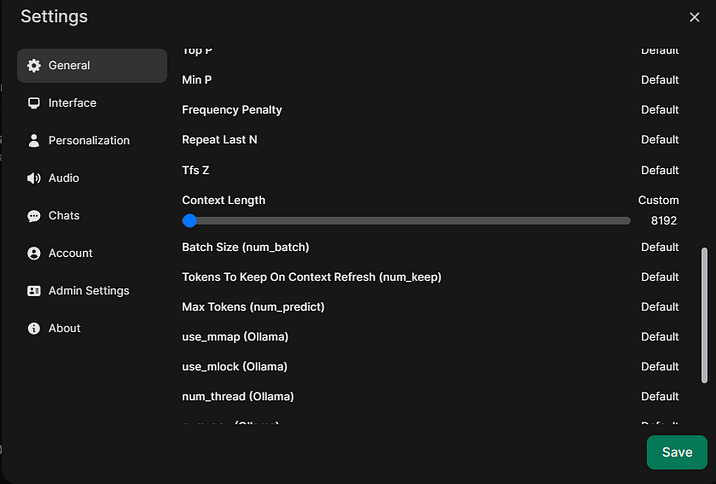
Совет 4. В Open WebUI можно увеличить контекст моделей как глобально, так и для текущего чата
По умолчанию Open WebUI запрашивает модели Ollama с размером контекста 2048 символов. Из-за этого модель быстро «забывает» текущую дискуссию, и с ней сложно работать. То же касается «Температуры» и других параметров, влияющих на отклик.
Если вы хотите увеличить размер контекста или температуру только для текущего чата, нажмите на значок настроек рядом с кружком аккаунта в правом верхнем углу и задайте нужные значения. Помните, что, увеличивая контекст, вы увеличиваете размер передаваемых данных в модель и уменьшаете скорость ее работы.
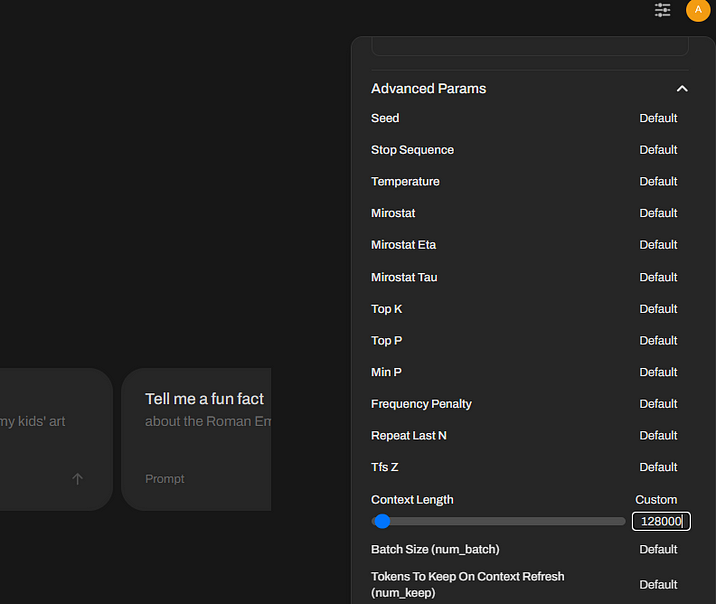
Если же вы хотите изменить глобальные параметры, то, нажав на имя пользователя в левом нижнем углу, выберите меню Settings-General, а в нем раскройте подменю Advanced Parameters, нажав на Show рядом с надписью, и поменяйте нужные значения.
Совет 5. В Open WebUI можно попросить модель использовать для ответа информацию из интернета
Спрашивая что-то у модели, вы можете как указать ей конкретный сайт, так и попросить провести поиск интернете через ту или иную поисковую систему.
В первом случае при запросе укажите URL нужного сайта в чате через #, нажмите Enter и дождитесь, пока страница подгрузится, а затем напишите запрос.

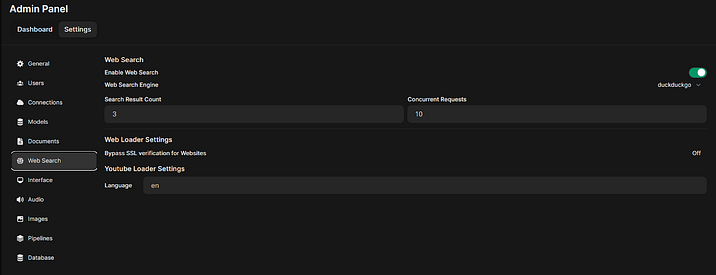
Во втором случае задайте провайдера веб-поиска и его параметры в меню Settings — Admin Settings — Web Search (рекомендуем поставить бесплатный duckduckgo или получить API-ключ для поиска Google). И не забывайте сохранять настройки, нажимая на кнопку Save в нижнем правом углу)
Затем в чате перед запросом включите переключатель Web Search. Поиск будет работать в течение всей сессии общения в этом чате.

Единственный минус — поиск в интернете занимает определенное время и зависит от embeding-модели. Если она задана неверно, вы получите ответ No search results found. Если такое произошло, вам поможет следующий совет.
Совет 6. Поиск по документам и сайтам в Open WebUI можно улучшить
По дефолту в Open WebUI используется библиотека SentenceTransformers и ее модели. Но даже их нужно активировать, зайдя в Settings — Admin Settings — Documents и нажав на кнопку скачивания рядом с названием модели пункта Embedding Models.

Лучше поставить Embedding модель сразу в Ollama, что значительно повысит качество поиска по документам и в Сети, а также формирование RAG. Как это сделать, написано в секрете № 1, а мы рекомендуем поставить модель paraphrase-multilingual (https://ollama.com/library/paraphrase-multilingual). После ее установки в Ollama смените в указанном выше разделе параметр Embedding Model Engine на Ollama, а Embedding Models — на paraphrase-multilingual:latest. Опять же не забудьте сохранить настройки, нажав на зеленую кнопку Save.

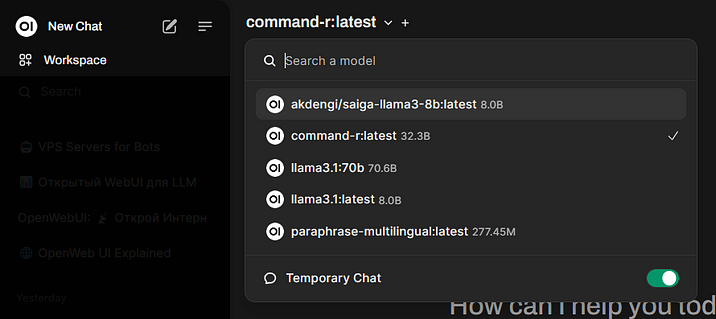
Совет 7. В Open WebUI можно быстро включить временные чаты, которые не сохраняются
Open WebUI сохраняет все чаты пользователя, позволяя вернуться к ним позднее. Но это не всегда нужно, и часто (при переводах или других задачах) сохранение будет даже мешать, засоряя интерфейс. Решением этого является включение режима временных чатов. Для этого раскройте меню моделей сверху и переведите переключатель Temporary Chat в положение «Включено». Вернуть обратно режим сохранения чатов можно, выключив Temporary Chat.
Совет 8. Можно установить Open WebUI на Windows без Docker
Ранее работа с Open WebUI под Windows была затруднена, так как панель распространялась в виде Docker-контейнера или в виде исходников. Но теперь вы можете поставить ее в Windows (предварительно установив Ollama) через pip.
Все что вам нужно, — Python 3.11 (именно 3.11) и запуск в командной строке Windows:
pip install open-webui
После установки нужно запустить Ollama, затем в командной строке прописать:
open-webui serve
И открыть веб-интерфейс в браузере, набрав https://127.0.0.1:8080.
Если при запуске Open WebUI у вас будет вылезать ошибка
OSError: [WinError 126] Не найден указанный модуль. Error loading "C:\Users\username\AppData\Local\Programs\Python\Python311\Lib\site-packages\torch\lib\fbgem.dll" or one of its Dependencies,
скачайте и скопируйте в /windows/system32 библиотеку libomp140.x86_64.dll отсюда: https://www.dllme.com/dll/files/libomp140_x86_64/00637fe34a6043031c9ae4c6cf0a891d/download.
Единственный минус такого решения в том, что Open WebUI может начать конфликтовать с приложениями, требующими другую версию Python (в нашем случае «сломался» клон WebUI-Forge).
Совет 9. В Open WebUI можно генерировать графику
Для этого потребуется будет установить себе (или на сервер) веб-интерфейс Automatic1111 (сейчас он называется Stable Diffusion web UI) и модели (см. Инструкцию https://hostkey.ru/documentation/technical/gpu/stablediffusionwebui/) и настроить работу с Open WebUI.
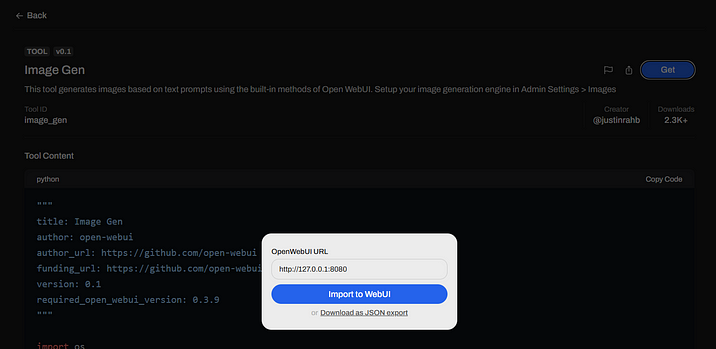
Для удобства можно добавить кнопку генерации через внешний инструментарий (Tools) непосредственно в чате, отправляемом пользователем, а не используя repeat и генерацию в ответе. Для этого зайдите и зарегистрируйтесь на сайте https://openwebui.com, затем перейдите в инструмент Image Gen (https://openwebui.com/t/justinrahb/image_gen/) и, нажав на кнопку Get, введите URL вашего установленного Open WebUI, а затем импортируйте инструмент нажав на Import to WebUI. После этого код будет добавлен в Workspace-Tools и вам останется только нажать на Save в правом нижнем углу.
Если вы правильно настроили доступ к генерации картинок через API, то в чате можно, нажав на плюс, включить переключатель Image Gen и отправить запрос прямо в Stable Diffusion. Старый способ генерации через Repeat при этом продолжит работать.
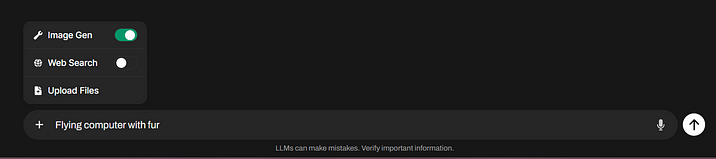
Совет 10. В Open WebUI можно распознавать изображения
Open WebUI позволяет работать с vision-моделями, которые могут распознавать изображения на картинках. Для этого выберите и установите такую модель, как написано в советах ранее (например llava-llama3 https://ollama.com/library/llava-llama3). Далее, нажав на плюс в строке чата и выбрав Upload Files, вы можете загрузить картинку и попросить модель ее распознать. После этого результат можно будет «скормить» другой модели.
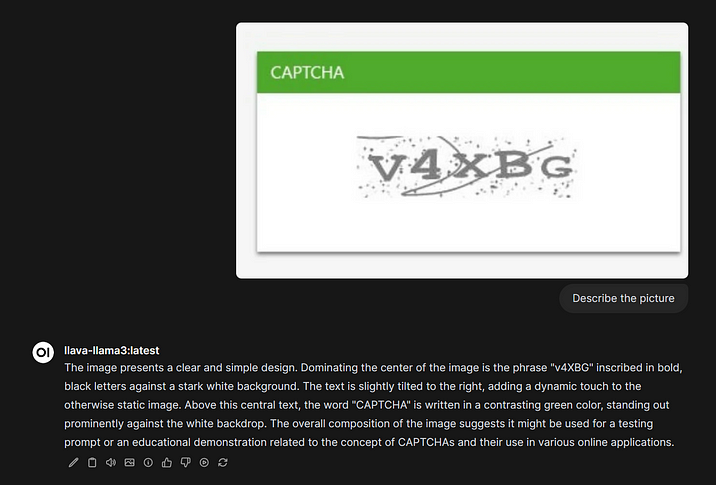
На деле это только вершина айсберга: функционал Open WebUI гораздо шире: от создания кастомных моделей и чат-ботов и доступа к ним по API до автоматизации работы с LLM через инструменты и функции (Tools и Function), позволяющие фильтровать запросы пользователей и отсекать нежелательный контент, создавать конвейеры обработки из нескольких последовательных моделей, очищать выводимый код от мусора или даже играть в Doom! Если вам интересно узнать об этом, напишите в комментариях.
Попробуйте AI-чат-бот на собственном GPU-сервере.
HOSTKEY предлагает персональный AI-чат-бот на основе Ollama и OpenWebUI с предустановленной моделью Llama3.1 8b, который доступен на вашем собственном сервере! Это инновационное решение разработано для тех, кто ценит безопасность данных, масштабируемость и экономию средств.
Основные преимущества
- Безопасность и конфиденциальность данных. Все данные обрабатываются на вашем сервере, что исключает доступ третьих лиц к конфиденциальным данным.
- Экономия средств. Оплачивайте только аренду сервера — использование нейросети бесплатно, стоимость не зависит от количества пользователей.
- Масштабируемость. Легко переносите чат-бот между серверами, увеличивайте или уменьшайте вычислительные мощности и контролируйте расходы.
- Гибкая настройка. Подключайте и настраивайте различные LLM-модели, в том числе Phi3, Mistral, Gemma и Code Llama.