

Несмотря на огромный дефицит, нам удалось достать несколько карт NVIDIA GeForce RTX 5090 и протестировать одну из них. Не все так однозначно, как обещал глава Nvidia, но результаты интересные и внушают оптимизм для применения GPU для ИИ задач.
Оборудование
С оборудованием всё достаточно просто: мы взяли сервер с 4090, вынули эту видеокарту и поставили взамен 5090. Получили вот такую конфигурацию: Intel i9-14900k, 128 Гб, 2 TB NVMe SSD и, конечно же, GeForce RTX 5090 32 Гб.

Если вам интересно «а что с плавящимися разъемами питания», то и здесь пока что всё ОК — в процессе работы разъем не нагревался выше 65 градусов Цельсия. Система охлаждения родная воздушная, по температурному режиму можете посмотреть вывод в следующей главе.

По энергопотреблению карта «поджирает» побольше, чем GeForce RTX 4090. Весь сервер потребляет 830 Вт, и ему нужен соответствующий блок питания. У нас он был установлен с запасом, поэтому замена не понадобилась.
AI-платформа: GPU-серверы с предустановленным ПО для ИИ и LLM модели
Арендуйте GPU-сервер с профессиональными и игровыми графическими картами NVIDIA для вашего ИИ проекта. Предустановленное программное обеспечение готово к работе сразу после деплоя сервера.
Софт
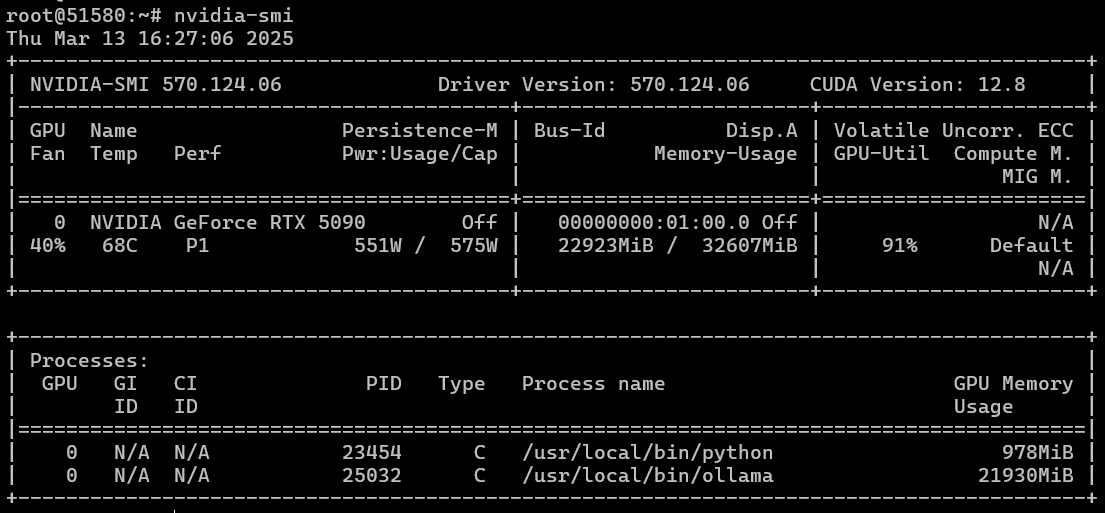
Запускать и тестировать всё будем на Ubuntu 22.04. Ставим систему, затем устанавливаем драйвера и CUDA нашим магическим скриптом. Nvidia-smi показывает, что всё работает и наш «GPU-монстр» потребляет как блок питания компьютера целиком у некоторых дома. На скрине температура и потребление энергии уже под нагрузкой, где сам процессор загружен всего на 40%.
Далее добавляем пакет docker, проброс nvidia в контейнеры и ставим Ollama (просто в систему) и OpenWebUI как docker-контейнер. Запускаем, убеждаемся, что всё работает, и начинаем тестирование.
Тесты
Для начала мы решили провести тесты по скорости работы нейросетей. Для удобства используем OpenWebUI в связке с Ollama. Забегая вперед, скажем, что напрямую работа с Ollama будет и быстрей, и требовать чуть меньше ресурсов, но получить данные, увы, можно только при работе через API, а наша задача — понять, быстрее ли 5090 предыдущего поколения в лице 4090, и если быстрее, то насколько.
В качестве соперника у нас была RTX 4090 на этой же конфигурации. Все тесты проводились с уже предзагруженными моделями, и значение вычислялось как усредненное после десяти запусков.
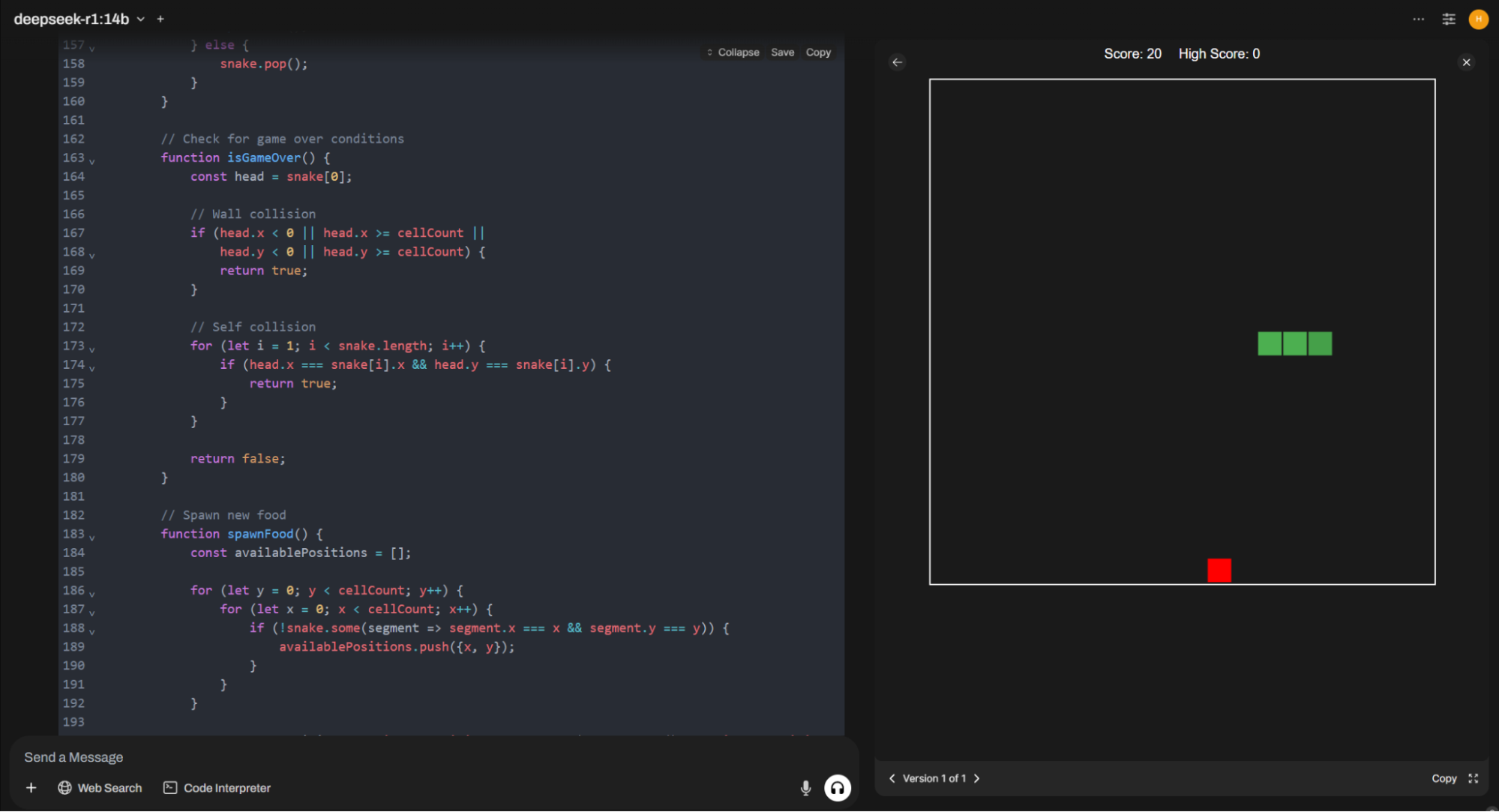
Первой на тест пойдет DeepSeek R1 14B в q4 при установленном размере контекста 32768. Размышления у модели идут отдельными потоками и отнимают определенное число ресурсов, а эта модель все еще остается популярной для бытовых видеокарт с размером видеопамяти до 16 Гб. Плюс тут гарантированно не будет влияния скорости диска, памяти и процессора, так как все вычисления будут проводиться в видеопамяти.
Модель требует для работы 11 Гб видеопамяти.

Промт мы используем следующий: «Write code for simple Snake game on HTML and JS». На выходе получаем плюс-минус 2K токенов.
| RTX 5090 32 Гб | RTX 4090 24 Гб | |
| Скорость отклика, токенов в секунду | 104,5 | 65,8 |
| Время отклика, секунд | 20 | 40 |
Как видно, 5090 показывает себя до 40% быстрее. И это при условии, что под архитектуру Blackwell еще нет оптимизации многих популярных фреймворков и библиотек, хотя новая CUDA 12.8 вовсю уже использует преимущества архитектуры.
Далее тест на переводы. Мы рассказывали ранее, что используем нейросетевых агентов-переводчиков для работы над документацией, поэтому охота было посмотреть, ускорится ли наша работа при применении 5090.
Берем системный промт для перевода с английского на турецкий:
You are native translator from English to Turkish.
I will provide you with text in Markdown format for translation. The text is related to IT.
Follow these instructions:
- Do not change Markdown format.
- Translate text, considering the specific terminology and features.
- Do not provide a description of how and why you made such a translation.
- Keep on English box, panels, menu and submenu names, buttons names and other UX elements in tags '** **' and '\~\~** **\~\~'.
- Use the following Markdown constructs: '!!! warning "Dikkat"', '!!! info "Bilgi"', '!!! note "Not"', '??? example'. Translate 'Password" as 'Şifre'.
- Translate '## Deployment Features' as '## Çalıştırma Özellikleri'.
- Translate 'Documentation and FAQs' as 'Dokümantasyon ve SSS'.
- Translate 'To install this software using the API, follow [these instructions](../../apidocs/index.md#instant-server-ordering-algorithm-with-eqorder_instance).' as 'Bu yazılımı API kullanarak kurmak için [bu talimatları](https://hostkey.com/documentation/apidocs/#instant-server-ordering-algorithm-with-eqorder_instance) izleyin.'И отправляем в ответ содержимое вот этой страницы документации (предварительно переведя ее на английский, так как перевод с русского на турецкий напрямую идет хуже).
| RTX 5090 32 Гб | RTX 4090 24 Гб | |
| Скорость отклика, токенов в секунду. Чем больше, тем лучше. | 88 | 55 |
| Время отклика, секунд. Чем меньше, тем лучше | 60 | 100 |
На выходе имеем в среднем 5K токенов при общем числе в 10K (напоминаю, что у нас окно контекста 32K установлено). Как видно и здесь, 5090 быстрее, хотя уже в пределах обещанных 30% прироста.
Далее переходим к модели «пожирнее». Берем новинку — Gemma3 27B. Для нее ставим размер контекста входного в 16384 токена. И получаем, что на 5090 модель потребляет 26 Гб видеопамяти.

На этот раз попробуем нарисовать логотип для компании по аренде серверов (вдруг захотим наш старый логотип HOSTKEY поменять). Промт будет следующий: «Design an ONE complex SVG logo for a server rental company».
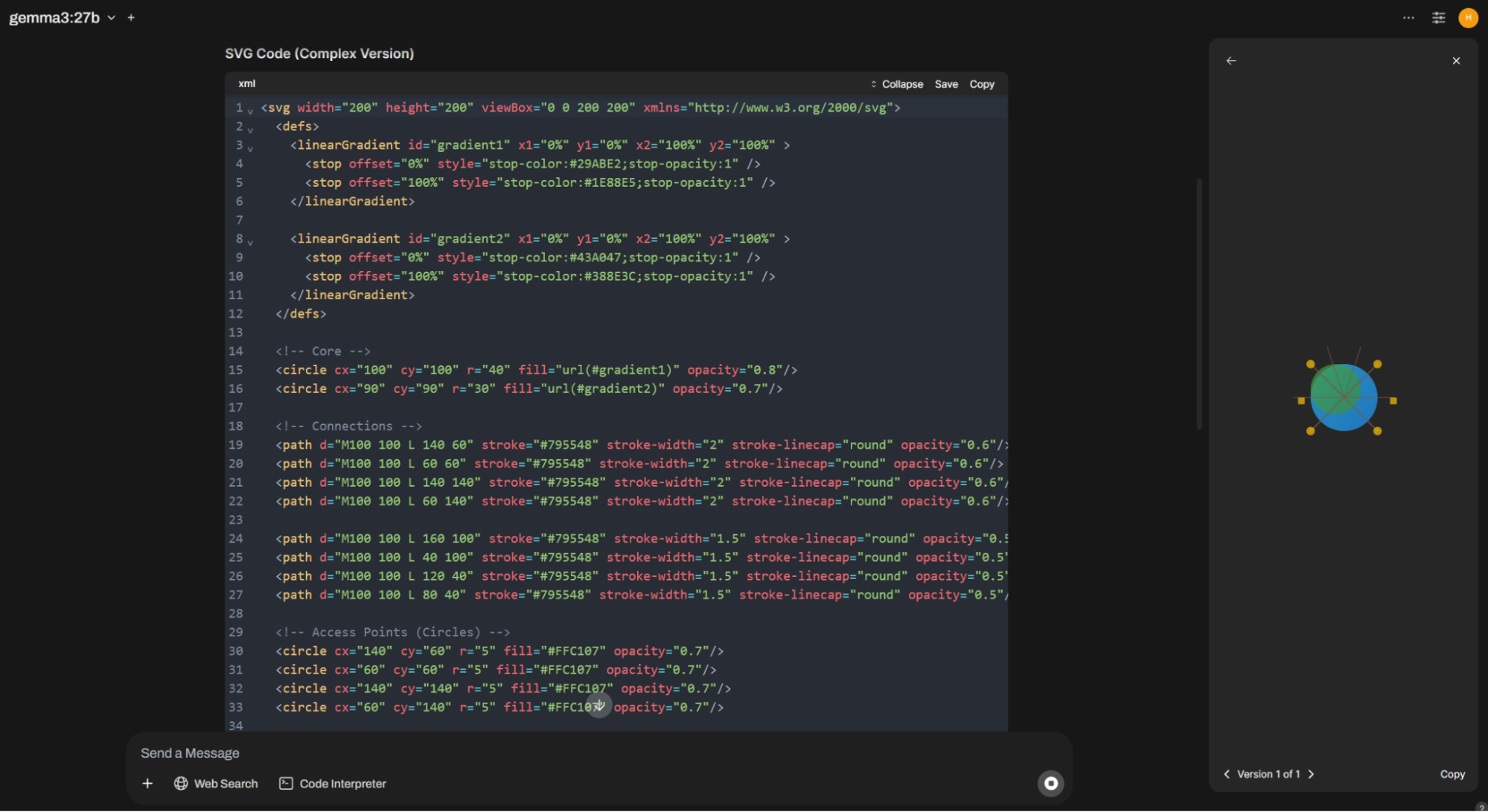
А результат такой:
| RTX 5090 32 Гб | RTX 4090 24 Гб | |
| Скорость отклика, токенов в секунду. Чем больше, тем лучше. | 48 | 7 |
| Время отклика, секунд. Чем меньше, тем лучше | 44 | 270 |
Оглушительный провал RTX 4090. Смотрим, как у нас распределяется нагрузка на GPU, и видим, что у нас 17% ушло на центральный процессор и ОЗУ, а значит, скорость гарантированно упала. Причем общий объем потребляемых ресурсов из-за этого тоже вырос. 32 Гб памяти на борту RTX 5090 для моделей такого толка очень помогают.

Gemma3 у нас мультимодальная модель, значит, может распознавать изображения. Берем картинку и просим ее найти всех животных на ней: «Find all animals on this picture». Размер контекста также оставляем в 16K.
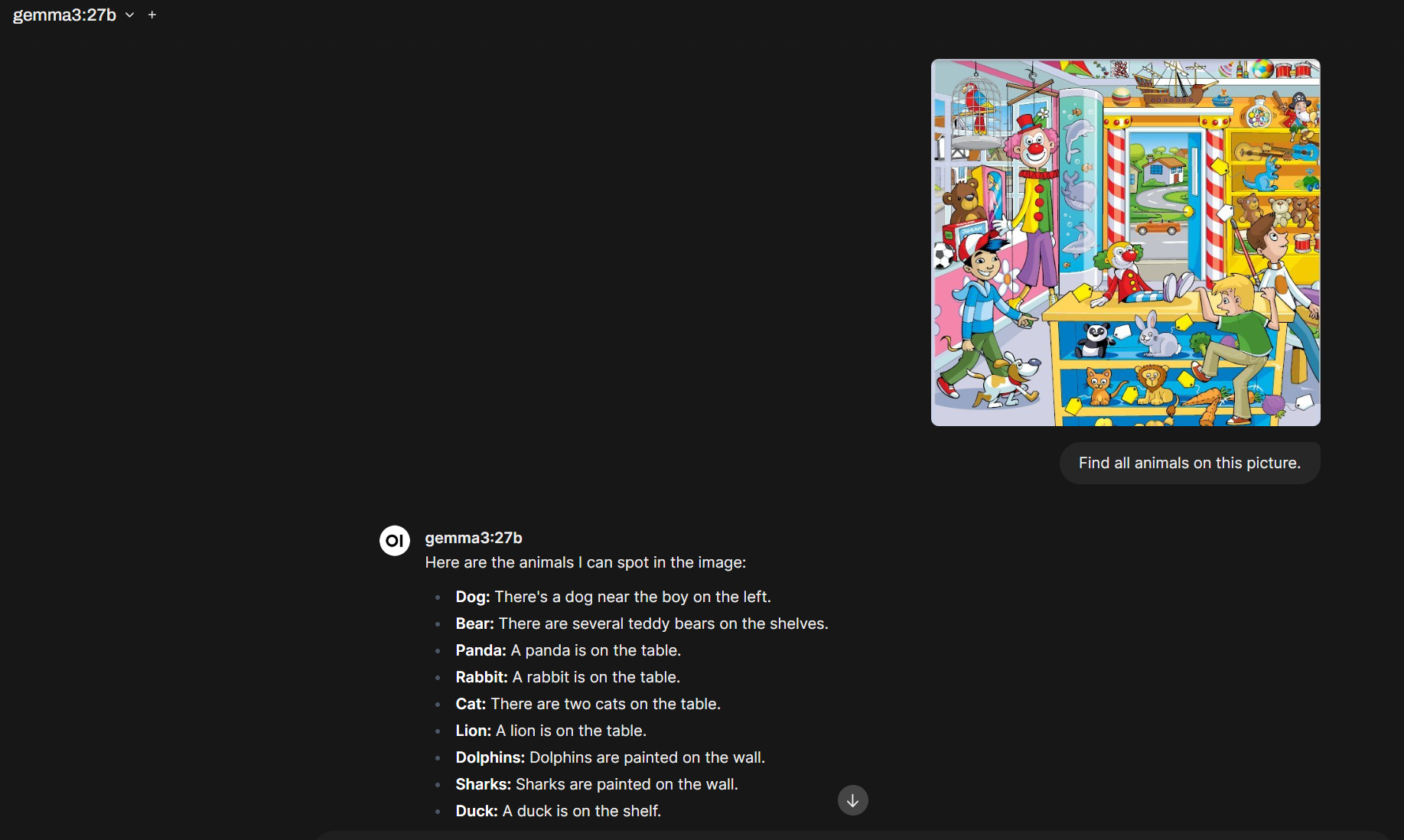
C 4090 оказалось не всё так просто. При таком размере исходящего контекста модель зависала. Уменьшение до 8K привело к уменьшению потребления видеопамяти, но похоже, что обработка изображений на CPU даже на 5% — не самая лучшая идея.

В итоге все результаты для 4090 были получены для контекста в 2K, что дало фору этой видеокарте, так как Gemma3 утилизировала только 20 Гб видеопамяти.

Для сравнения в скобках цифры, которые были получены для 5090 с контекстом в 2K.
| RTX 5090 32 Гб | RTX 4090 24 Гб | |
| Скорость отклика, токенов в секунду. Чем больше, тем лучше. | 49 (78) | 39 |
| Время отклика, секунд. Чем меньше, тем лучше | 10 (4) | 6 |
Следующей на тест снова выходит «убийца ChatGPT» в лице DeepSeek, но уже с 32 миллиардами параметров. Модель занимает в видеопамяти 25 Гб у 5090 и 26 Гб с частичным задействованием CPU у 4090.


Тестировать мы будем, попросив нейросеть написать нам Тетрис для браузера. Контекст ставим в 2K, памятуя о проблемах предыдущих тестов. Задаем максимально неинформативный промт «Write Tetris on HTML» и ждем результат. Пару раз даже получаем играбельную вещь.
| RTX 5090 32 Гб | RTX 4090 24 Гб | |
| Скорость отклика, токенов в секунду. Чем больше, тем лучше. | 57 | 17 |
| Время отклика, секунд. Чем меньше, тем лучше. | 45 | 180 |
О грустном
Первые нехорошие звоночки прозвучали, когда мы решили сравнить видеокарты при работе с векторными базами данных: созданием эмбедингов и поиском результата с их учетом. У нас не получилось создать новую базу знаний. Потом не заработал поиск по интернету в OpenWebUI.
Далее мы решили посмотреть скорость в генерации графики, поставив ComfyUI с моделью Stable Diffusion 3.5 Medium. И при запуске генерации получил вот такое сообщение:
CUDA error: no kernel image is available for execution on the deviceЛадно, подумали мы, возможно, у нас старые версии CUDA (нет), или драйверов (нет), или PyTorch. Обновил последний до nightly версии, запустил и получил такое же сообщение.
Полезли рыться, что пишут другие пользователи и есть ли решение, и оказалось, что проблема в отсутствии сборки PyTorch под архитектуру Blackwell и CUDA 12.8. И решения, кроме как самому всё пересобрать с нужными ключами и из исходников, нет.
Судя по стенаниям, такая же проблема существует и с другими библиотеками, которые «плотно» взаимодействуют с CUDA. Остается только ждать.
Итоги
Какие выводы: Дженсен Хуанг не обманул, и в ИИ-применении 5090 работает быстрее и часто сильно быстрее предыдущего поколения. Возросший объем памяти позволяет запускать 27/32B модели даже с максимальным размером контекста. Но, как говорится, есть «но» в 32 гигабайта видеопамяти — это мало. Да, видеокарта игровая, и ждем профессиональные версии с 64 и более гигабайтами видеопамяти на замену A6000-серии (только что анонсировали RTX PRO 6000 с 96 Гб с видеопамяти).
По нашему мнению, тут NVIDIA пожадничала и в топовую модель без сильного ущерба стоимости могла бы и поставить 48 Гб (или выпустить 4090 Ti для энтузиастов). Про то, что софт не адаптирован толком: NVIDIA опять же показала, что часто «забивает» на работу с сообществом, так как неработающие на старте PyTorch или TensorFlow (там такие же проблемы из-за новой версии CUDA) — это позор. Но сообщество на то и сообщество, чтобы решать и достаточно быстро такие проблемы, и уже через пару-тройку недель ситуация с поддержкой ПО, думаем, наладится.