

Связку из Ollama и OpenWebUI я использую больше года, и она является моим рабочим инструментом в части работы с документацией и контентом и по-настоящему ускорила работу по локализации документации HOSTKEY на другие языки. Но жажда исследований не отпускает, и с появлением относительно вменяемой документации к API у OpenWebUI возникло желание написать что-то, автоматизирующее работу. Например, перевод документации из командной строки.
Идея
В HOSTKEY клиентская документация собирается в Material for MkDocs и в исходниках, хранящихся в GIT, представляет собой набор файлов в Markdown формате. А раз мы имеем текстовые файлы, то кто мешает мне не копировать их текст из VS Code и вставлять в чат OpenWebUI в браузере, а запускать скрипт из командной строки, который бы отправлял файл со статьей нейросетевой модели, получал перевод и записывал его назад в файл.
В теории в дальнейшем так можно было бы сделать масс-обработку файлов и запускать автоматизированный черновой перевод на новые языки всех массивов или при создании статьи на одном языке одной командой переводить и клонировать их на множество других. С учетом роста числа переводов (сейчас это русский, английский, турецкий, в работе французский, а в планах испанский и китайский) всё это ускорило бы работу отдела документации. Поэтому разрабатываем план:
- Берем исходный файл .md файл;
- Скармливаем его нейросетевой модели;
- Получаем перевод;
- Записываем файл с переводом;
Приложениями для ИИ, машинного обучения и науки о данных на GPU-серверах с картами NVIDIA
Арендуйте высокопроизводительный сервер с GPU картой с предустановленными лучшими LLM-моделями:
AI & Машинное обучение
Наука о данных
Изучаем API
Первый возникающий вопрос: а зачем на OpenWebUI, когда можно сразу «скормить» файл Ollama? Да, это можно сделать, но, забегая вперед, скажу, что использование «прокладки» в виде OpenWebUI было правильным решением. Причем API Ollama еще хуже документировано, чем OpenWebUI.
Описание API OpenWebUI доступно в swagger формате по адресу https://<IP или домен инстанса>/docs/. Из него видно, что вы можете управлять как Ollama, так и самим OpenWebUI и обращаться к нейросетевым моделям в синтаксисе API от OpenAI.
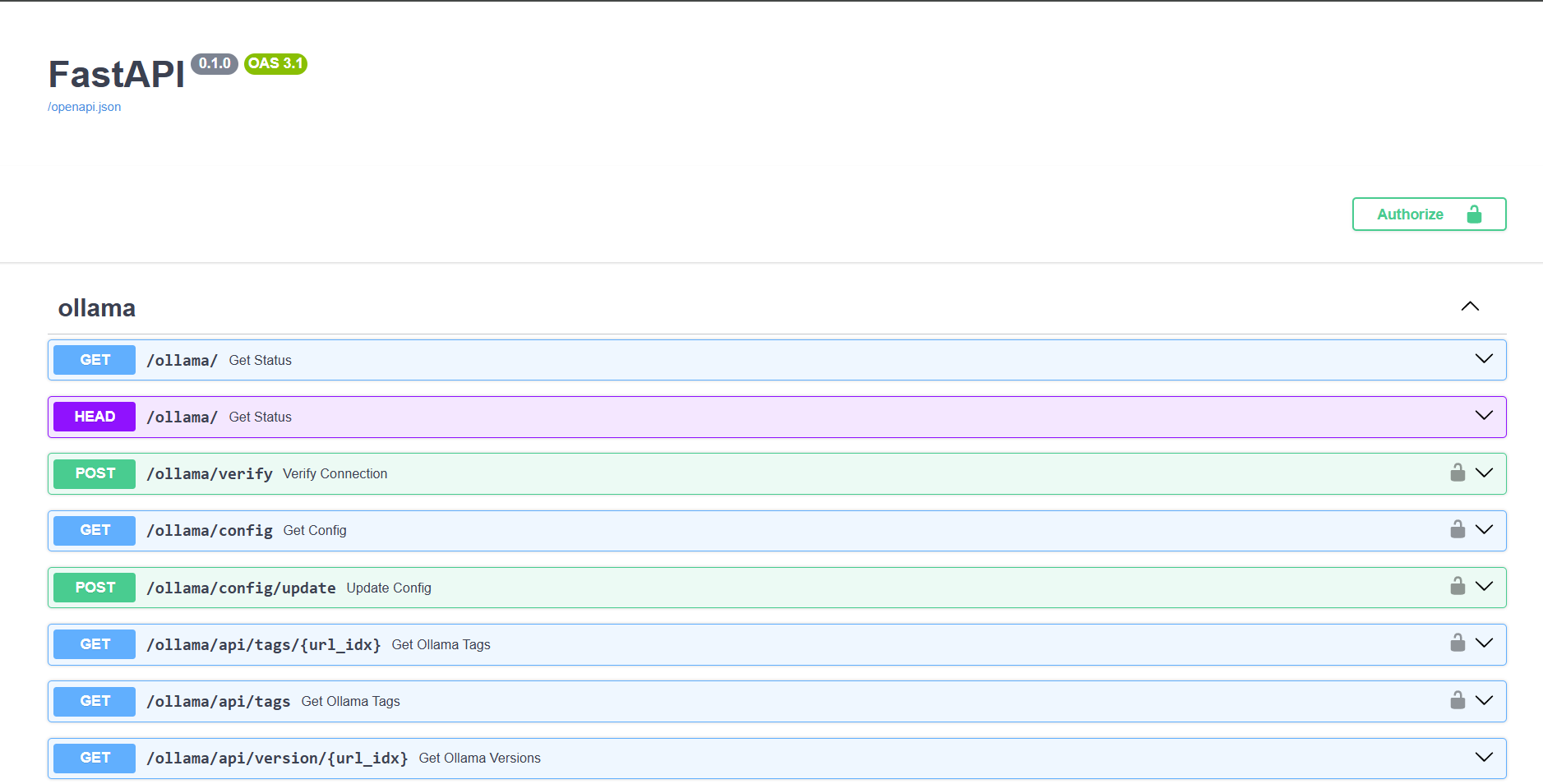
Последнее спасло меня, так как понять, какие параметры и как передавать, было не очень понятно, и пришлось обратиться к документации по API от OpenAI.
Что в итоге? Нам нужно начать чат и передать в модель системный промт, в котором объяснить ей, что делать, а затем текст для перевода, а также параметры, такие как температуру и размер контекста (max_tokens).
В синтаксисе API от OpenAI нам надо сделать POST запрос к OpenWebUI на <адрес OpenWebUI>/ollama/v1/chat/completions, содержащий следующие поля:
Authorization: Bearer <API ключ доступа к OpenWebUI>
Content-Type: application/json
data body:
'{
model: <нужная нам модель>,
messages: [
{
role: "system",
content: <системный промт>
},
{
role: "user",
content: <наш файл для перевода>
}
],
temperature: 0.6
max_tokens: 16384
}'Как видно, тело запроса нужно передавать в JSON-формате, и в нем же мы получим ответ.
Писать я решил всё в виде bash-скрипта (для меня универсальное решение, так как можно запускать скрипт и на удаленном Linux-сервере, и локально даже из Windows через WSL), поэтому будем использовать cURL в Ubuntu 22.04. Для работы с JSON-форматом ставлю утилиту jq.
Далее создаю в OpenWebUI пользователя для нашего переводчика, получаю для него API-ключ, устанавливаю несколько нейросетевых моделей для теста и... у меня ничего не получается.
Версия 1.0
Как я писал ранее, нам необходимо сформировать data-часть запроса в JSON-формате. Основной код скрипта, который принимает параметр в виде имени файла для перевода и отправляет запрос, а затем расшифровывает ответ, следующий:
local file=$1
# Read the content of the .md file
content=$(<"$file")
# Prepare JSON data for the request, including your specified prompt
request_json=$(jq -n \
--arg model "gemma2:latest" \
--arg system_content "Operate as native translator from US-EN to TR. I will provide you text in Markdown format for translate. The text is related to IT.\nFollow this instructions:\n\n- Do not change Markdown format.\n- Translate text, considering the specific terminology and features.\n- Do not provide a description of how and why you made such a translation.\
'{
model: $model,
messages: [
{
role: "system",
content: $system_content
},
{
role: "user",
content: $content
}
],
temperature: 0.6,
max_tokens: 16384
}')
# Send POST request to the API
response=$(curl -s -X POST "$API_URL" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
--data "$request_json")
# Extract translated content from the response (assuming it's in 'choices[0].message.content')
translated_content=$(echo "$response" | jq -r '.choices[0].message.content')Как видно, я использовал модель gemma2 на 9B, системный промт для перевода с английского на турецкий язык и просто передал в запросе содержимое файла в Markdown формате. API_URL указывает на http://<IP адреc OpenWebUI:Порт>/ollama/v1/chat/completion.
Тут и была моя первая ошибка — необходимо было подготовить текст для JSON формата. Для этого в скрипте нужно было поправить его начало:
# Read the content of the .md file
content=$(<"$file")
# Escape special characters in the content for JSON
content_cleaned=$(echo "$content" | sed -e 's/\r/\r\\n/g' -e 's/\n/\n\\n/g' -e 's/\t/\\t/g' -e 's/"/\\"/g' -e 's/\\/\\\\/g')
# Properly escape the content for JSON
escaped_content=$(jq -Rs . <<< "$content_cleaned")Экранировав специальные символы и переведя .md файл в JSON, а в теле формирования запроса добавить новый аргумент.
--arg user_content "$escaped_content" \Который и передавать в роли "user".
Дооформляем скрипт и пытаемся улучшить промт.
Промт для перевода
Изначальный промт для переводчика у меня был такой, как в примере. Да, он достаточно неплохо переводил технический текст с турецкого на английский, но были свои проблемы.
Мне необходимо было единообразие перевода определенных конструкций Markdown-разметки, таких как заметки, примечания и т. п. Также хотелось, чтобы переводчик не переводил на турецкий UX-элементы как системы управления серверами Invapi (он у нас пока что на английском и русском), так и интерфейсов ПО, потому что с большим числом языков поддержка локализованных версий превращалась в мини-ад. Сложности добавляло еще то, что в документации используется нестандартные конструкции для кнопок в виде жирного зачеркнутого текста КНОПКА (конструкция ~~** **~~). Поэтому в OpenWebUI был отлажен системный промт следующего вида:
You are native translator from English to Turkish.
I will provide you text in Markdown format for translate. The text is related to IT.
Follow these instructions:
- Do not change Markdown format.
- Translate text, considering the specific terminology and features.
- Do not provide a description of how and why you made such a translation.
- Keep on English box, panels, menu and submenu names, buttons names and other UX elements in tags '** **' and '\~\~** **\~\~'.
- Use the following Markdown constructs: '!!! warning "Dikkat"', '!!! info "Bilgi"', '!!! note "Not"', '??? example'. Translate 'Password" as 'Şifre'.
- Translate '## Deployment Features' as '## Çalıştırma Özellikleri'.
- Translate 'Documentation and FAQs' as 'Dokümantasyon ve SSS'.
- Translate 'To install this software using the API, follow [these instructions](../../apidocs/index.md#instant-server-ordering-algorithm-with-eqorder_instance).' as 'Bu yazılımı API kullanarak kurmak için [bu talimatları](https://hostkey.com/documentation/apidocs/#instant-server-ordering-algorithm-with-eqorder_instance) izleyin.'Теперь этот промт надо было проверить на стабильность на различных моделях, так как нужно было добиться и достаточно качественного перевода, и не пожертвовать скоростью. Gemma2 9B хорошо справляется с переводом, но упорно игнорировала требование не переводить UX-элементы.
Модель DeepSeekR1 в версии 14B также давала большое число ошибок, а местами вообще переключалась на иероглифы. Из всех моделей лучше всего показала себя Phi4-14B. Модели с большим числом параметров было использовать сложнее, так как всё «крутится» на сервере с A5000 с 24 Гб видеопамяти. Единственное, что я взял вместо дефолтной модели Phi4-14B с квантизацией q4 модель в менее сжатом формате (q8).
Результат тестов
Всё заработало. Но с некоторыми оговорками. Основная проблема была в том, что новые запросы почему-то не перезапускали сессию чата, и модель жила в прежнем контексте и через пару-тройку файлов теряла системный промт. В результате, если первые пара запусков давали достаточно вменяемый перевод, то потом модель переставала воспринимать инструкции и вообще оставляла текст на английском. Добавление параметра stream: false ситуацию не спасало.
Вторая проблема — это галлюцинации, но в части игнорирования инструкций «не переводить UX». Я пока что не смог добиться стабильности в данном вопросе, и если в чате OpenWebUI я могу «ткнуть носом» модель в то, что она зачем-то перевела название кнопок и меню, и она с 2–3-го раза выдавала нужное, то тут необходимо было только запускать скрипт заново, и срабатывал он иногда раза с пятого-шестого.
Третья проблема — это тюнинг промта. Если в OpenWebUI я мог создать кастомный промт и через раздел Workspace — Promts задать ему слеш-команду вида /en_tr, то в скрипте нужно было переписывать код, причем в не очень удобном формате. То же касается и параметров модели.
Версия 2.0
Поэтому было решено пойти другим путем. В OpenWebUI можно задать кастомные модели-агенты, в которых прописать как системный промт, так и гибко настроить их параметры (и даже использовать RAG) и права. Поэтому я создал агента-переводчика в разделе Workspace — Models (название модели написано мелко и будет «entrtranslator»).
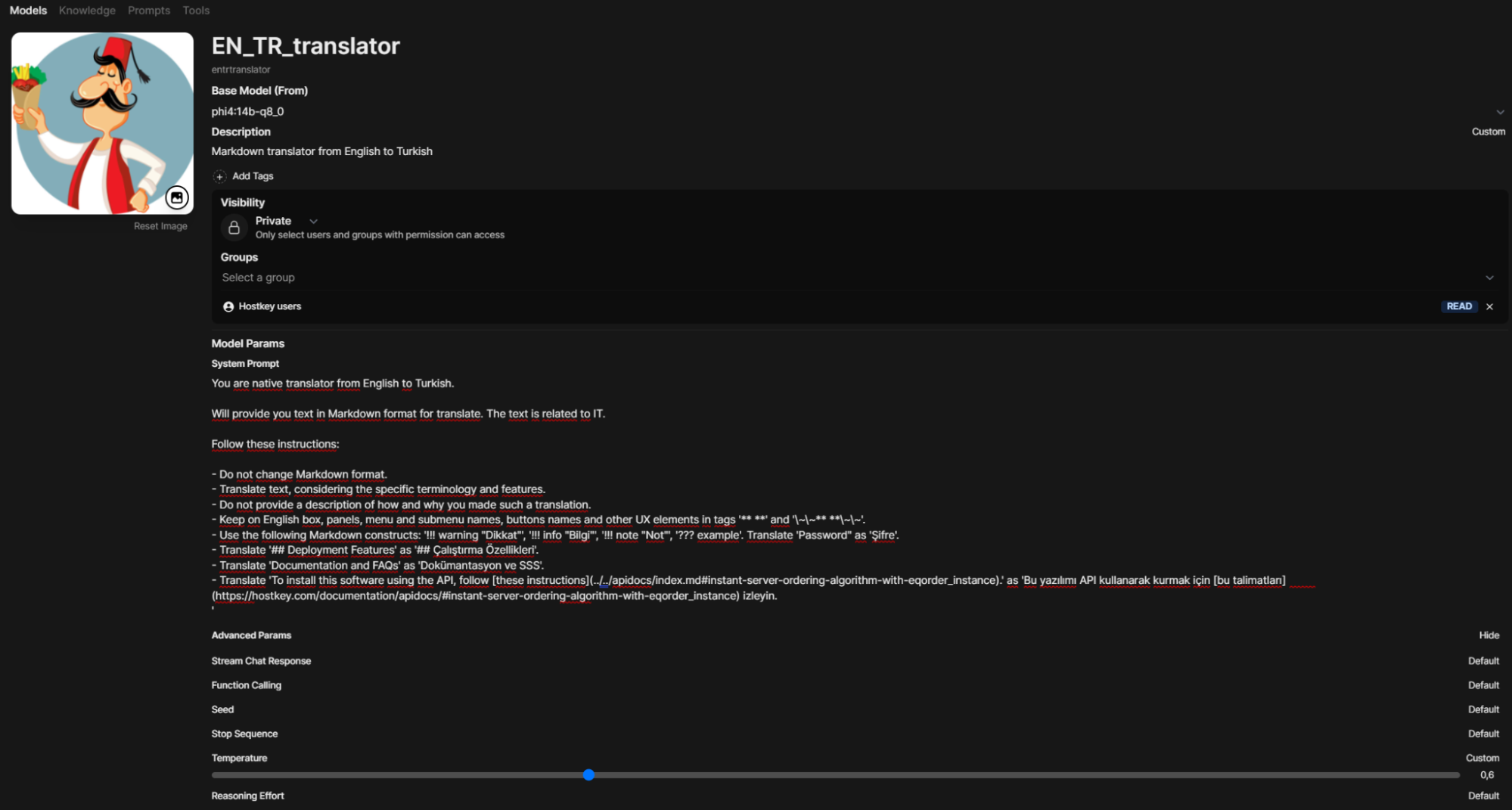
Если попробовать подставить новую модель в текущий скрипт, то он выдаст ошибку. Это происходит потому, что прежний вызов просто передавал параметры в Ollama через OpenWebUI, для которой «модели» entrtranslator просто не существует. Изучение API OpenWebUI методом проб и ошибок привело к другому вызову самого OpenWebUI: /api/chat/completions.
Теперь вызов нашего нейросетевого переводчика можно записать так:
local file=$1
# Read the content of the .md file
content=$(<"$file")
# Escape special characters in the content for JSON
content_cleaned=$(echo "$content" | sed -e 's/\r/\r\\n/g' -e 's/\n/\n\\n/g' -e 's/\t/\\t/g' -e 's/"/\\"/g' -e 's/\\/\\\\/g')
# Properly escape the content for JSON
escaped_content=$(jq -Rs . <<< "$content_cleaned")
# Prepare JSON data for the request, including your specified prompt
request_json=$(jq -n \
--arg model "entrtranslator" \
--arg user_content "$escaped_content" \
'{
model: $model,
messages: [
{
role: "user",
content: $user_content
}
],
temperature: 0.6,
max_tokens: 16384,
stream: false
}')
# Send POST request to the API
response=$(curl -s -X POST "$API_URL" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
--data "$request_json")
# Extract translated content from the response (assuming it's in 'choices[0].message.content')
translated_content=$(echo "$response" | jq -r '.choices[0].message.content')Где API_URL принимает вид http://<IP адреc OpenWebUI:Порт>/api/chat/completions.
Теперь у вас есть возможность гибко настраивать параметры и промт через веб-интерфейс, а также использовать данный скрипт для переводов на другие языки.
Этот способ сработал и позволяет создавать ИИ-агентов для использования в bash-скриптах не только для перевода, но и для других нужд. Процент «непереводов» снизился, и осталась только проблема, когда модель не хочет игнорировать перевод UX-элементов.
Что дальше?
Дальше стоит задача добиться большей стабильности работы, хотя уже даже сейчас можно работать с текстами из интерфейса командной строки, и модель не срабатывает только на больших текстах (больше 16K ставить не позволяет видеопамять, модель начинает тормозить). Это можно сделать как улучшением промта, так и тюнингом параметров модели, которых достаточно много.

Всё это позволит запустить автоматическое создание черновиков переводов на всех поддерживаемых языках, как только будет создан текст на английском языке.
Ну а далее есть идея подключить базу знаний с переводом элементов интерфейсов Invapi и других значений элементов меню на сайте (и ссылок на них), чтобы при переводе не приходилось вручную править ссылки и наименования в статьях. Но работа с RAG в OpenWebUI через API — это тема для отдельной статьи.
P.S. После написания данной статьи была анонсирована модель Gemma3, которая возможно займет место Phi4 в переводчиках, так как она поддерживает 140 языков при контексте до 128K.