

В предыдущей статье мы рассказывали, как тестировали сервер с одной RTX 5090. Теперь же мы решили установить в сервер две видеокарты RTX 5090. И это также вызвало у нас определённые проблемы, но результат того стоил.
Вынули две видеокарты - поставили две видеокарты
Для упрощения и скорости сперва мы решили заменить в сервере, где уже стояли две видеокарты 4090 на 5090. Конфигурация сервера получилась вот такая: Core i9-14900KF 6.0GHz (24 cores)/192Gb/2Tb NVMe SSD/2xRTX 5090 32GB.
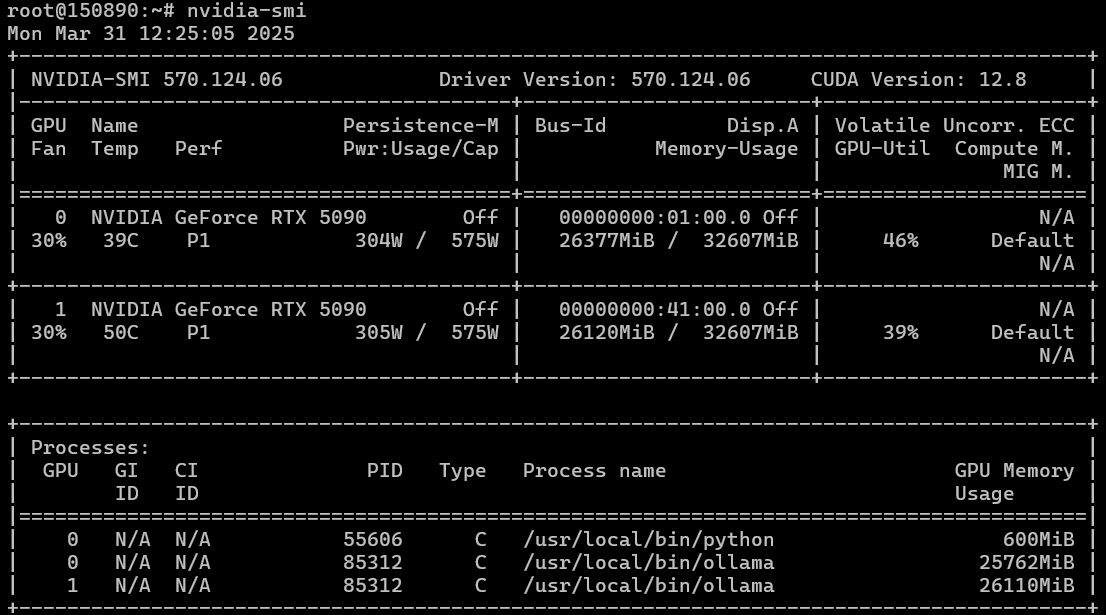
Деплоим Ubuntu 22.04, ставим нашим магическим скриптом драйвера, которые установились без проблем, как и CUDA. nvidia-smi показывает две видеокарты. Блок питания кажется вытягивает до 1,5 киловатт нагрузки.
AI-платформа: GPU-серверы с предустановленным ПО для ИИ и LLM модели
Арендуйте GPU-сервер с профессиональными и игровыми графическими картами NVIDIA для вашего ИИ проекта. Предустановленное программное обеспечение готово к работе сразу после деплоя сервера.
Ставим ollama, качаем модель, запускаем и получаем... получаем, что у нас ollama работает на CPU и не видит видеокарты. Пробуем запускать ollama с непосредственным указанием устройств для CUDA через задание номеров видеокарт для CUDA:
CUDA_VISIBLE_DEVICES=0,1 ollama serveНо также получаем аналогичный результат, когда ollama не хочет инициализироваться на двух видеокартах. Пробуем в режиме одной видеокарты, устанавливая CUDA_VISIBLE_DEVICE=0 и CUDA_VISIBLE_DEVICE=1 — такая же ситуация.
Пробуем поставить Ubuntu 24.04 — вдруг новая CUDA 12.8 не очень хорошо работает в multi-GPU конфигурации на «старенькой» Ubuntu? И да, по отдельности у нас видеокарты заработали.

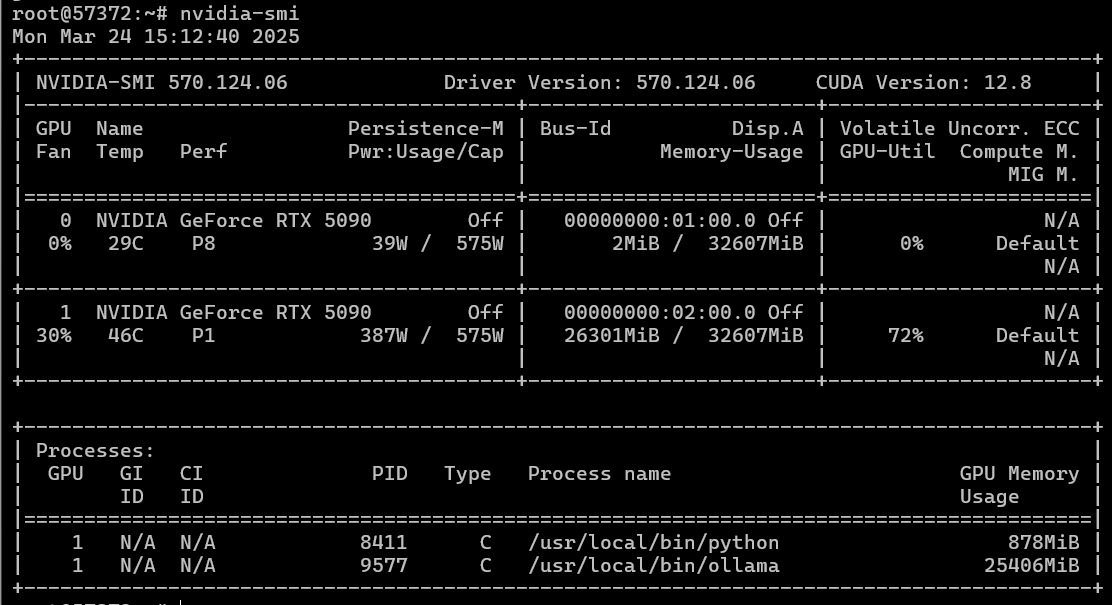
Но при попытке запустить ollama на двух видеокартах получаем опять ошибку инициализации CUDA на них.
Зная, что ollama может испытывать проблемы работы на нескольких GPU, пробуем PyTorch. Помним, что для RTX 50xx серии официального релиза PyTorch ещё нет, ставим совместимую версию (а точнее последнюю ночную сборку, совместимую с CUDA 12.8):
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128import torch
if torch.cuda.is_available():
device_count = torch.cuda.device_count()
print(f"CUDA is available! Device count: {device_count}")
for i in range(min(device_count, 2)): # Limit to 2 GPUs
device = torch.device(f"cuda:{i}")
try:
print(f"Successfully created device: {device}")
x = torch.rand(10,10, device=device)
print(f"Successfully created tensor on device {device}")
except Exception as e:
print(f"Error creating device or tensor: {e}")
else:
print("CUDA is not available.")И получаем ошибку при работе двух карт и работу на каждой из видеокарт, если мы передаём переменную использования CUDA.
Для надежности решаем установить и проверить CuDNN по этой инструкции и используем вот эти тесты: https://github.com/NVIDIA/nccl-tests.
Тестирование также проваливался на двух видеокартах. После этого меняли видеокарты местами, райзеры, проверяли видеокарты по одной — результата ноль.
Новый сервер и наконец-то тесты
Решаем, что дело возможно в железе, которое “не тянет” две 5090. Переносим две видеокарты на другое железо: AMD EPYC 9354 3.25GHz (32 cores)/1152Gb/2Tb NVMe SSD/PSU+2xRTX 5090 32GB. Ставим снова Ubuntu 22.04, обновляем ядро до 6-й версии, обновляем драйвера, CUDA, ollama, запускаем модели и…
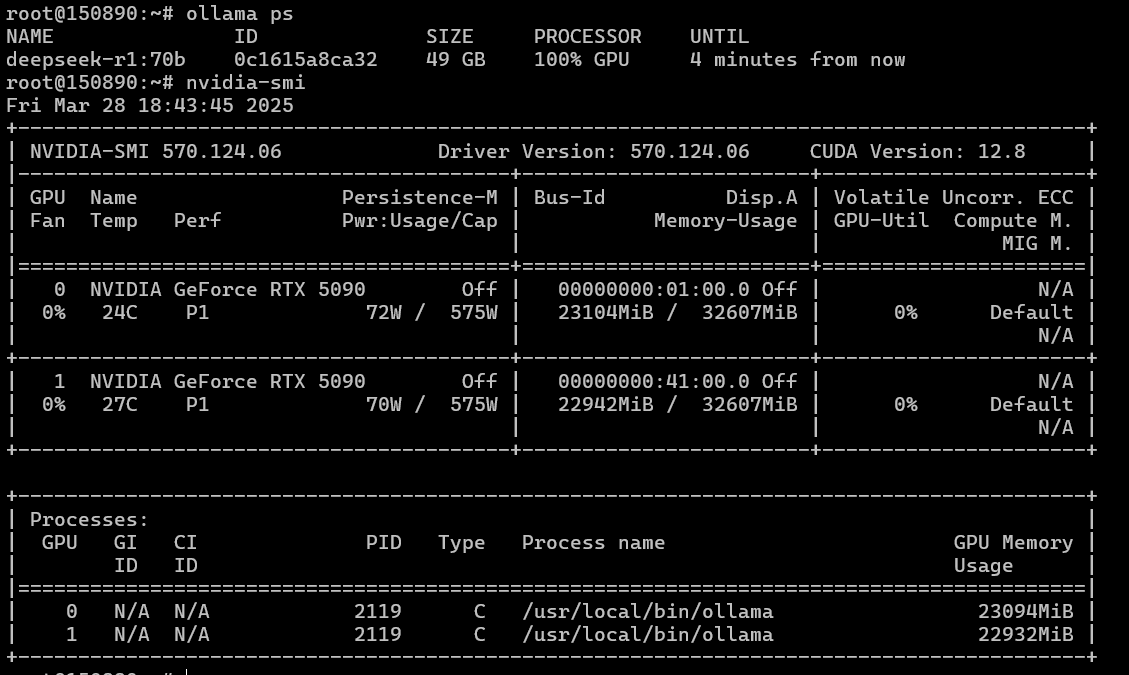
Аллилуйя! — у нас все заработало. Ollama масштабируется на две видеокарты, а значит должны работать и другие фреймворки. Проверяем на всякий случай и nccl и PyTorch.
Тестирование NCCL:
./build/all_reduce_perf -b 8 -e 256M -f 2 -g 2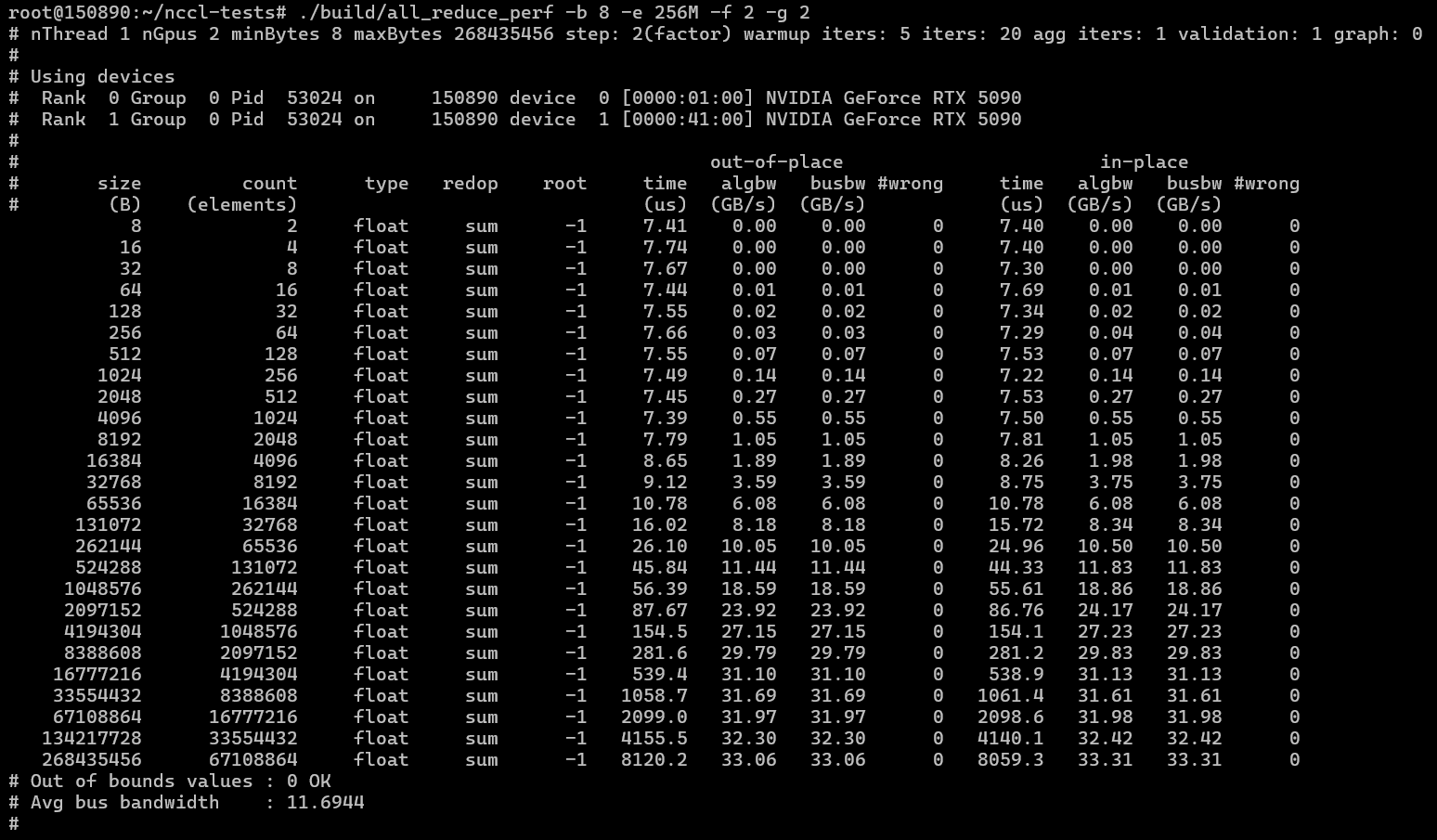
Pytorch с тестом, указанным ранее:
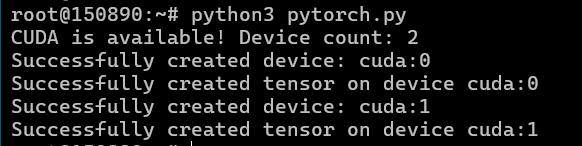
Тестировать нейросетевые модели, чтобы сравнить их с показателями двух видеокарт 4090 будем через связку Ollama и OpenWebUI.
Для работы с 5090 также обновляем pytorch внутри docker контейнера OpenWebUI:
docker exec -it open-webui bash
pip install --upgrade --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128DeepSeek R1 14 B
Размер контекста 32768 токенов. Промт: “Write code for simple Snake game on HTML and JS”.
Модель занимает одну видеокарту:

Скорость отклика 110 токенов/сек, на конфигурации с двумя 4090 - 65 токенов/сек. Время отклика 18 и 34 секунды соответственно.
DeepSeek R14 70B
Ее мы тестировал при размере контекста 32K токенов. Эта модель уже занимает 64 Гб видеопамяти и, следовательно, не влезла в 48 гигабайт видеопамяти 2x4090. На двух 5090 это можно сделать даже с приличным размером контекста.

Если же использовать контекст в 8K, то утилизация видеопамяти будет еще меньше.
Тест проводили при 32K контекста и таком же промте “Write code for simple Snake game on HTML and JS”. Скорость отклика в среднем 26 токенов в секунду, запрос обрабатывается в районе 50-60 секунд.
Если уменьшить размер контекста до 16K и, например, взять промт “Write Tetris on HTML” мы получим утилизация 49 Гб видеопамяти на обеих видеокартах

Но скорость отклика будет такой же 26 токенов в секунду, как и время отклика в районе 1 минуты. Следовательно размер контекста влияет только на утилизацию видеопамяти.
Генерация графики
Далее тестируем генерацию графики в ComfyUI. Используем модель Stable Diffusion 3.5 Large в разрешении 1024x1024.
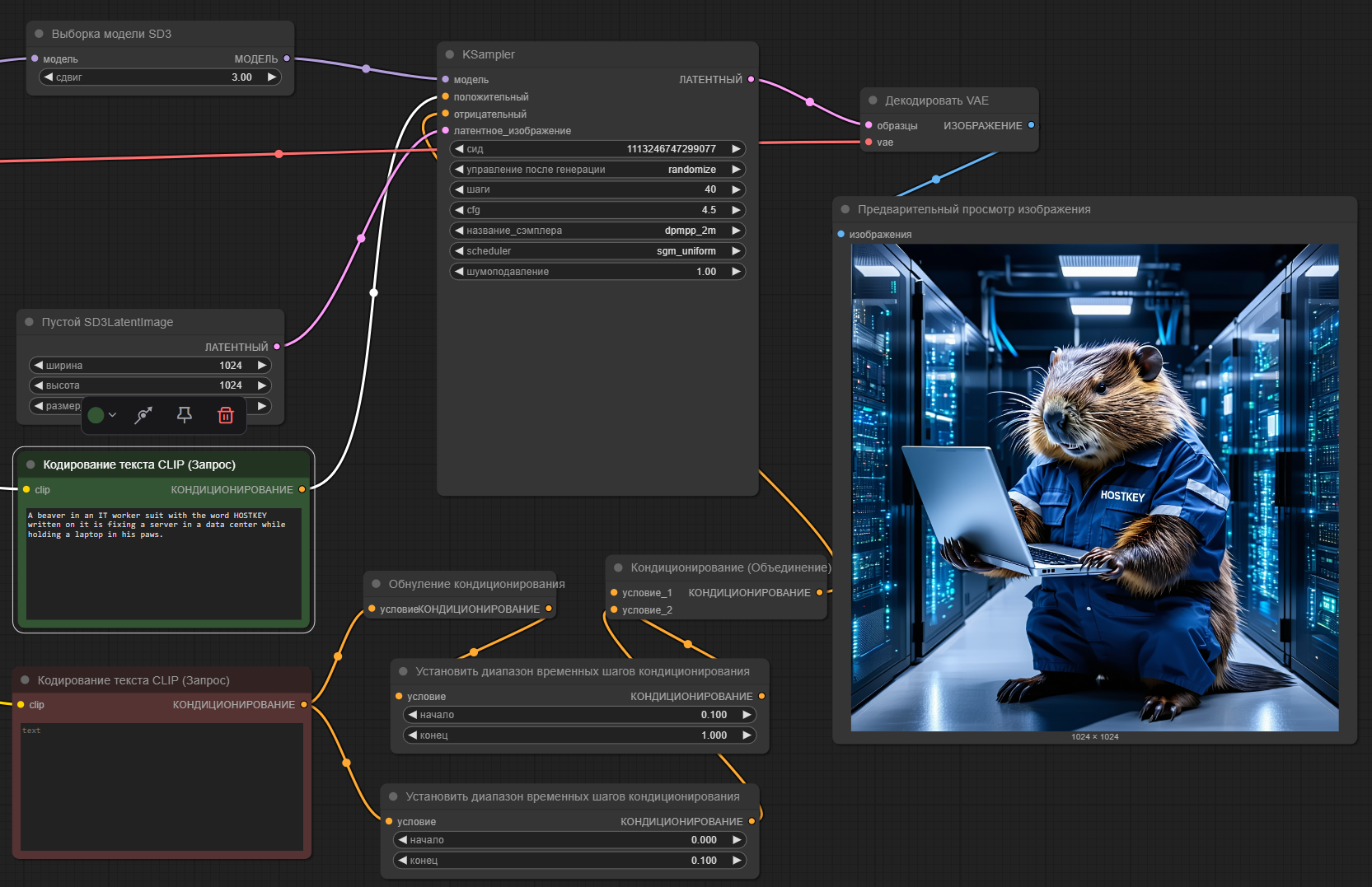
В среднем видеокарта на данной модели тратит 15 секунд на изображение при утилизации 22.5 гигабайт видеопамяти на одной видеокарте. На 4090 при тех же параметрах затрачивается 22 секунды.

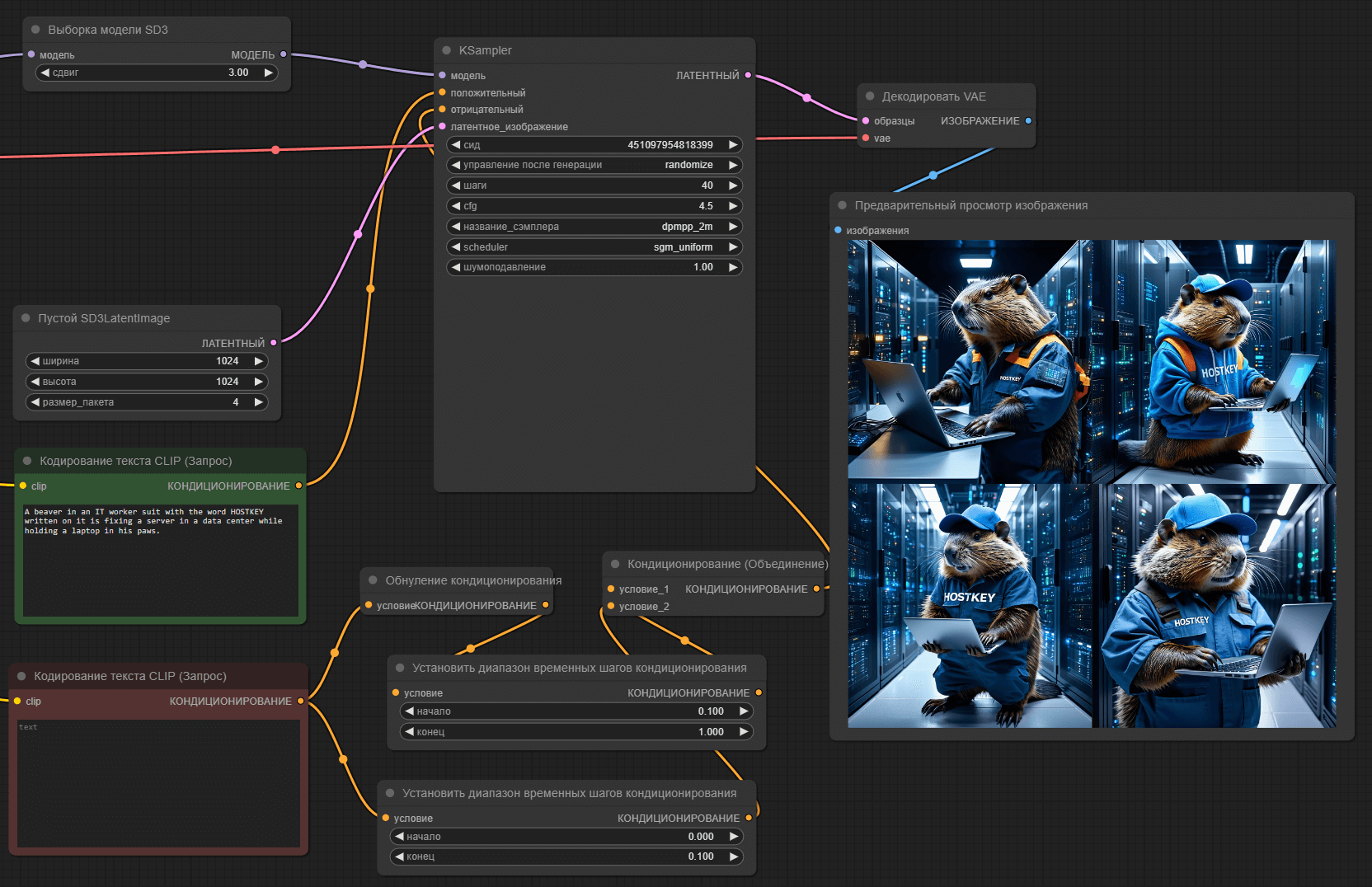
Если задать генерацию в batch режиме (1024x1024 4 штуки), то суммарно у нас потратилось 60 секунд, так как ComfyUI, но работа не распараллеливается, но видеопамяти утилизирует уже больше.

Подводим итоги
Конфигурация из двух видеокарт NVIDIA RTX 5090 отлично себя показывает в задачах, где необходим большой объем видеопамяти, а программное обеспечение может распараллеливать задачи и утилизировать несколько GPU. По скоростям связка из двух 5090 также быстре 4090 и в некоторых задачах (например, в инференсе) может дать прирост до двух раз из-за более быстрой видеопамяти и скоростям работы тензорных блоков. Но за это приходится платить энергопотреблением и тем, что не всякая конфигурация сервера “потянет” связку даже из двух 5090. Ставить больше? Скорее всего нет, так как там правят бал уже специализированные GPU типа A100/H100.