
Sharpness-aware training for free: счастье для всех и почти даром
Начнем с популярной рубрики «ни выпуска без лайфхаков в обучении нейросетей» и рассмотрим метод из семейства SAM (sharpness-aware minimization) для нахождения соответствующих широкому минимуму функции потерь параметров.
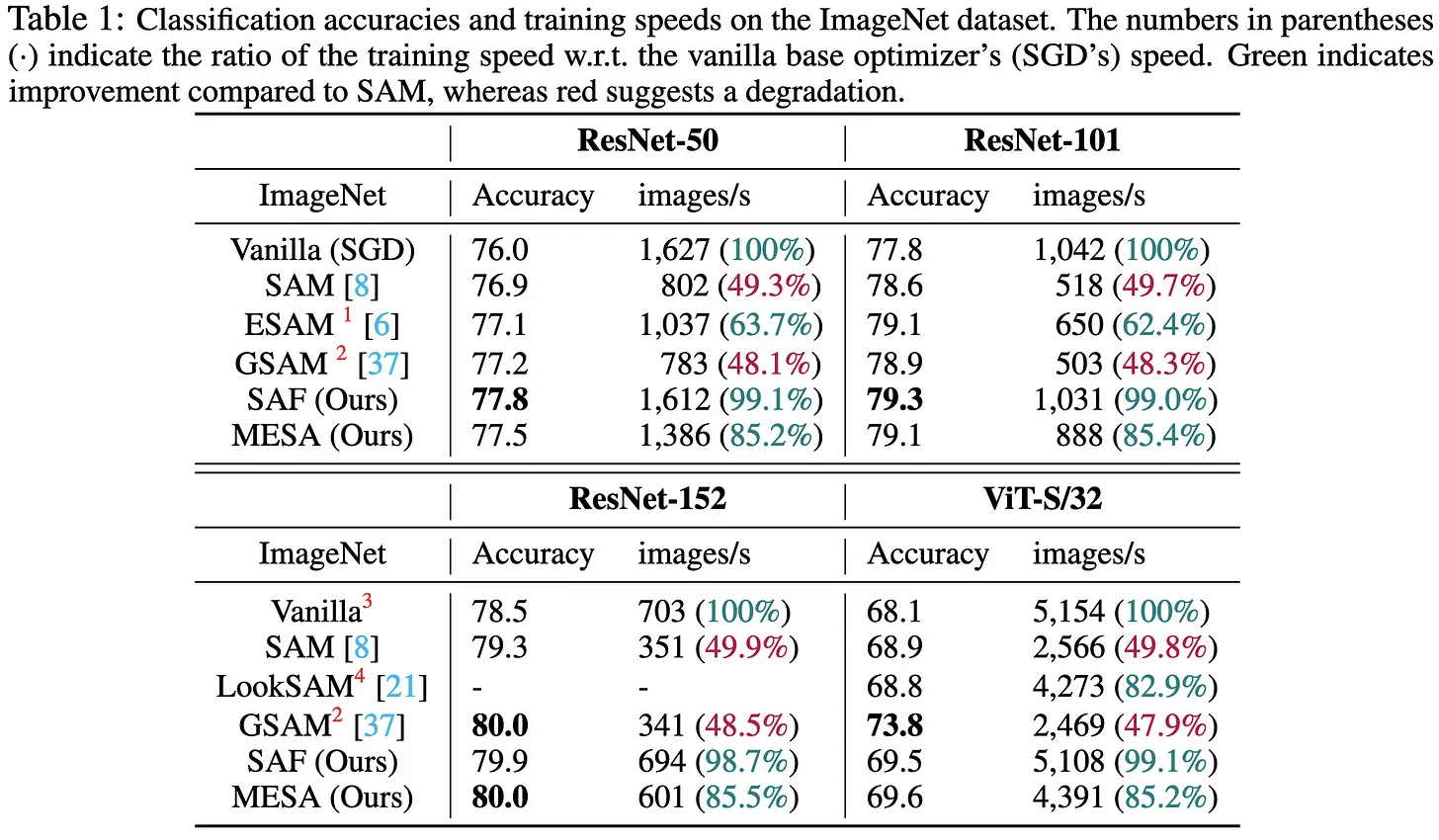
Авторы предложили алгоритм, который требует гораздо меньшего по сравнению с другими количества ресурсов, но дает хорошие результаты. Нужно на протяжении всего обучения хранить предсказанные вероятности классов для всех обучающих примеров, а в качестве регуляризации функции потерь брать KL-дивергенцию распределений вероятностей между текущими предсказаниями и старыми.

Объем хранящейся информации линейно зависит от размера датасета и количества эпох обучения: для некоторых задач (сегментация, языковые модели) это может оказаться слишком затратным, поэтому был предложен легковесный вариант MESA. Он требует хранения только скользящего среднего старых предсказаний, а KL-дивергенция считается между обновленным и необновленным скользящими средними. Затраты для imagenet после оптимизации составляют 98 МБ против 14643 МБ в исходном варианте.
CogVideo и NUWA-infinity: время первых (моделей text-to-video)
Если хотите увидеть пьющего из стакана льва или пингвинов, проверяющих диван из IKEA, — а может, и <более смелую эротическую фантазию>, то вам сюда. Следующим шагом в развитии популярных у сетевой аудитории моделей text-to-image стало появление способных генерировать короткие видеоролики моделей text-to-video.


Относительно свежие значимые работы серьезно превосходят созданные ранее (VideoGPT, MoCoGAN-HD, digan) в качестве и устойчивости генерации во времени. Увы, из-за архитектурных особенностей они обладают существенным недостатком: сильной привязкой к конкретному домену/теме (пейзаж, лицо, pov человека на велосипеде).


Видеогенератор StyleGAN-V базируется на StyleGAN2 — нейросети, способной создавать реалистичные фотографии людей и не только. Без дополнительных ухищрений она хорошо обучается на достаточно однородных изображениях, имеющих одинаковую структуру. При этом к константе, из которой путем подмешивания задающего отличительные особенности шума генерируется изображение, добавляется еще один набор чисел: motion code. Он использует ациклические эмбеддинги (традиционные циклические эмбеддинги приводили бы к зацикливанию видео) и задает положение на временной шкале.
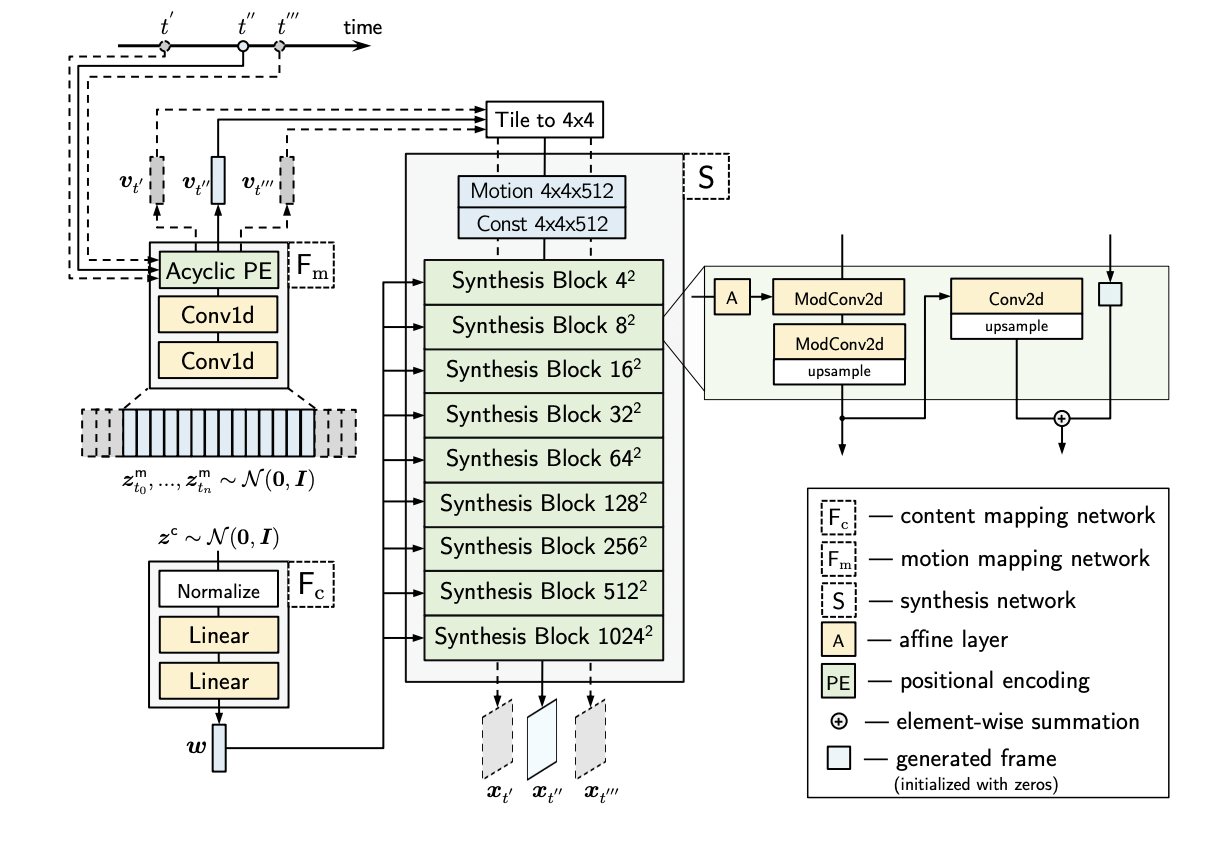
Вторая разработка использует нейросеть StyleGAN3, не имеющую привязки конкретных частей структуры (например, глаз человека) к расположению на изображении (этим страдала вторая версия). Обучение проходит в два этапа: сначала сеть учат генерировать кадры в низком разрешении, а затем разрешение повышается. Для кодирования временной зависимости используется отдельный шум, который пробрасывается в модифицированные блоки генерации кадров.
Первой такой архитектурой стала CogVideo, которая использует рассмотренную в одном из предыдущих обзоров модель Cogview2 (а точнее, Coglm). Глядя на более ранние работы NUWA и Godiva, ее создатели поняли, что лучшие результаты дают авторегрессивные трансформеры: нейросетевые архитектуры, использующие механизм внимания и генерирующие изображения по аналогии с языковыми моделями токен за токеном (т. е. часть за частью).
Есть и ограничение: иногда генерируемое видео содержит множество отсутствующих в текстовом запросе деталей. Авторегрессионные модели могут генерировать действие «говорить» по первому содержащему губы кадру, но для создания ролика «лев пьет воду из стакана» нейросеть должна генерировать промежуточные концепты: «лев подносит стакан к губам», «пьет» и «ставит стакан на стол». Вдобавок, существующие наборы данных либо слишком маленькие (в самом большом аннотированном датасете VATEX всего 41 тысяча роликов), либо не очень релевантные и содержат лишь описания сцен без привязки к изменениям во времени.
Еще одним ограничением стала разная продолжительность роликов: длинное видео с общим описанием «пить воду» может содержать такие действия, как «держит стакан», «поднимает стакан», «пьет» и «опускает стакан». Модели будет очень сложно понять, что из этого есть «питье воды из стакана».
Cogvideo объединяет текст и представленные токенами изображения в единую последовательность, по которой трансформером предсказывает кодирующие части изображений новые токены. Изображения переводятся в токены через отдельный энкодер VQVAE, а также токенизируется и добавляется к последовательности frame rate — частота, с которой берутся кадры в момент обучения. Обучение проходит в 2 этапа: на основе текста и frame rate последовательно предсказываются 5 кадров, а затем частота увеличивается и предсказываются промежуточные кадры. Сначала нейросеть учится генерировать общую структуру видео, а затем учится ее уточнять.
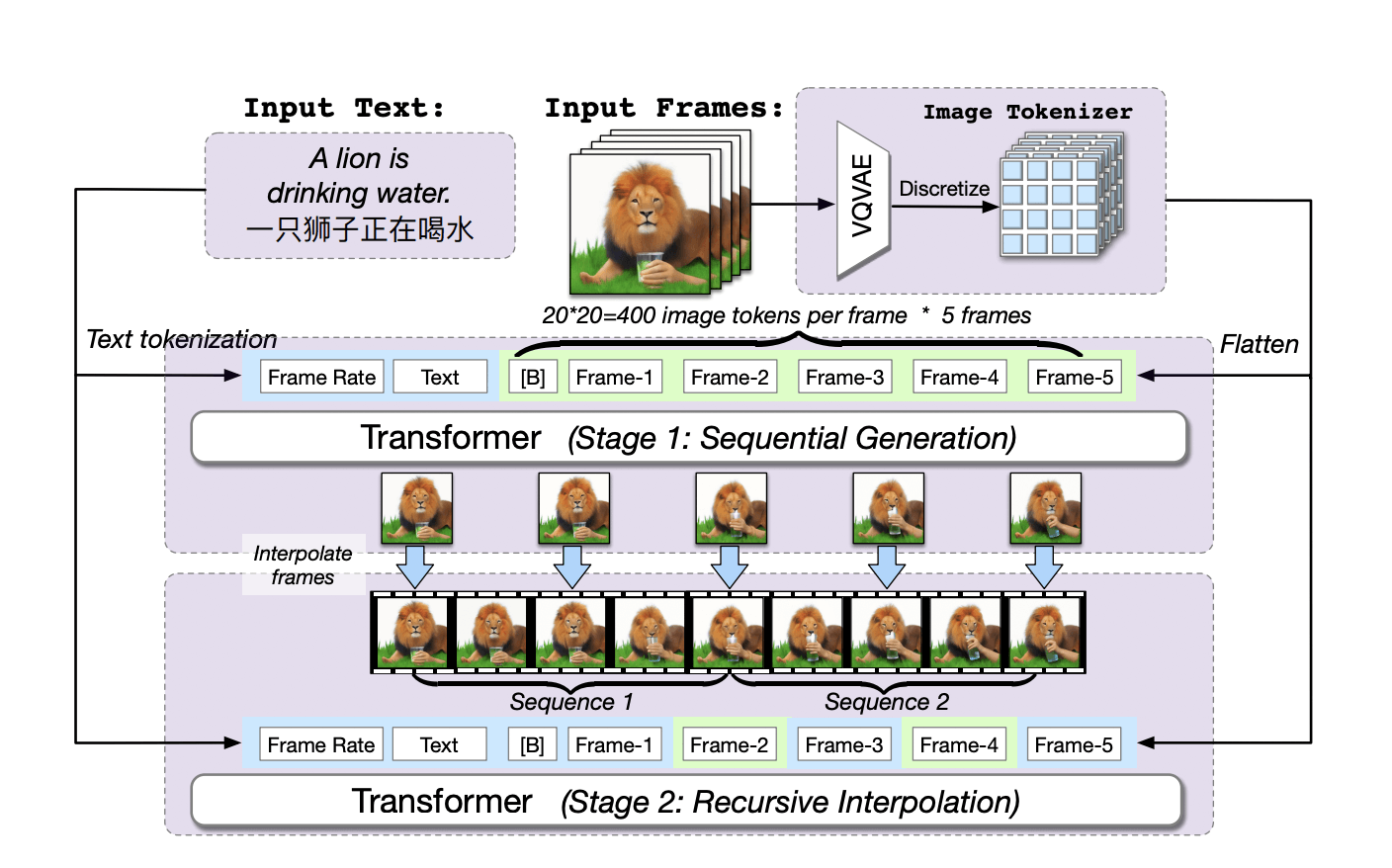
Чтобы использовать Coglm для интерполяции кадров, авторы вводят механизм внимания dual-channel attention, который добавляется к стандартному attention в предобученной Coglm. Это позволяет модели при генерации токенов «подсматривать» во все известные фреймы. Веса модели замораживаются, обучается только эта добавочная часть.
Проблему недостатка данных исследователи пытаются компенсировать, обучив модель на собственном наборе (5,4 миллиона роликов с описаниями). Модель учится генерировать видео с разрешением 160x160, которое потом можно увеличить до 480x480 при помощи Cogview2. Нейросеть получилась прожорливая: вы можете протестировать ее сами. Результат далек от идеала, но как первый шаг выглядит достойно.


Еще одну попытку переосмыслить авторегрессионную генерацию трансформерами предприняли создатели NUWA-Infinity из Microsoft. Эта модель обучалась решать сразу много задач: помимо генерации видео она умеет создавать изображение по тексту, анимировать его и дорисовывать по краям (при этом разрешение не фиксировано и может достигать мегапикселей).
Авторы разработки предложили авторегрессию поверх авторегрессии (autoregressive over autoregressive). Сначала локально для генерации конкретного кадра мы генерируем патч за патчем (изображения кодируются в токены и декодируются опять же через VQVAE), а затем на основе предыдущих и связей между ними глобально генерируется кадр за кадром. Связи задаются отдельными механизмами, которые определяют, будут кадры формировать видео или расширять изображение.
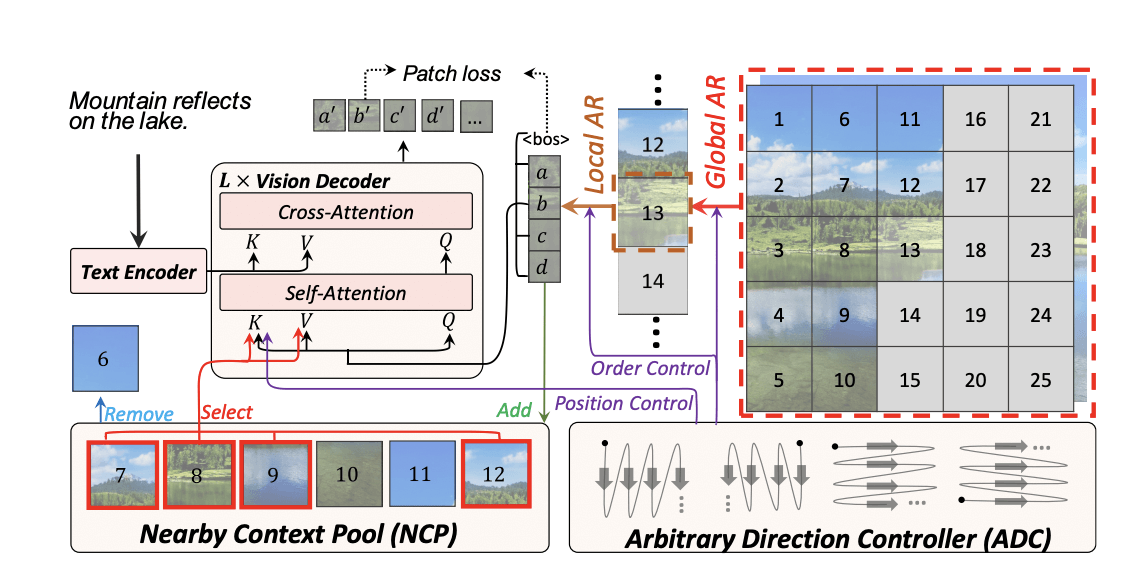
Блок Arbitrary Direction Controller позволяет учесть пространственные и временные зависимости: на основании порядка генерации внутри кадра и порядка кадров он дает нужные позиционные эмбеддинги. Последние добавляются к уже сгенерированным патчам для учета всех контекстуально значимых патчей при генерации новых. Блок Nearby Context Pool кэширует патчи, добавляя актуальные и удаляя устаревшие, что позволяет модели сохранять глобальный контекст (это особенно важно при генерации длинных видео). Для улучшения качества декодирования текущего кадра и сохранения согласованности между кадрами применяется архитектура Pixel-Guided VQGAN (PG-VQGAN), который использует предыдущий кадр.
Авторы обучали модель на четырех собственных датасетах, что затрудняет сравнение с конкурентами, однако качество примеров впечатляет. К сожалению, код даже прошлогодней модели NUWA недоступен, поэтому протестировать новинку самостоятельно не получится.


Последняя в этом обзоре модель представляет собой расширение диффузионной модели GLIDE на случай генерации видео. Для изображений использовался обычный двухмерный Unet, но сейчас авторы перешли на трехмерный. В нем 2d-свертки 3x3 заменили на специфические свертки 1x3x3, а механизм внимания модифицировали до factorized space-time attention: сначала идет считающее близость фич в разных пространственных положениях стандартное внимание, а затем temporal attention block, который считает близость фич между разными кадрами.
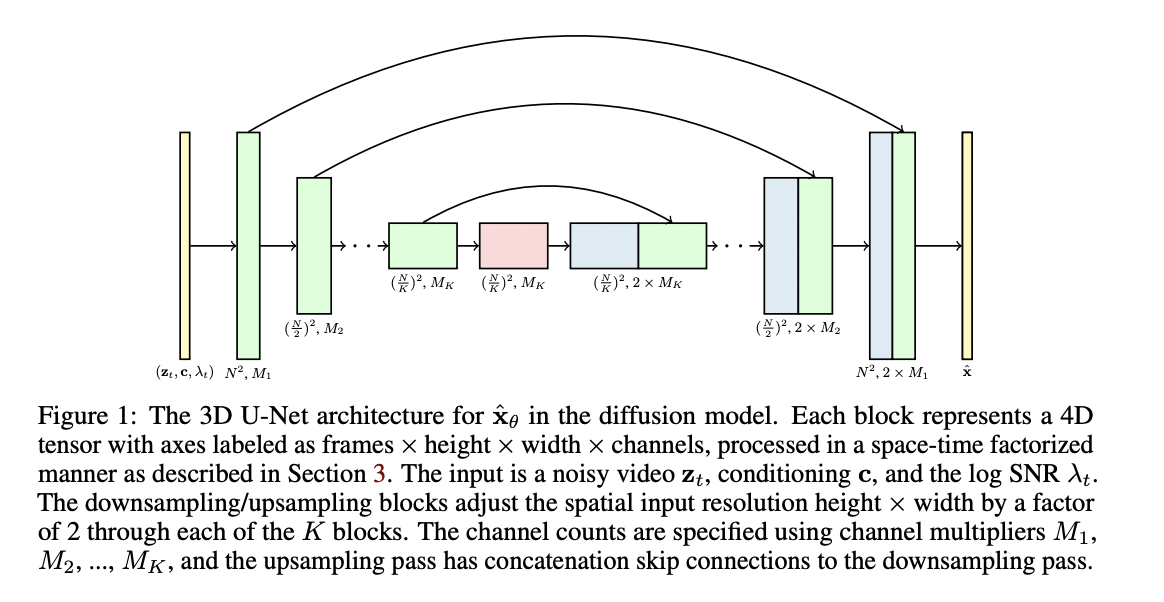
Чтобы не контролировать соответствие генерируемых кадров запросу через отдельную модель (как CLIP в DALL-E), которую нужно предварительно обучить (потратившись на разметку данных), авторы используют механизм classifier-free guidance (опять же из GLIDE). Ему не нужен явный классификатор изображений, но при обучении модели функция потерь минимизируется с учетом или без учета текстового условия. Также в процессе обучения к последовательным кадрам периодически добавлялись произвольные из датасета: аттеншн в таком случае маскировался, чтобы эти видео не попадали к последовательным кадрам.
Для получения эмбеддингов текстов использовалась модель BERT-large, а сама генеративная модель обучалась на 10 миллионах наборах пар текст-изображение. Пока она может создавать только 16 кадров в разрешении 64x64, но результаты получаются релевантными, и в сочетании с хорошим диффузионным апскейлером (как в DALLE2) это позволит вывести генерацию видео на новый уровень.


AI и углеродный след
У больших нейросетевых моделей есть оборотная сторона: их обучение энергозатратно, что увеличивает т. н. углеродный след. В совместной работе исследователей из Microsoft и некоторых университетов этот вопрос внимательно изучался, и в итоге были сформированы рекомендации по снижению выброса углекислого газа при обучении моделей.
Правильный выбор времени и места может снизить эмиссию CO2 более чем вдвое:
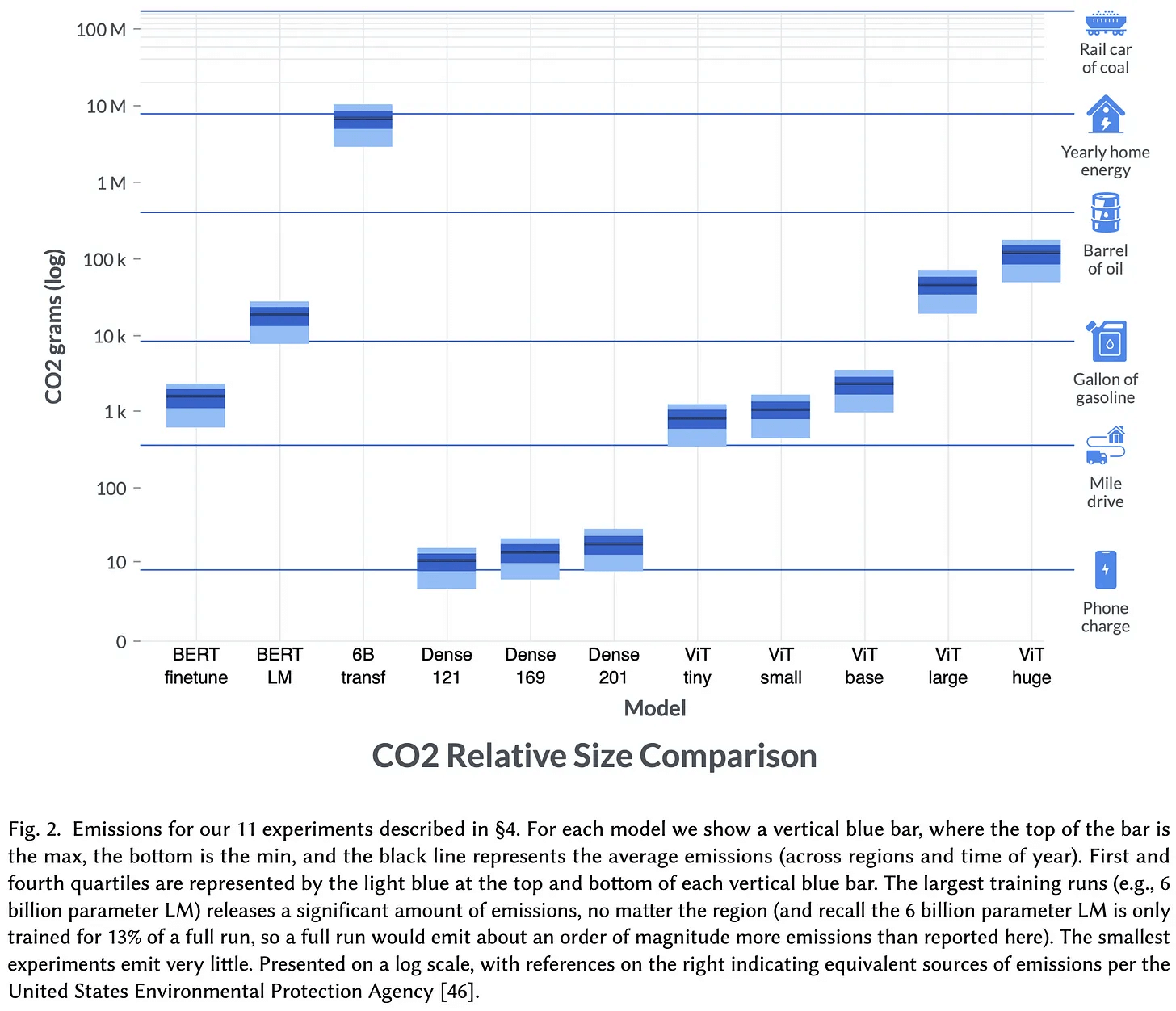
К примеру, обучение распространенной языковой модели BERT в датацентрах центральной части США приводит к выбросу 22-28 CO2-эквивалента. Это более чем в два раза превышает выбросы от того же эксперимента в активно использующей гидроэлектростанции Норвегии, или во Франции, которая в основном полагается на ядерную энергию. Время суток также имеет значение: например, обучение в Вашингтоне в ночное время, когда электричество поступает только от ГЭС, привело к снижению выбросов по сравнению с обучением днем, когда активно используются газотурбинные станции.
Даже запуск не в часы пиковой нагрузки (например, ночью) с паузами в часы пик может привести к сокращению выбросов на 80%.
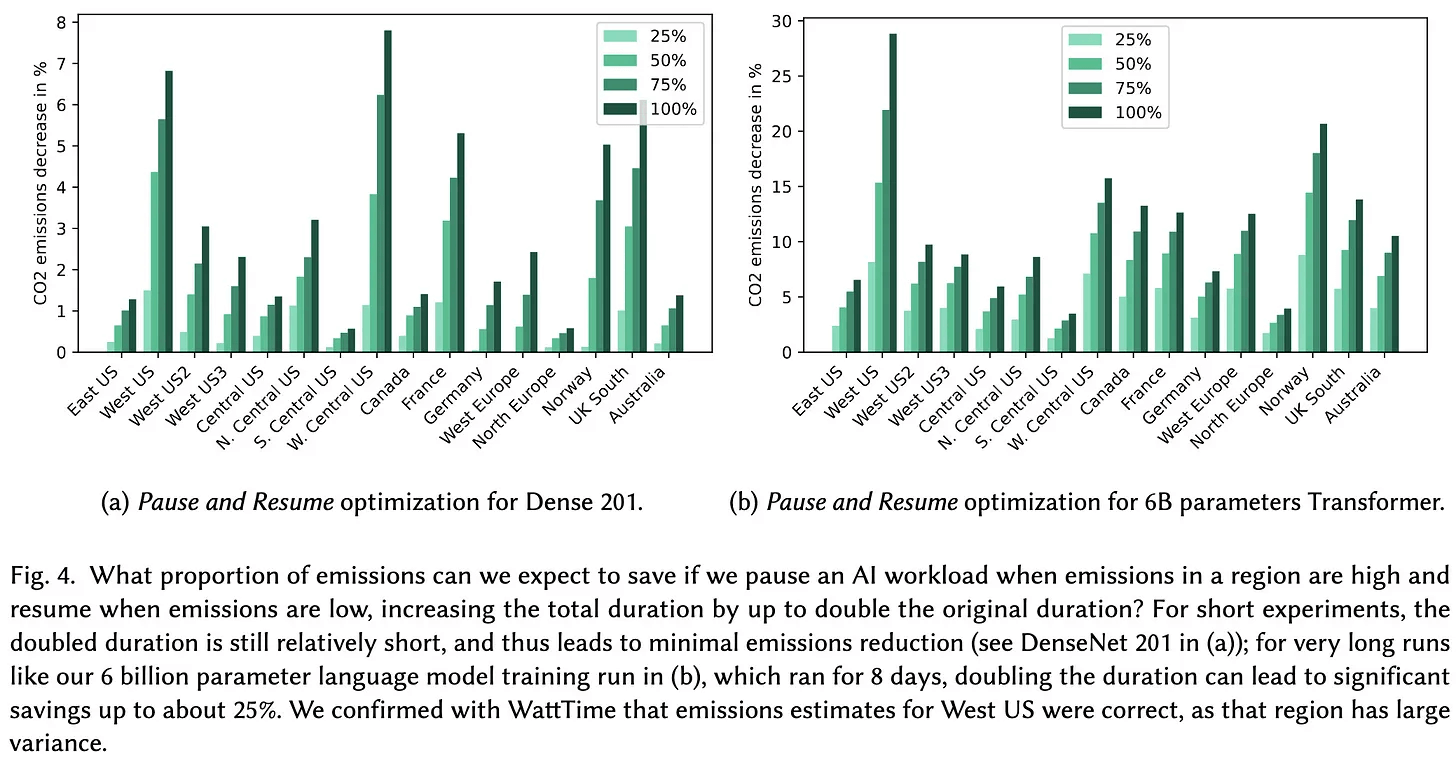
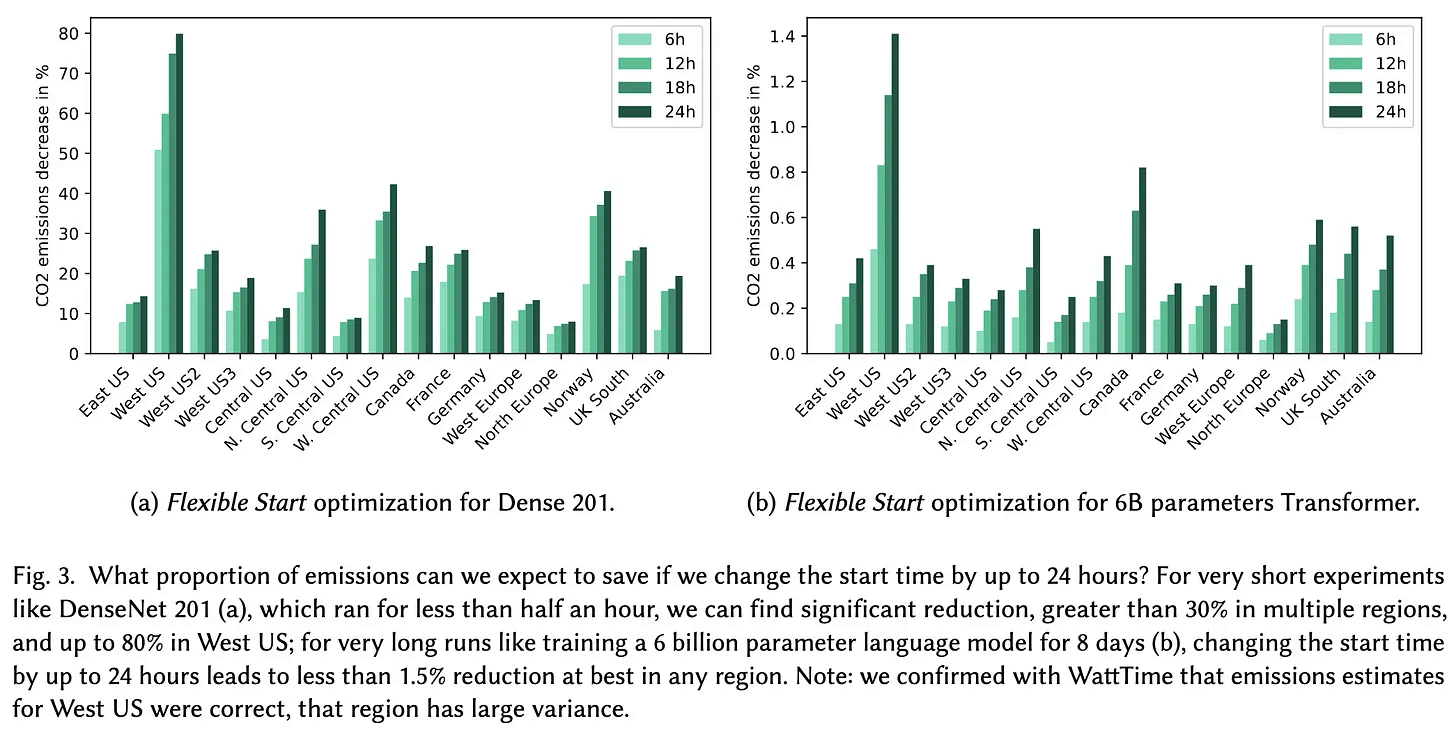
Сейчас много говорят о неуместной трате ресурсов на непрекращающееся обучение нейросетевых моделей, а также о постоянном росте количества их параметров и вычислительной сложности. Некоторые даже считают, что практически единственный прогресс в области AI — осознание потребности в как можно более тяжелых моделях. При этом не стоит забывать, что перевозка грузов на большие расстояния, горнодобывающая промышленность, а также производство бетона и алюминия приводят к колоссальным выбросам CO2, но редко подвергаются серьезному общественному контролю. Вместе с тем остается надежда, что исследователи сподвигнут больше людей хотя бы задуматься над проблемой.
Другие статьи цикла:
- Новинки deep learning. Часть 1: PolyLoss, Imagen, Cogview2 и CoCa
- Новинки deep learning. Часть 2: Trusted Media Challenge, HeSeR и Tortoise-tts